SEOの過去・現在・未来、そして心得
こんにちは、羽山です。
ふと過去に執筆した記事を振り返ったのですが、フロントエンドのパフォーマンスの話・bashのプロセス置換・Androidアプリのパフォーマンス・DoS攻撃対策などなど、記事の方向性が毎回バラバラすぎて自分は何の専門なんだろう?と疑問に思えてきました。
まあそれは気にしないとして、今回もご多分に漏れず今までの記事とは全く異なる領域の話です。
話のベースはSEOについてですが、 心得 とか 考え方 のような話題が中心です。前半は歴史の振り返りから将来の動きなどを考えて、後半は弊社で運営してきたサイトで培ったノウハウからSEO施策の考え方と少しだけ具体的な施策を紹介します。
想定している読者像は、「これからSEO対策をやろうと思う人」から「すでにSEO対策をバリバリやっている人」まで、どなたでも多少なりとも参考にしていただける部分があるのではと思います。
まずは歴史・経験・経緯の話
愚者は経験に学び、賢者は歴史に学ぶ というわけで、まずは90年代以降のウェブ及びSEOを巡る各プレイヤーの動きを振り返ってみましょう。
90年代から2000年代初頭
このころのウェブはまだ素朴で個人がなんら収益を求めずサイト運営するケースが大半でした。まともなウェブサイトというのは定まっておらず何ら目的もなく運営されているサイトも多かったのですが、不思議とその中の1コンテンツとしてお気に入りサイトへのリンク集が定番としてありました。
そんな折りに生まれたのがGoogleで、サイトから貼られたリンクを評価したページランクという指標により優劣をつけるという画期的な手法で市場を席巻しました。価値を持ったサイトでなければリンクを集められないので当時のウェブの状況と親和性の高い評価方法であり、実際にGoogleの提供してくれた検索結果は他の検索エンジンと比べて抜きん出ていました。
2000年代
SEOが全盛となったのがこの頃ではないでしょうか。検索エンジンからの流入を得たいと考えるサイト運営者は頑張って様々な対策していた時代です。当時はまだ検索エンジンのアルゴリズムが単純だったことから、SEOのためだけの施策を実施することで如実な効果が出ました。
中でも影響が大きかったのはSEO業者に依頼して自サイト対して大量のリンクをはってもらう施策で、これは囚人のジレンマ(各人がそれぞれ合理的に判断した結果、全員が最大の利益を得られない)の状況を引き起こしました。SEOとは相対的なもので競合サイトが被リンク購入で順位を伸ばすと自サイトは下落します。そこで望まざるとも自サイトでも実施せざるを得なくなり、SEOの効果としては打ち消し合ってイーブンになり、リンクの購入費用だけかかり続けるというSEO暗黒時代の様相でした。
だれも被リンクを購入しなければ全員がハッピーだったはずなのに、(SEO業者を除いた)関係者全員が少しずつ損をする状況になってしまいました。
善意でリンクをする文化の衰退
当時雨後の竹の子のごとくあった個人サイトは徐々に形を変えブログという形に昇華しましたが、その過程で お気に入りサイトへリンクをする という文化は失われていきました。
例えば現在の感覚で特定の商品・サービスの紹介をしているウェブページを見るとアフィリエイトという印象を受けるように、純粋な善意でリンクをするという感覚が薄れてきているのです。
そんな現代でもSNSのシェアはアフィリエイトの印象が軽減しますがその分ステマの印象も若干あったり、SNS内のコンテンツはクローラーが到達しにくい性質のものであったり、SNSでバズったものがコンテンツとして価値が高いと評価して良いのかは微妙なところです。
そういったリンクへの感覚の変化とSEO業者による被リンク稼ぎの合わせ技で、現代においては被リンクを評価するという手法自体が徐々に合わなくなってきているのです。
これはSEO業者だけが悪いという話ではなくリンクを評価するというアルゴリズムが誕生した以上、必然的に起こるべくして起こったことです。
Googleの動き
ではGoogleはどう動いたかというと、時代の流れにうまく対応していきます。
当初のGoogleは各ページの被リンクの数と質、あとはウェブページに含まれる単語の一覧だけで他の検索エンジンを圧倒できるだけのサービスを提供できていたのです。規模こそ莫大なものの仕組み自体は単純な方法でページの価値を決定することができました。
しかし前節の流れの通り徐々にリンクを評価する仕組みが品質を正しく反映できなくなってくると、Googleはウェブページに書かれた内容を理解する努力を始めました。チーズはどこへ消えた?のように、かつてのコアコンピタンスに固執することなく変化に対応したと言えば伝わる人には伝わるでしょうか。
その視線の先には
SEOの語る上では無視できない巨人であるGoogleですが、その視線の先に何があるのかは好むと好まざるとにかかわらず、いずれ我々の身に降りかかってきます。その意味でGoogleが目指す方向性を想定しておくことは重要です。
例えば専門分野について知識がある人間はその分野のウェブページに書かれた情報を理解して真偽や質などを判断することができます。それをあらゆる分野で行えるとしたら、世の中のすべての事象を把握した存在が任意の質問に答えてくれるとしたら・・・?
ラプラスの悪魔が近い概念かもしれませんが、人間がそういった存在になるには記憶容量的にも寿命的にも無理があります。しかしコンピュータシステムならば、容量と寿命の問題はクリアできるのです。現時点ではクローラーは人間と同等にウェブページを理解することができませんが、あとはいくつか足りないピースが埋まれば全知全能のような存在が夢とは言えなくなってくるかもしれません。
SEOでは未来の予測が必要
なぜSEOの話をしているのに歴史の話から始まるのかというと、各プレイヤーの思惑を知り、未来を予測するためです。
SEO対策には時系列の考慮が不可欠です。実施するSEO施策がすでに時代遅れならばやる価値がないですし、検索エンジンが目指す方向にあわせたSEO施策なら検索エンジンのアルゴリズム変更におびえる日々を過ごす必要はなくなります。
例えば クローラビリティを高めるためにサーバーサイドレンダリングに変更 という施策を考えてみると、今はクローラーがJavaScriptを実行できてレンダリング性能もChrome同等になっているのでSEOを目的として実施する必要性は低くなっています。しかしこれが10年前ならやるべきでしょう。このようにSEO施策は時間経過で優先度が変わる場合が多々あります。
検索エンジンが目指す方向性
では検索エンジンが目指す方向性に合わせた施策というのは何でしょうか?
その答えの一つは 良質なコンテンツを提供する というシンプルな施策です。あなたの運営するウェブサイトが何らかの価値を提供した上で人々がその価値を感じ取れるならば、検索エンジンは人々が感じ取った価値に応じた評価を付けてくれます。
これは過去・現代・未来で一貫して検索エンジンが目指していることですが、その時代によって実現方法が変化しています。
前述の通り過去では閲覧者がウェブページを評価した結果がリンクという形で現れると仮定してウェブページの価値を決めていました。しかし 1.検索以外の方法でウェブページが露出する、 2.気に入ってくれた人がページに対してリンクする、 3.検索エンジンが評価する という順番となり、いわば 卵が先か?鶏が先か? で、検索エンジンに評価をもらうためにはまずは何らかの方法で露出が必須でした。
そして将来は徐々にクローラー自体がページの価値を解釈する幅が増えていくと考えられますが、かといって運営実績の短いサイトに記事をアップしたらその瞬間にクローラーがやってきてページの適切な価値を判断、そして人々にページを配信してくれるかといえば、それはしばらくは夢物語でしょう。
情報の価値と評価
「次回の凱旋門賞の優勝馬は○○だ!」と書かれたウェブページが価値のある情報であるかどうかは凱旋門賞の結果が出てみないとわからないように、情報の正しさは評価できる場合とできない場合があるのです。それはつまりウェブページの価値を真に決定することは容易ではないということを示します。
将来AI技術が発展した結果、あらゆる情報を分析してほぼ確実に凱旋門賞の優勝馬を予測できるようになっているかもしれません。そうなればクローラーはウェブページに書かれた内容が正しいのか判断することができます。
しかしその場合は優勝馬を予測したウェブページは価値を持つのかというと残念ながらそうはなりません、なぜならその時代では凱旋門賞自体が今の形では存続し得なくなるからです。もともと競馬は予測不可能性を前提に成り立っているので、その前提条件が崩れてしまうとその情報の価値自体が無くなってしまうのです。
情報の価値・ルールは変わっていく
究極的には 良質なコンテンツを提供する ことが答えですが、その良質なコンテンツ自体も時間経過で変化し、基本的には古くなればなるほど価値が減少していきます。
凱旋門賞の例ではレース直後は優勝馬に関する情報の価値は高いですが、1週間経つとほとんどゼロに近くなるでしょう。
一方で過去の凱旋門賞のレース結果の分析を行って考察した情報ならば、来年以降も有用な情報となり得るので価値の減少スピードは低くなります。
このようにSEO対策はある一時点の点で考えるのではなく、現在から予測した未来への範囲(線)で考えましょう。そうすることで持続的な効果を得ることができます。
E-A-Tについて考える
2019年のGoogleの品質評価ガイドラインでは E-A-T(Expertise-専門性, Authoritativeness-権威性, Trustworthiness-信頼性) というキーワードが提唱されています。
被リンク評価という絶対的存在であった手法からの移行先のひとつで、執筆者やサイトの専門性を評価指標に加味しているのです。
このガイドラインの本質を考えるとクローラーがまだ完璧ではないことを表していて、クローラーからの目線では「書かれている情報の真偽や価値は分からないけど、この人の書いた記事なら正しいだろう」という判断基準で評価するということです。クローラーがウェブページの価値を絶対評価できる未来からは寄り道な気もしますが、実際の人間も相手によって信用度を変化させて受け止めるので人間的な評価に近く、これはこれで進化の方向として正しいように思えます。
またここで重要なのは 検索した人の検索の意図 を把握して、それぞれの専門性(Expertise)ごとに細分化されて評価される点です。
例えば凱旋門賞のレース直後に「凱旋門賞」と検索したらレース結果を速報で知りたいという意図を理解して、報道の専門性を持つサイトがより上位に評価されるでしょうし、同じ「凱旋門賞」というワードでもレースと関係ない時期に検索したら、「凱旋門賞とは何か?」という側面で百科事典的な専門性を持つサイトや公式サイトが上位に表示されやすいでしょう。
結局E-A-Tでも良質なコンテンツを継続的に提供し続けることが答えになりますが、その上では専門性を高めていくことが重要です。
Googleの検索アルゴリズムは戦う相手でない
Googleのアルゴリズムが変化して順位が下がったという話題は定期的に出てきます。これは短期的な上下は多少あれど本質的には検索エンジンの目指す方向とそぐわないウェブサイトであると考えられます。Googleのアルゴリズムは決して騙したり、戦ったりする相手ではないと考えて、 良いコンテンツを提供したらきっと評価してくれるはず と信じることがSEOにおいての大切な心構えです。
E-A-Tの前に話題となったYMYL(Your Money or Your Life)はGoogleがページ品質を重視する流れの一環でお金や生活に関連する重要ジャンルからてこ入れを始めたものです。当時は流入が減少したというウェブサイトが目立ちましたが、ページ品質に力を入れて良いコンテンツを提供していたサイトは相対的に順位が上昇しているのです。そしてYMYLという言葉はそのうち無意味になり、あらゆるジャンルでページ品質が重視されるようになるでしょう。
ウェブページの価値の評価とその先
ラプラスの悪魔と凱旋門賞の優勝馬の話はまだ遠い未来ですが、これは検索エンジンの目指す方向性の話なので簡単な事象の答えならば、すでに検索エンジンは把握し始めています。
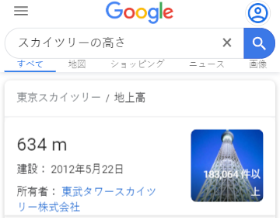
例えば「スカイツリーの高さ」と入力してGoogleで検索すると「634m」という、答えそのものが検索結果に出てくることを確認できるでしょう。
ウェブページの価値を評価するにあたっては、そのページに書かれていることが正しいのかを検索エンジン側は把握しておく必要があります。
「スカイツリーの高さは634m(武蔵国)である」と書かれているウェブページと「810m(江戸)である」と書かれているウェブページがあった場合に検索エンジンとしては前者のウェブサイトを評価するように進化していく必要があります。
ただ、ここで1つ疑問が出てきます。検索エンジン自体が質問に対する答えを持ち始めたら、果たしてその先のサイトにわざわざ検索した人を誘導する必要があるのでしょうか?
スカイツリーの高さ問題がこの疑問の答えであり、今までならばスカイツリーの公式サイトの解説ページがヒットして検索した人はそこに訪れて答えを得ていました。ウェブサイト側としてはさらに興味のありそうな次の情報に誘導するなどが可能でした。
しかし検索エンジンの進化の結果クローラーが真にウェブページの価値を評価できるようになれば、正しいことが書かれているウェブページを正当に評価することができますが、それと同時にそのウェブページの存在意義の大半は失われて、 クローラーが訪れた最初の1回目に情報を1度渡す だけの存在になってしまうのです。
良質なコンテンツを提供することがSEOにおいて最善としていましたが、その先では検索エンジンが 勉強 するための資料をインターネット上にアップロードしているだけになります。検索エンジンからみたらインターネットそのものが巨大な情報源データベースという扱いとなり、検索エンジンの検索ボックスであったものは オムニボックス のような性質のものに変化していくでしょう。
これは架空の話ではなく、今現在実際の起き始めていることです。
検索エンジンにデータを提供する時代
検索エンジンが物事を学ぶようになった場合にウェブサイト側はどのように行動すれば良いのでしょうか?
その答えのひとつと思われる事例はすでにあります。
Googleで「東京 天気」と検索すると検索結果には本日の東京の天気予報そのものが出てきますが、これは天気予報を行っている企業が予報結果のデータを提供しているのです。
クローラーとはウェブページに書かれた情報を分析してデータ化するものですが、この場合はもはや人間が読みやすいウェブページという体裁をとる必要がなく直接プログラムが理解しやすいデータ構造で情報を渡せばいいのです。
天気予報を行う企業としてはユーザーを囲い込めなくなるのはデメリットですが、情報提供で対価を受け取り本業である天気予報に集中することができる点ではメリットもあります。
こういった形でのデータ提供は大手企業で独自データを保持していないとできないのでは?と思われるでしょうか。実はそんなことはなく個人が検索エンジンにデータを提供する仕組みはすでに広く使われています。
構造化データ
その1つが構造化データです。構造化データはウェブページの目的ごとに決められたデータ形式のデータをHTMLの中に埋め込んでおくもので、クローラーがウェブページに書かれた内容を理解する補助が可能です。
前述の天気予報データの提供と異なる点は、情報提供に対して直接の対価を受け取れない点で、そこはサイト運営者にとってデメリットにも感じてしまうかもしれません。
しかし例えば情報を取り扱うウェブページに構造化データを追加すればクローラーがそのページの価値を理解しやすくなり、そして検索結果に表示されやすくなればサイト運営者にとって良いことです。またGoogle for Jobsによる求人検索のようにページ来訪が目的ではなく情報自体を拡散することに目的がある場合もWin-Winとなります。
このように現在は検索エンジンとサイト運営者がWin-Winの関係となる範囲で活用されていますが、将来的に検索エンジンの学習データとしての活用が増えてきたらどうなるかは注目ポイントです。
AMP(Accelerated Mobile Pages)
そのほかの例ではAMP(Accelerated Mobile Pages)もデータ提供に該当します。AMPはその名称からページの高速化手法のように扱われていますが、その実、本質を見ると検索エンジンに情報を提供するデータ形式であり、記事データそのものを検索エンジンに提供している行動に他ならないのです。提供されたデータを保持する部分に AMPキャッシュ という、ユーザーの誤認を誘う名称を利用しているあたりからも仮面を被っている様子を感じます。
とはいえAMPが本質を隠して単に高速化手法として打ち出しているのは私としては理解できる行動です。なぜなら懇切丁寧に説明しても、例えば データ提供 と キャッシュ保持 がどのようにニュアンスが違うのかを理解することは容易ではありません。理解するためにはまずは検索エンジンがたどり着こうとしている終着点の理解が必要だからです。そしてなによりAMPによって高速化することは間違いないのです。
このように書くとAMPは恐ろしいもののように思えてしまいますがそれは誤解です。
検索エンジンの運営者はコンテンツを生み出す人々の行動原理を理解しているし、コンテンツを生み出す存在がいなくなったら検索エンジンも共倒れだとも理解しています。そのため、AMPはデータ形式ではありますがカスタマイズ可能な範囲は広く、自IDで広告を提供できたり、自IDでGoogle Analyticsを設定できたりとサイト運営者のメリットも可能な限り残るように設計されています。
映画マトリックスの世界における機械と人間の関係で、機械(検索エンジン)が人間(コンテンツ≒コンテンツ提供者)をエネルギー源としている状態に近いとも言えますが、特にGoogleに関しては Do the Right Thing の言葉通り、自社の利益追求だけではなくウェブ全体のユーザーの利益を考慮して行動してもらえることを切に願います。
情報とUIの分離
検索エンジンがほとんどの質問に直接答えてくれるようになると、情報を提供するサイトは、そのサイトとしてのUIが実質消滅してデータだけを提供する役割となります。
これは情報を生み出す人とUIを提供する人が分離している状態だと言えます。そうなった場合にサイト運営者が情報を提供するインセンティブは何らか考慮されることになるでしょう。例えば検索エンジンが返答した際に、その情報を提供してくれたサイトに紐付く広告が表示されて対価を得ることができるなどの方法が考えられますが、実はAMPがこれに近い形で運営されています。
次に商品を販売するECサイトを考えてみましょう。
ECサイトの本質は物品やサービスを販売することなので、検索エンジンが全ての商品情報を吸い取っても痛くもかゆくもないどころか大歓迎なのです。こういった情報以外の部分に競争力を持つサイトはサービス提供に力を集中させる一方でUIを切り出すことも可能なのです。
例えばECサイト側がオープンな仕様の商品APIと購入APIを提供しておけば、あとは検索エンジン側でデータを吸い取ってくれるし、注文完了までもを検索エンジン内でまかなえるようになるかもしれません。
ユーザーが検索エンジンで検索すると、その人の欲しいものを把握して最適なサイトで最適な商品の購入にまでつなげてくれるならば、ユーザーと検索エンジンとECサイト運営者の全員がWin-Win-Winです。
これだけ聞くとあまりにも難しい事のように感じるかもしれませんが、Google Homeに置き換えて考えてみると少し現実味を帯びてきます。
例えば「OK, Google! いつもの洗剤を買っておいて」と話したら自動的にいくつかのサイトを比較して最適なサイトから商品を購入してくれるようになら、なる気がしませんか?
商品の購入意図を把握して購入のアクションを起こすこと自体は決して難しい事ではありません。
SEO対策とは、このように未来をなるべく高い精度で予測し、その未来に合わせて事前に用意しておくことであると考えています。
これから役に立つSEOの考え方
ここまでで歴史や未来予測の重要さを書いてきましたが、ではそれを現代のSEOにどのように役立てればいいでしょうか?
ここからはGoogle及びGooglebotをターゲットとした実践的な話を始めます。
まず考えるべきはウェブサイトと検索エンジンの仲介役とも言える、Googlebotについてです。GooglebotといえばGoogleの技術の集大成で、さぞかし謎技術で構成されているのだろうと思われるかもしれませんが、決してそんなことはないのだということは本稿をお読みの方は分かるはずです。
ChromeとGooglebotの違いを知る
最初にChromeとGooglebotの違いについて考えてみましょう。
現在のGooglebotはモバイルファーストインデックスならば中身はほぼモバイル版のChromeと同等だと考えて差し支えありません。そのためJavaScriptを駆使した複雑なレイアウトもスマホで表示するのと同等に処理できます。つまりレンダリングという観点では気にすることはほとんどありません。
では、ChromeとGooglebotの一番大きな違いは何かというと、それは操作者です。Chromeは人間が目的を持ってページのコンテンツを理解しながら操作するのに比べ、Googlebotはプログラムにより自動的に操作されます。
Googlebotの苦手分野
自動操作されるGooglebotでは人間のような柔軟な判断はまだ実現できておらず、レンダリングが完璧だったからといって、そのレイアウトを人間のように理解できるわけではありません。
例えばユーザーがUI要素をクリックしたonclickイベントで駆動するJavaScriptコードを考えてみます。昨今のウェブサイトでは様々な用途に利用されており、Google Analyticsのイベント記録やメニューの開閉、画面の状態変更やAJAXによるデータ取得処理の起動から画面遷移まで様々です。
これらonclickイベントは1ページ中に数千・数万カ所あると聞いても驚かない程度に多用されているウェブページになくてはならない機能ですが、こういったイベントをGooglebotは起動・実行することができません。
なぜなら現実的に考えると当たり前ですが、JavaScriptコードは実行してみるまでどういう目的のコードなのかは分からないし、実行してもはっきりとわからないことが理由として挙げられます。
「スタート」とラベルの付いたonclick要素を起動したらAJAXで次ページのデータを取得して本文がまるっと置き換えられるかもしれませんし、setInterval()でストップウォッチが動き始めるかもしれません。数千カ所あるonclickの起動順番によっても画面内容が変化するかもしれませんし、1つのonclick要素を2度以上押したら別の動きをする可能性すらあるので、Googlebotが<a href>をたどるような単純なルールでクロールすることは不可能なのです。
では未来永劫onclickイベントは無視されるかというと、それはどうでしょうか。ウェブページの内容をAI技術でリアルタイムに把握して適切なUI要素をクリックするという人間的な動きを実現できればクローラーがonclickイベントを起動できる日はやってくるかもしれません。
つまり 今はまだ実現できていない というだけなのです。
自分のなかにGooglebotのシステム像を持つ
このようなGooglebotができること・できないこと、というのはGoogle内部の人物からのこぼれ話という形でよく出てくる話題です。
それらの情報は私も興味深く聞くことがありますが、それは自分自身の予想したGooglebotの進化スピード・方向性と、実際に実現されたものを照合して補正する役割として利用しています。あらかじめ自分のなかにGooglebotのシステム像を作っておけば、その後は過度に情報を追いかけなくてもたまに補正するだけで常に最新に近い状況を把握し続けることができるのです。
Googlebotは決して謎技術の結晶ではなく現在のテクノロジーで普通に実装されているだけのものです。それ故に同じ時代のエンジニアが現実的に今はまだ難しそうだなと感じることは、Googlebotにとってもまた難しいし、同じ時代のエンジニアにはGooglebotがどのような動きをするべきなのかを想像することができるはずなのです。
Googlebotがクロールできないサイトを構築していては、SEO的にはスタートラインにも立てません。
Search ConsoleでGooglebotの動作を見る
Googlebotの動作を推測する上で重要なポジションを占めるツールがSearch Consoleです。
これは実際にGooglebotを動作させて結果をレポートと共に表示してくれるものなので、積極的に活用して分析することをお勧めします。
例えばSearch Consoleでライブテストを実施すると正常にページがレンダリングできていないケースがありますが、これは何が原因でしょうか?
Search Console側の一時的な問題
旧Search Console の Fetch as Google の頃から安定性が低いツールだったのですが、本稿の執筆時点では正常に動作しないことがよくあるようです。
Search Console側に原因がありそうなエラーが出たらしばらく待ってから再チェレンジしましょう。
ちなみにほぼ同等機能のモバイルフレンドリーテストの方が多少安定しています。
スクロールイベントを利用している
Googlebotは画面をスクロールしません。画面表示領域として10,000pixelにも及ぶ高さでウェブサイトにアクセスするのでスクロールが必要ないのです。
それ故に画像をスクロールイベントにフックして遅延読み込みしているとGooglebotから画像を認識できなくなる場合があるので要注意です。せっかく良質なコンテンツを提供しているのに、Googlebotに対して画像が1枚も表示されていないと正当な評価を受けることができなくなります。
robots.txtで意図せず弾いている
意外とありがちなのがrobots.txtで意図せずリソースを弾いてしまっているケースです。
CDNの利用やドメインシャーディングなどでリソースをオリジンと別ドメインに配置した場合、つい見落としがちですが分離先のドメインのルートディレクトリでrobots.txtを取得できるかどうかがクロール可能かどうかの鍵になります。/robots.txtにアクセスしたら結果、5xx番台のステータスが返却されるとそのドメイン全体のクロールが不許可と判断されます。分離先のドメインでルートディレクトリは503 Service Unavailableなどが返ったりしてませんか?
/robots.txtへのアクセスで正常に取得できるか、もしくは404などの4xx番台のステータスを返していることを確認しましょう。
クロールバジェット
Googlebotの動作を考える上で無視できないのがクロールバジェットの概念です。
少し上にも書きましたが、クローラーは謎技術を用いて一瞬でサイトの情報を吸い出せる魔法の存在ではありません。
例えば弊社の運営する卸・仕入れサイト スーパーデリバリーは商取引を行うECサイトですが本稿の執筆時点でアイテム数が100万点以上あります。必然的に個別のアイテムページも100万ページ以上ということになりますが、このサイト全体をクロールするのに必要な期間はどれくらいでしょうか?
どんぶり勘定的な計算ですが、例えばクローラーが1秒に1ページクロールすると1日にクロールできるのは86,400ページです。この計算では個別のアイテムページだけでも一巡するのに10日以上かかり、アイテム一覧ページは絞り込み条件や並び替えでほぼ無限に生成されるので何もせずにクローラーを解き放つと永遠にクロールは終わりません。
このようなクロール回数の限界のことを クロールバジェット といいます。
これは決して大規模サイトだけの問題ではなく、小規模サイトでもシステムが不適切に生成したリンクを永遠にさまよい続けるケースはあります。これから紹介する方法を使って効率的にクロールできるサイトを構築しましょう。
ページの優先度を考える
ウェブサイトは様々な役割を持つページが集まって構成されますが、それぞれのページのもつ価値は均一ではありません。
スーパーデリバリーの例では個別のアイテムページがサイトの持つ価値の源泉と考えることができるので、もれなく最新の状態にクロールしてもらいたいです。
次にアイテム一覧ページはというと、価値の源泉である個別のアイテムページを分類・要約・誘導する役割をもちます。言うなればまとめサイトのような存在で、独自コンテンツを持ちませんが、価値を持つページへアシストをする存在という点で一定の価値があります。
Googleで特定アイテムの品番・JANコード・型番などを検索した場合はその個別アイテムページにたどり着くべきですし、「マスキングテープ 仕入れ」と検索した場合はマスキングテープジャンルのアイテム一覧にたどり着く方が適切です。そういう意味でアイテム一覧ページクロールされるべきですが注意点があります。
例えばググった結果にアイテム一覧ページの人気順の6,257ページ目が引っかかることをのぞむ人はいませんし、もし引っかかっても誰もクリックしないでしょう。さらにアイテム一覧には様々な絞り込み機能(ファセットナビゲーション)や並び替えが用意されていて、それらの組み合わせでほぼ無限のページが自動生成されます。
そういったページをクロールし始めたらクローラーがサイト内で迷子になってしまうので、価値を持つページをピックアップして誘導するようにしましょう。
そこで、よく利用される交通整理の方法をいくつか考えてみます。
robots.txtやURLパラメータでクロール対象から除外
単純なURLパターンでクロール不要なページを指定できるならば、robots.txtでクロールを拒否することができます。
その他にもURLのパラメータ(/items?category=interior&sort=recently)で絞り込み条件があり、そのうちの一部をクロール対象外としたいならば、Search ConsoleのURLパラメータ機能を利用することができます。重要度の低い絞り込み条件が含まれるURLをクロール対象から除外することで無駄なクロールを大幅な削減が可能です。
この方法はシステムの変更とは独立して実施できることが多いので検討してみることをお勧めしますが、誤って設定すると一切クロールがされなくなるおそれがあるのでご注意ください。
表示可能なページ数を制限
クローラーはページ内のリンクをたどって順次クロールするので、ページネーションがあれば100ページ目や1,000ページ目、はたまた10,000ページ目だろうとクロールし続けます。しかし利用者の立場で考えるとアイテム一覧ページの6,257ページ目を見たい人はおそらくいないので、一定のページ数以降を表示する必要性はほとんどありません。
普通の人間が利用するシーンを考えると先頭からある一定のページ数だけ表示されれば、ほとんどの用途をカバーできますし、100ページまでページをたどって探さなければいけないサイトがあるとすれば、SEO以前にUI/UXの観点から見直すべきです。
実際に大手ECサイトを調べてみると大抵は100~200ページ程度を最大ページ数として、それ以降のページは表示できないようになっています。これはSEOだけが目的というわけではありませんが、SEOでもメリットの大きい施策です。
noindex, nofollowを利用
表示可能なページ数を物理的に制限することができない場合は、<meta name="robots">(robots metaタグ)を利用してクローラーだけを制限することができます。robots metaタグならばページごとに制御できる上にシステムで柔軟に出し分けも可能なので、例えば5ページ目以降はnoindex, nofollowとすることも可能です。
その他の利用方法として、例えばスーパーデリバリーでは「ポケットモンスター」と「ポケモン」を検索すると同一の結果になります。またGoogleで試してみてもほぼ同様の動きをすることが分かります。となるとこの両者の検索結果をそれぞれクロールするのは無駄であり片方で十分だと言えます。こういった場合に片方の検索結果にはnoindex, nofollowを入れることで無駄なクロールを削減できます。
noindex, nofollowはユーザーには一切影響を与えずクローラーだけを制限できる点で様々な用途に利用できます。
ヒット件数がゼロの場合の対処
アイテム一覧ページでよく起こる問題として検索結果のアイテムがゼロ件のページを永遠とクロールするケースがあります。
基本的にはゼロ件のページへはリンクしないことが鉄則ですが、絞り込みのリンクすべてを存在確認するとページ表示が遅くなる場合があったり、以前はアイテムがヒットした絞り込み条件でも時間経過でゼロ件になるケースもあるので完全に防ぐことはできません。
そういった場合に無駄なクロールを極力少なくするために、ヒット件数がゼロ件だったページではnoindex, nofollowを指定することで、それ以上傷口を広げないようにすることができます。
404を積極的に利用
データのライフサイクル的に削除されたことが明白な場合は積極的に404もしくは410ステータスを返すべきです。
スーパーデリバリーではアイテムのライフサイクルの終点は「削除」なので、その場合は404ステータスを返すようにしています。
ありがちなミスとして画面には「アイテムが見つかりません」と表示しているものの、ステータスは200を返しているケースがよくあるので注意しましょう。
この場合クローラーはウェブページとして生きているページで内容がスカスカという認識をします。
ソフト404 というステータス404に近い扱いをしてくれる場合もありますが、クローラーに過度な期待をせずに明示的な404ステータスを返すようにしましょう。
sitemap.xmlを活用
アイテム一覧ページの交通整理の方法について紹介しましたが、なんらかクロール範囲に制限を加えた場合はそれに伴って必ずやるべき施策があります。
それはsitemap.xmlの導入です。
サイトの種類や導入した制限の内容によっても異なりますが、先ほどの例のようにアイテム一覧ページに制限を加えた場合は、全ての個別アイテムページへの導線がクローラーからアクセス可能な状態になっているかの保証がなくなります。
そこでsitemap.xmlに個別のアイテムページを全て含めることで抜け落ちる心配がなくなります。
ウェブサイト内に直接リンクがある状態には効果として劣るかもしれませんが、少なくともGooglebotに対してページの存在を伝えることができて、インデックスするかの判断を委ねることができます。
robots.txt と robots metaタグの違い
両者の違いについてGoogleで調べてみると、重複した指示をした場合にどう判断されるかであったり、すでにインデックスされているページを削除したい場合についての情報などがよく引っかかります。
しかしここで取り上げたい差はより単純でより本質的な違いです。
それはrobots.txtでの指示は該当URLにアクセスする前にGooglebotが判断できるため該当URLへアクセスを試みる必要がないことと、一方でrobots metaタグはGooglebotがアクセスした後に判明するのでクロールバジェットを消費するという点です。
サイトにもよりますが、大規模サイトであるほど一般的に構造は複雑になり、クローラーが訪れる必要がないページというものが増えてきます。リンクはあるけれどもクロール不要なページが大量にある場合、それがrobots metaタグで指定されるとクロール自体は定期的に永遠に実行されます。なぜならばクローラーからはいつ何時、robots metaタグが変化してインデックスが許可されるか分からないからです。
結果としてインデックスされない点ではrobots.txtと効果は同じですが、クロールバジェットは消費してしまいます。
robots metaタグでnoindex,nofollowと指定する場合は、robots.txtで指定した方が適切ではないか?という可能性も検討するようにしましょう。
canonicalタグは銀の弾丸ではない
canonicalタグが初めて登場した当時、ちょうど私はSEO対策におけるURLの正規化に苦労している時期でした。
そんな時代に福音となったcanonicalタグですが、残念ながらURLの正規化が必要なくなったわけではありません。
クロールバジェットの観点から考えると自明ですが、例えば以下2つのURLは一般的に同じ結果でインテリアジャンルの赤色アイテム一覧ページを返してくれるサイトが大半でしょう。
http://example.com/items?category=interior&color=redhttp://example.com/items?color=red&category=interior
Webシステム開発に利用する一般なフレームワークはパラメータが入れ替わっていても差異を吸収してコントローラに渡ってくるデータはほとんど同一の状態になります。
しかし一般的にそのような動きをするだけであってURLとしては両者は異なりますし、システム的にも異なる動作を実装することが可能です。例えばアイテムを絞り込んだ順番がパラメータの順番となりパンくずリストの順番に反映されるという設計はありえます。
となるとクローラーはどのように解釈すれば良いかというと、十中八九で同一のコンテンツだとしてもクロールしてみるしかないのです。クローラーに謎の透視技術は備わっていないので箱の中身は開けてみないと分かりません。そして同じコンテンツだった場合に両者に同一のcanonicalが指定されているかもしれませんが、それはクロールバジェットの観点で考えると消費してしまった後の祭りです。これだけで一覧ページが2倍になると考えたら恐ろしいですし、さらに実際のパラメータ数は2個では済まないので組合せ爆発が発生しがちです。
アイテム一覧のような条件の組み合わせで無限にURLを生成できるページは、注意深く設計しないとクローラーを出口のない迷路に誘い込んでしまうので注意しましょう。
他にありがちなのがデフォルト値を持つ省略されたパラメータによるURL表記揺れです。
例えばページネーションのパラメータを省略すると1ページ目が表示されて2ページ目はpage=2となるとします。この場合に2ページ目から1ページ目へ戻るリンクにはpage=1と付けてしまっていませんか?/items?color=red と /items?color=red&page=1 が同一かどうかをクローラーは予測できないので1ページ目は常に2回ずつクロールされるという無駄が発生します。
ページ数の他にこの問題が発生しやすいのは並び順パラメータで、デフォルト値を持つパラメータが増えれば増えるほど同一コンテンツのURLバリエーションは増えてしまいます。
例えば赤色のアイテム一覧ページで、ページ数(page)のデフォルト値が1ページ目、並び順(sort)のデフォルト値が新着順(recently)ならばURLのバリエーションは以下の4パターンになります。
/items?color=red/items?color=red&page=1/items?color=red&sort=recently/items?color=red&page=1&sort=recently
パラメータがもう1つ増えると2倍の8パターンになり、順番も制御していなければさらにパターン数は増えます。
コンテンツ的には同一なのでcanonicalを指定すればインデックス自体には致命的な問題は出ませんが、クロールバジェットを顕著に消費するのでクロールがうまく行われなくなり、サイト全体が評価されづらくなる要因となります。
可能な限り全てのデータを渡す
前半の話題をふまえると長期的に検索エンジンに対してどこまでの情報を渡すべきなのか悩むかもしれませんが、今時点では渡せる情報をすべて渡してしまった方が検索エンジンからの流入が見込めるので総合的なメリットが大きいと考えています。
それらのデータには今のGooglebotでは活用できないものも含むかもしれませんが、判断に利用できるデータを可能な限り渡しておけばいずれ役に立つ日が来るはずで未来への投資になります。今現在Googlebotがどのデータをどのように利用しているという正確な情報は分かりようがないので、それならば役に立つ可能性がある情報はすべて渡しておくのが取り得る最善の選択です。渡せるデータは様々ですが、まずはウェブページとして公開することが前提で、そして付随する情報として前述の構造化データやsitemap.xml・AMPなどがあります。
ここではsitemap.xmlについて、別の側面からもう一度考えてみます。
元々の用途としてはサイト規模が巨大だったり複雑で隅々までクローラーが行き届かない可能性があるウェブサイトで利用されていて、クロール対象としたいURLを一覧化するものです。
一方で全てのデータを渡すという考え方では、sitemap.xmlにはクロール頻度と最終更新日を含める事が可能な点は注目すべきです。前回のクロールから更新されていないURLをGooglebotに伝えられるのでうまく活用されれば無駄なクロールが減ってクロールバジェットの節約につながります。このようにGooglebotの動作を考える場合は「自分ならGooglebotをどう実装するか?」という視点で考えてみるのも良いかもしれません。
まとめ
今回はSEOのベースとなる考え方に重点を置いて解説してみました。時代の流れと共にSEOに対するスタンスは変化していて、今は昔ほど気を遣わなくて良くなってきたという意味では良い時代です。ただしウェブサイトも同じだけ時代が進んでいるので複雑・多機能化が進み、その結果クローラーの進化と追いかけっこしているような状態です。
SEO対策では時代を読み、その時代とその次の時代で必要な対策を考えて実行していくことがとても大切です。良いコンテンツを提供するという基本に立ち返って、あとはクローラーの立場になって理解しやすいウェブページを提供するようにしましょう。
また、できるだけ時間経過で色あせにくいコンテンツを提供することができれば、じわじわとサイト全体の価値を上げていくことができるでしょう。例えばみなさんが今読んでいるこの記事ですが、今だけ通じる刹那的な情報ではなく、時間経過でも変化しにくい部分に力を入れて書いたつもりです。SEOの記事は鮮度命みたいな所はありますが、その中でも少しでも長く生き残れる記事を意識しています。
では、いつかSEOを全く気にしなくて良くなる日まで、SEO対策を行っていきましょう。