ランタイムから迫るAndroidアプリのパフォーマンスチューニング ~ Dalvik/ART/NDKでの性能計測・比較・改善
CodeZineでも同じ内容を掲載しておりますので、そちらでも閲覧できます。
http://codezine.jp/article/detail/8333
Androidアプリのチューニングについての情報を詰め込んでいます、是非ご一読いただけたらと思います。ソースコードはGitHub(Android/Java)で公開してます。
本稿で取り扱う内容
- Dalvik/ARTのヒープ領域管理とGC
- Dalvik/ARTが遅い原因
- Dalvik/ARTでの2種類のチューニング方法
- NDK(C/C++によるNative実装)での高速化
- ARM 32bit(v7a)におけるCPU命令を考えたパフォーマンス設計
(以下、本文)
アプリを開発していると、パフォーマンスが問題になることがよくあります。ボトルネックの原因は様々ですが、Android環境はCPUやメモリリソースがPCに比べて限られているため、ちょっとした処理でもCPUがボトルネックになってしまいます。そこで本稿では、Dalvik/ARTで行える最適化やNDKの導入などによるアプリの高速化手法を紹介します。
- Androidアプリ開発者
- アプリのCPU/メモリ負荷によるパフォーマンスを改善したい方
最新機能もいいけど、実行性能もね!
Android界隈は5.0 Lolipopの登場でにわかに活気づいていますが、アプリ開発者の皆様はいかがお過ごしでしょうか? Android 5.0からDalvikに代わってデフォルトかつ唯一のランタイムになったARTでの動作確認や、マテリアルデザインへの対応などに追われている方もいらっしゃるかと思います。本稿ではそこから視点を変えて、DalvikとART、ならびにNDKによるNative実装(以下NDK)という3種類の実行環境/実装方法に着目して、Androidアプリのパフォーマンス比較とチューニング方法を紹介します。
パフォーマンスチューニングをするにあたり、題材としては少々古いのですが、「Google Developer Day 2011」で参加資格を得るために行われた、DevQuizのスライドパズルの解法を探索するアルゴリズムをAndoridアプリで実装しています。PCと比べ貧弱なAndroidデバイスで動作するために高速、省メモリで動作するアルゴリズムを今回のためにフルスクラッチで開発しました。アルゴリズムの性能はCorei5 3.4GHzのPCで2スレッド稼働させた場合、全5,000問中、正答数4,945問(正答率98.9%)を3分ほどで計算完了します。
題材とするスライドパズルのルール
まずは「スライドパズルってなに?」という方向けの説明です。
スライドパズルとは4×4などのマス目上に1から15の数値と空き枠があり、左上から右下へ向かって数字順に並べることをゴールとしたパズルゲームです。DevQuizの課題はスライドパズルを元にサイズを縦横3~6マスの可変として、さらに壁という独自ルールを加えて拡張したもので、探索アルゴリズムの難易度は高くなっています。
事前に与えられたルールは次のとおりです。
- 幅3~6、高さ3~6マスのボードが与えられる
- ボードの各マスは、パネル、壁、空白のいずれか
- パネルは「1~9」および「A~Z」、壁は「=」、空白は「0」で示される
- 空白は上下左右のパネルと入れ替えられるが、壁とは入れ替えられない
- 空白を上下左右のパネルと入れ替えることを、それぞれ「U」「D」「L」「R」で示す
- 与えられた初期配置からゴール配置まで導く解を、「U」「D」「L」「R」を並べた文字列で示す
- ゴール配置は、左上から右下に向かって「1→Z」のパネルが順番に並び、右下隅が「0」となる
- 解答に使える「U」「D」「L」「R」それぞれの総数には上限がある
また、パズルの問題は次のような内容のファイルで提供されています。
72187 81749 72303 81778 ← 1行目 : 手数制限 L R U D
5000 ← 2行目 : 問題数
5,6,12=E4D9HIF8=GN576LOABMTPKQSR0J ← 3行目以降 : 幅,高さ,左上から右方向に順番に配置
6,5,238=I67E9MBC1AF05HJKRLNGPDQSTO
4,6,94827601A3BCD5JGMEFNHLKI
6,5,82935=174ABCD=RHTNJKFLI0PQSOGM
…
…
…
パズルの探索エンジンに使用したアルゴリズム
パズルの探索エンジンは、本稿用にフルスクラッチで作成しました。使用しているアルゴリズムは、幅優先探索を基本に、A*アルゴリズムや双方向探索を組み合わせた独自のアルゴリズムです。ただし、解答のためのアルゴリズム自体は本稿の主旨ではないので、ここではそのさわりだけ解説します。
図1は全体の探索フローを表しています。「3,3,120743586」は盤面が3マス×3マスのスライドパズルを表しており、これを入力として与えられたエンジンがその解答を探索しています。
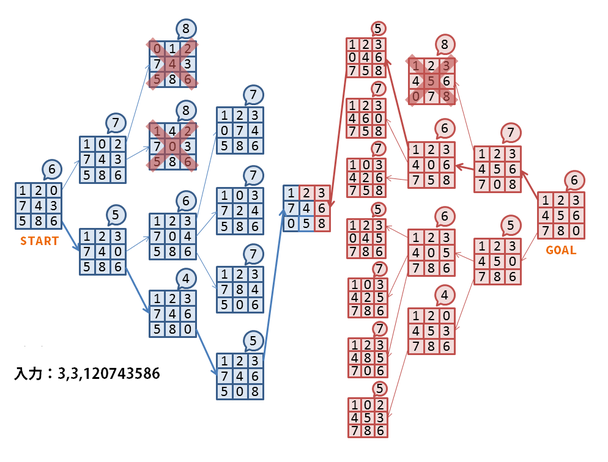
ルールでは0が空きセルで、そこを起点として上下左右に移動可能です。そこで、幅優先探索をベースとして、図1のSTARTと書かれている初期配置から移動可能な左方向と下方向へ0を進めます。
各盤面の右上の吹き出しは盤面の「評価関数」の結果を表し、この数値が少ないほどゴールに近いと判断されます。評価関数は、0を除く各マスが本来あるべき場所からずれているマス数の合計としています。初期配置では3、4、6、7がそれぞれ本来の位置から1マスずれ、5が2マスずれているため、評価関数の結果はこれらを合計した6となります。この数値のことをマンハッタン距離と呼んでいます。マンハッタン距離が0になると、各マスがすべてあるべき位置にいることになり、ゴールに到達したことになります。
ただし、単純に幅優先探索を行うと、盤面パターンが極端に増加してCPU負荷・メモリ消費ともに不足するため、適時「枝刈り」という処理を行います。図1の例では、赤い×印の付いた盤面はマンハッタン距離が増加しているため、ゴールにたどり着く可能性が低いと判断して以降の探索を打ち切っています。
また、スライドパズルはゴール時の盤面が決まっているので、ゴールからスタートに向けての逆方向探索も可能です。スタートとゴールの両方から探索し、同じ盤面が現れたらゴールにたどり着いたことになるのですが、これには計算量を減らせるという利点があります。スタートからゴールの移動距離をd、各盤面から枝分かれが2経路ずつあり、枝刈りを行わないとすると、順方向でゴールまで探索した場合の計算量は O(2d) となりますが、双方向探索では O(2d/2 + 2d/2) となって計算量が削減されます。
チューニング前の測定結果
チューニングを行う前に、基準となる実行速度を測定します。数値測定および比較を行うAndoid端末には「Nexus7(2013)」を使用しました。また、測定はAndoid端末のほか、比較のためPC(Corei5、3.4GHz)上でも行いました。測定結果はいずれも5回実行した平均をとっています。
| 実行環境 | 問数 | 正答数 | 処理時間(秒) | 処理速度(問/分) | |
|---|---|---|---|---|---|
| PC | Corei5 3.4GHz | 5,000 | 4,945 | 179 | 1,675.98 |
| Dalvik | Nexus7 2013 | 5,000 | 4,945 | 38,959 | 7.70 |
| ART | Nexus7 2013 | 5,000 | 4,945 | 24,169 | 12.41 |
PC上ではスライドパズル全5,000問を処理するのに3分ほどしかかかりませんが、全く同じ処理をNexus7で実行すると、Dalvik上では10時間以上、ART上でも6時間以上もかかります。これを後ほどチューニングして、大幅にパフォーマンスを改善させます。
Dalvik/ARTのヒープ領域管理
チューニングを行う前にもう1つ、DalvikおよびARTのヒープ領域管理の方式を理解しておきましょう。
コンカレントGCを採用
Dalvik/ARTでは、ヒープ領域の管理をランタイム側が担当し、不要になった領域の解放を「GC」(garbage collection)が実行する仕組みになっています。この仕組みにより、開発者はオブジェクトの解放を考える必要がなく、領域の解放し忘れによるメモリリークも未然に防がれます。一方で、GCは不要なオブジェクトを探してから解放するため、スループットは、開発者が明示的に最適な解放処理を行う場合よりも下がります。
GCにはいくつか方式がありますが、Dalvikでは「コンカレントGC」が採用されています。コンカレントGCは、スレッドの停止を最小限に抑えて可能な限りバックグラウンドで処理を行うため、アプリの応答性や(CPUの余剰コアがある場合には)スループットの改善などが見込めます。
DalvikのGCが抱える問題とARTでの改善
しかし、DalvikでコンカレントGCが有効に稼働するのは、ヒープの利用が少なめでアイドルタイムが十分にあるアプリの場合です。そうでないアプリの場合、コンカレントGCの実行完了を待つWAIT_FOR_CONCURRENT_GCが多発したり、GC_FOR_MALLOCという並列動作を行わない単純なマーク&スイープ方式のGCの実行が多くなったりします。GC_FOR_MALLOCは、オブジェクト生成時にヒープ領域に空きが不足すると起動されます。そして、当該スレッド(オブジェクトを生成しようとしたスレッド)がそのままGC処理を担当するため、アプリのパフォーマンスに直接影響が出ます。
短命オブジェクトの解放で効果を発揮する「世代別GC」が採用されていないことも、注意点として挙げられます。Dalvikでは、GCが発生するたびにヒープの全領域を探索することになるため、生存オブジェクトの数が極端に多かったり、オブジェクトの生成と解放を繰り返したりするとパフォーマンスが劣化します。
一方で、ARTはGCが大幅に改良されています。Dalvikと違い、コンカレントGCが有効に動作するケースが多く、実際にスライドパズルアプリで測定したところ、99%以上のGCはコンカレント動作をしました。さらには、新たに生成されたオブジェクトのみを対象とした高速なGCも導入され、世代別GCの利点を一部得られるようになりました。
フラグメンテーション(断片化)の解消
また、ヒープ領域管理でもう1つ欠かせないのが「フラグメンテーション(断片化)の解消」です。フラグメンテーションとは、長期間稼働中のアプリでヒープ領域の確保と解放を繰り返す間に、細かい領域が飛び飛びに確保された状態になることです。フラグメンテーションが発生している状態で巨大な(連続した)領域の確保をしようとすると、ヒープに空き容量が十分にあってもGCが発生します。これが繰り返されるとGCが頻発してパフォーマンスに影響し、最終的にはOutOfMemoryErrorが発生します。
通常はフラグメンテーションを解消するために、GCとともにCompactionという処理が行われますが、DalvikのGCにはCompactionが実装されていません。そのため、長時間起動するアプリはある程度考えて領域の確保と解放をしないとフラグメンテーションが発生し、徐々にパフォーマンスが劣化していきます。
これはARTでも同様で、原稿執筆時点ではCompactionを行いません。しかし、Lollipop以降のARTのソースコードにはCompactionを行うGCが追加されているため、そう遠くないうちに利用可能になりそうです。
チューニング①「オブジェクトプールの導入」
Dalvik/ARTのヒープ領域管理が分かったところで、実際にチューニングを行います。まずは、スライドパズルを探索する間にGCがどれくらい動作しているかを測定してみます。
| GC種別 | 回数 | 停止1(秒) | 停止2(秒) |
GC停止 合計(秒) |
GC稼働 合計(秒) |
|---|---|---|---|---|---|
| GC_FOR_ALLOC | 2,884 | 1,434.6 | - | 1,434.6 | 1,434.6 |
| GC_CONCURRENT | 3,691 | 6.6 | 119.8 | 126.4 | 784.0 |
| GC_EXPLICIT | 0 | 0.0 | 0.0 | 0.0 | 0.0 |
| GC_BEFORE_OOM | 0 | 0.0 | - | 0.0 | 0.0 |
| WAIT_FOR_CONCURRENT_GC | 3,527 | 0.0 | - | 723.2 | 723.2 |
上記の表は、アプリを実行させて最初の500問の探索をする間に発生したGCの内訳です。その間の実行時間は4,448秒でした。各GCの動作は次のとおりです。
GC_FOR_ALLOC[1]
前節でも出てきましたが、オブジェクトを生成しようとしたスレッド自身がGCを行い、コンカレント動作を行わないため、GC全体にわたってスレッドが停止します。
GC_CONCURRENT
バックグラウンドのGCスレッドが処理を行い、その中で2回、全スレッドをわずかに停止します。
GC_EXPLICIT
GC_CONCURRENTとほぼ同じ動作をしますが、開発者が明示的に System.gc() をコールした際に発生します。
GC_BEFORE_OOM
OutOfMemoryErrorの直前に行われる最後の砦となるGCです。「普通にヒープ領域を確保しようとして失敗」 → 「GC_FOR_ALLOCを発生させてから再度ヒープ領域を確保に失敗」 → 「ヒープ領域を拡張してから領域の確保に失敗」と、3回の確保に失敗したら起動されます。基本的な動作はGC_FOR_ALLOCと同様ですがSoftReferenceを解放するという点のみ異なります。
WAIT_FOR_CONCURRENT_GC
厳密にはGCではありませんが、GC_FOR_ALLOCが発生するタイミングでコンカレントGCが稼働中だった場合にその実行完了を待つので、パフォーマンスへの影響としてはGC_FOR_ALLOCとほぼ同様です。
なお、Dalvikでは、アプリに対してデバッガが接続されていたらGC_CONCURRENTが動作しないので、この測定はデバッガが接続されていない状態で行う必要があります。
[1] 前節では「GC_FOR_MALLOC」と表記していましたが、ここでは「GC_FOR_ALLOC」となっています。これはオブジェクトの生成からメモリ確保までの流れで、Dalvikのソースコードが表記揺れしていることが原因です。変数や関数名にはGC_FOR_MALLOCが使われていますが、文字列として定義されているGC名はGC_FOR_ALLOCとなり、ログなどではGC_FOR_ALLOCが使われます。
細かい事情は推測するしかありませんが、Javaに近い層からはオブジェクトのアロケーションでallocという名称が多く用いられ、より下層にいくとmalloc/calloc系の命名が多用され、中立的な立場であるGCはその表記揺れのちょうど中間で混じってしまったのかもしれません。
結果を見ると、4,448秒の稼働に対して51%にもあたる2,284秒がGCに費やされ、その中でも特に多いのがGC_FOR_ALLOC/WAIT_FOR_CONCURRENT_GCです。GC_CONCURRENTもGC稼働時間としては多いのですが、全スレッドを停止させるのはGC停止合計である126.4秒なので、パフォーマンスをさほど劣化させていません。
DalvikでGC_FOR_ALLOC/WAIT_FOR_CONCURRENT_GCが多くなってしまう理由には、メモリをなるべく節約する方向に最適化されていることが挙げられます。メモリの少ない端末で複数のアプリを同時に動かすための最適化として、このアプローチをとることは間違ってません。しかし逆にいうと、メモリを多めに確保した上での最適化は不得意です。
例えば、Nexus7(2013)では、確保しておく余剰ヒープ領域の上限値(dalvik.vm.heapmaxfree)が8MBと設定されています。そのため、ヒープ領域の確保容量に余裕があっても、現在の使用量+8MBを超えるとsoftLimit[2]という制限に引っかかり、GC_FOR_ALLOC/WAIT_FOR_CONCURRENT_GCが実行されます[3]。つまり、現在のヒープの空き領域とは関係なく、8MB分のオブジェクトを生成するたびに、パフォーマンスへの影響が大きなGC_FOR_ALLOC/WAIT_FOR_CONCURRENT_GCが実行されることになります。これはDalvikにおけるパフォーマンス劣化の大きな原因ですが、この制限を非root権限のアプリから回避する方法はありません。
そこで、チューニングの方向性として、GCの発生回数を減らすためになるべく新しいオブジェクトを生成しない方法を考えてみます。キーポイントは、余剰ヒープ領域である8MBの壁を突破してGC_FOR_ALLOC/WAIT_FOR_CONCURRENT_GCが発生するよりも前にGC_CONCURRENTが完了することです。これができれば、GCでの待ち時間は減少します。
[2] softLimitはGC_FOR_ALLOCを起動する閾値となるヒープ使用量(オブジェクトがアロケートされている容量)が設定されます。一方、GC_CONCURRENTが起動するヒープ使用量の閾値は
softLimit - 131072と設定されるため、GC_CONCURRENTが終了する前に131,072バイト以上確保してしまうとWAIT_FOR_CONCURRENT_GCが発生します。[3] 説明を簡略化するために余剰ヒープ領域としてdalvik.vm.heapmaxfreeのみを挙げましたが、実際にはdalvik.vm.heaptargetutilizationとdalvik.vm.heapminfreeも関わってきます。ただし、ある程度のヒープ領域を確保しているアプリではすぐにオーバーフローするため、dalvik.vm.heapmaxfreeのみに依存します。
最初に紹介するのは、不要になったオブジェクトをプールして再利用するという古典的なテクニックです。
次のソースコードは、オブジェクトをプールするために作成したシンプルなクラスです。
public static class MemoryPool<T> {
private Object[] pool;
private int index = 0;
private int poolSize;
private Class<T> initializer;
public MemoryPool(Class<T> initializer) {
// プールサイズの初期値、不足すれば自動拡張するので少なめの数を適当に設定
this.poolSize = 1 << 4;
pool = new Object[poolSize];
try {
for (int i = 0; i < poolSize; ++i) {
pool[i] = initializer.newInstance();
}
} catch (InstantiationException | IllegalAccessException e) {
throw new RuntimeException();
}
this.initializer = initializer;
}
public void trash() {
index = 0;
}
@SuppressWarnings("unchecked")
public T get() {
if (index >= poolSize) {
// プールサイズを超えてget()要求が来た場合、
// プールを構成する配列を2倍の容量で生成し直して
// 元の配列からオブジェクトをコピーしてから、
// 増やした領域のオブジェクトをまとめて生成する
int newPoolSize = poolSize << 1;
if (newPoolSize <= poolSize) {
// intのオーバーフロー、対応しない
throw new RuntimeException();
}
Object[] newPool = new Object[newPoolSize];
System.arraycopy(pool, 0, newPool, 0, poolSize);
poolSize = newPoolSize;
pool = newPool;
try {
// 今回増加した分のオブジェクトをまとめて生成
for (int i = index; i < poolSize; ++i) {
pool[i] = initializer.newInstance();
}
} catch (InstantiationException | IllegalAccessException e) {
throw new RuntimeException();
}
}
return (T) pool[index++];
}
}
このクラスは生成時にオブジェクトをまとめて生成しておき、get() メソッドでプールからオブジェクトを取得します。プールが枯渇した場合には2倍の容量で内部配列を作り直し、増加分のオブジェクトを追加で生成します。プールから取得したオブジェクトが不要になったら、trash() メソッドですべて再利用可能にします。この方式はオブジェクトの利用に一定の周期があり、その周期ごとにすべてのオブジェクトを解放できるたぐいの処理に向いています。また、各オブジェクトの解放のタイミングを管理する必要がないので処理が簡潔になる、という利点もあります。
シンプルで軽快なオブジェクトプール
プール管理の方法は他にもあります。各オブジェクトの解放タイミングが明確な場合、すぐに思いつく方法は java.util.LinkedList クラスを利用して、オブジェクトが不要になったら add() メソッドでプールに入れ、新しいオブジェクトが必要になったら poll() メソッドでオブジェクトを取り出すという方法です。しかし、この方法には問題があります。LinkedListクラスはその構造上、オブジェクトを追加するたびに内部で新しい管理用オブジェクトを1つ生成してしまいます。そのため、オブジェクトの生成を1つ削減するために新規オブジェクトを1つ生成するという、本末転倒な事態になります。
そこで、単純に追加と取得のみを行うMemoryPoolの実装を紹介します。
public static class MemoryPool<T> {
private Object[] pool;
private int index = 0;
private int poolSize;
public MemoryPool() {
// プールサイズの初期値、不足すれば自動拡張するので少なめの数を適当に設定
this.poolSize = 1 << 4;
pool = new Object[poolSize];
}
public void add(T o) {
if (index >= poolSize) {
// プールサイズを超えてadd()要求が来た場合
// プールを構成する配列を2倍の容量で生成し直して、
// 元の配列からオブジェクトをコピーする
int newPoolSize = poolSize << 1;
if (newPoolSize <= poolSize) {
// intのオーバーフロー、対応しない
throw new RuntimeException();
}
Object[] newPool = new Object[newPoolSize];
System.arraycopy(pool, 0, newPool, 0, poolSize);
poolSize = newPoolSize;
pool = newPool;
}
pool[index++] = o;
}
@SuppressWarnings("unchecked")
public T get() {
if (index <= 0) {
return null;
}
return (T) pool[--index];
}
}
オブジェクトが不要になったタイミングで add() メソッドでプールに追加し、オブジェクトが必要になったら get() メソッドでプールから取得します。ここでは専用のクラスを用意しましたが、実は後者の実装の代わりに java.util.ArrayList クラスを利用することも可能です。
| クラス | 追加 | 取得 | 削除 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 先頭 | 末尾 | 中央 |
ランダム 位置 |
ランダム 位置 |
先頭 | 末尾 | 中央 |
ランダム 位置 |
|
| ArrayList | O(n) | O(1) | O(n/2) | O(n/2) | O(1) | O(n) | O(1) | O(n/2) | O(n/2) |
| LinkedList | O(1) | O(1) | O(n/2) | O(n/4) | O(n/4) | O(1) | O(1) | O(n/2) | O(n/4) |
まず指標の説明として、O(n/2)という表現は本来意味をなしませんが、比例する係数も表したかったので便宜上付けています。つまり、ArrayList のO(n/2)と LinkedList のO(n/4)を比較して LinkedList のほうが高速という比較は不正ですが、LinkedList の中央に追加O(n/2)とランダム位置に追加O(n/4)ではランダム位置に追加のほうがおおよそ2倍程度高速というのは期待できます。
表を確認すると、ArrayList は末尾に追加・削除とランダム位置の取得が高速ですが、ランダム位置への追加・削除は不得意です。一方、LinkedList はランダム位置の追加・削除・取得の際に先頭もしくは末尾の近い方向からたどるため、中央が最も性能劣化をするポイントで平均するとO(n/4)となります。
速度特性としては、ランダム位置の取得を除いて LinkedList が優勢に見えますが、前述のとおり LinkedList は内部的に管理オブジェクトを作成するなど基本負荷が高いので、今回の用途では採用できません。一方で、ArrayList は末尾に追加と末尾を削除がO(1)で可能なため、単純なプールとして利用できます。プールとしての利用例としては、オブジェクトを追加する際には pool.add(o) とし、プールから取得する際には pool.size() > 0 ? pool.remove(pool.size() - 1) : null; とします。プールからの取得時の書き方が少々直感的でないのが難点ですが。
オブジェクトプール導入の効果
さて、それではアプリのチューニングを行います。スライドパズルの探索エンジンでは、盤面と移動経路を表す FieldOperation オブジェクトが、最も短い期間で生成と解放を繰り返します。そこで、FieldOperation オブジェクトの生成をプール利用に切り替えてテストした結果が次の表です。
| 実行環境 | プール | 処理時間(秒) | 処理速度(問/分) | 速度指標 | |
|---|---|---|---|---|---|
| Dalvik | Nexus7 2013 | OFF | 38,959 | 7.70 | 1.00 |
| Dalvik | Nexus7 2013 | ON | 28,529 | 10.52 | 1.37 |
| ART | Nexus7 2013 | OFF | 24,169 | 12.41 | 1.00 |
| ART | Nexus7 2013 | ON | 21,950 | 13.67 | 1.10 |
| PC | Corei5 3.4GHz | OFF | 179 | 1,675.98 | 1.00 |
| PC | Corei5 3.4GHz | ON | 179 | 1,675.98 | 1.00 |
速度指標は、各実行環境のプールOFFの状態を基準とした数値です。プールを利用すると、DalvikとARTともに顕著に高速化していることが分かります。興味深いのはDalvikのほうが高速化の効果が高い点です。ARTはDalvikに比べGCが優秀なので、DalvikほどにはGCチューニングによる高速化の余地がないのです。
一時オブジェクトが大量に必要で、かつGCが頻発しているアプリにおいて、このチューニング方法は手軽な上に効果的です。
なお、PCでは両者に有意な差はでませんでした。なぜなら、PCでは世代別GCが機能するため、短命オブジェクトの生成と解放のコストは限りなく少ないからです。
チューニング②「オブジェクトの配列化」
2つめに紹介するのは、オブジェクトを生成する代わりにすべて配列化するという、少々強引なチューニング方法です。Javaらしさを完全に失ってしまうため、本当に速度が必要な場合以外は利用するべきではありませんが、チューニングとしてはそれなりの効果が出ます。
今回配列化の対象としたのは、Field という盤面を表すクラスです。Field クラスはループ検出と双方向探索の突き合わせに利用しています。探索を進めて移動を繰り返すと、しばしば同じ盤面に戻ることがあります。そこからさらに探索を進めてしまうとループして、それ以降の探索は無駄になってしまいます。それを防止するために、過去に登場した盤面を記録しておき、移動のたびに過去の盤面に存在しないことを確認しています。また、今回のアルゴリズムは双方向探索を採用しているため、順方向探索の盤面が逆方向探索の盤面に存在する、もしくはその逆ならゴールへの経路が見つかったことになります。その検出にも Field クラスを利用しているため、Field クラスはアルゴリズムの中核をなす重要なクラスです。
利用できるヒープ領域には制限があるため、今回は40万件までという制限を設けていますが、Field クラスはアプリ中で最もメモリを消費するクラスでもあります。
Field クラスの定義は次のとおりです。field、hashCode、operationCount、currentOperation、operations という5つのインスタンス変数を持ちます。
public static class Field {
// 盤面
private int[] field;
// equalsの呼び出し回数が多いのでhashCodeを事前に計算して保持しておく。
// 盤面(field)のみに依存
private int hashCode;
// 移動の回数
private short operationCount;
// 移動の記録(アクティブ)、operationsと合わせることで完全な移動の履歴になる
private byte currentOperation;
// 移動の記録(非アクティブ)、immutable。
// 子孫およびFieldOperationと同一オブジェクトを共有する
private byte[] operations;
public Field(FieldOperation fieldOperation) {
init(fieldOperation);
}
…
…
…
}
配列化した Field クラスは実体を持たなくなりますが、利便性のためにクラス自体は残して配列内の位置情報などを持つように変更しました。
public static class Field {
// 盤面
public static final int FIELD_OFFSET = 0;
public static final int FIELD_SIZE = 8;
// equalsの呼び出し回数が多いのでhashCodeを事前に計算して保持しておく。
// 盤面(field)のみに依存
public static final int HASH_CODE_OFFSET = 8;
// 移動の回数
public static final int OPERATION_COUNT_OFFSET = 9;
// 移動の記録(アクティブ)、operationsと合わせることで完全な移動の履歴になる
public static final int CURRENT_OPERATION_OFFSET = 10;
// 移動の記録(非アクティブ)、immutable。
// 子孫およびFieldOperationと同一オブジェクトを共有する
public static final int OPERATIONS_OFFSET = 11;
public static final int OPERATIONS_SIZE = 12;
public static final int FIELD_ARRAY_SIZE = FIELD_SIZE + OPERATIONS_SIZE + 3;
public static int[] newField() {
return new int[FIELD_ARRAY_SIZE];
}
…
…
…
}
盤面( Field )を表すには、1オブジェクトあたり int 配列で23要素に、ハッシュ表を管理する情報の2要素を加えて合計25要素が必要です。そこで 400,000 * 25 + 1、つまり 10,000,001要素の int 配列を確保します。確保する容量は膨大ですが、プリミティブ型の配列は全体で1オブジェクトなので、GCに与える負荷はさほど大きくありません。
配列の利用イメージは図2のようになります。
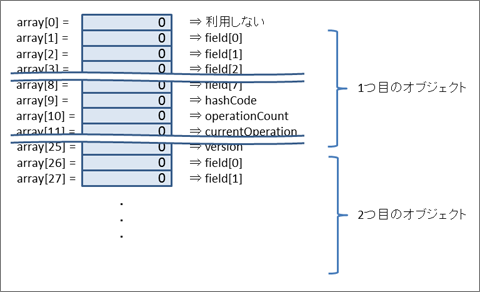
エラー処理のために先頭アドレスである0は空けておき、1から利用します。1つの Field オブジェクトを表すには巨大な配列とその中の開始アドレスを指定することで特定します。例えば、hugeArray を40万件の Field オブジェクトを保持する巨大な配列とすると、100番目のオブジェクトは hugeArray[2476] ~ hugeArray[2500] の範囲にデータが存在し、移動回数を表す operationCount は int operationCount = hugeArray[2476 + OPERATION_COUNT_OFFSET]; という手順で利用します。
配列化した状態で測定した結果が次の表です。
| 実行環境 | プール | Field | 処理時間(秒) | 処理速度(問/分) | 速度指標 | |
|---|---|---|---|---|---|---|
| Dalvik | Nexus7 2013 | OFF | 標準 | 38,959 | 7.70 | 1.00 |
| Dalvik | Nexus7 2013 | ON | 標準 | 28,529 | 10.52 | 1.37 |
| Dalvik | Nexus7 2013 | ON | 配列化 | 16,740 | 17.92 | 2.33 |
| ART | Nexus7 2013 | OFF | 標準 | 24,169 | 12.41 | 1.00 |
| ART | Nexus7 2013 | ON | 標準 | 21,950 | 13.67 | 1.10 |
| ART | Nexus7 2013 | ON | 配列化 | 18,067 | 16.60 | 1.34 |
| PC | Corei5 3.4GHz | OFF | 標準 | 179 | 1,675.98 | 1.00 |
| PC | Corei5 3.4GHz | ON | 標準 | 179 | 1,675.98 | 1.00 |
| PC | Corei5 3.4GHz | ON | 配列化 | 230 | 1,304.35 | 0.78 |
結果を見ると、配列化したパターンはDalvikのパフォーマンスが2.33倍になりました。マーク&スイープ方式のGCは、ヒープ領域に存在するオブジェクトをすべて探索してマークした後にマークの付いていないオブジェクトを解放(スイープ)します。そのため、生存オブジェクトの数が極端に多いと、GCのたびに探索コストがかかり効率が悪くなります。
Field クラスのチューニングで、前項のオブジェクトプールではなく配列化という手法を採用したのは「オブジェクトの数」が理由です。生存オブジェクトが極端に多い場合、オブジェクト数を減らすほうがチューニングの効果が高くなることが分かります。
ここで示した例は、1つのクラスを丸ごと配列化するという少々乱暴な手段でしたが、細かいオブジェクトの生成をなるべく減らし、配列化するという方法はパフォーマンス改善に有効です。
また、PCでも速度比較したところ、配列化バージョンはパフォーマンスが大幅に低下しました。この結果は想定どおりで、配列化したバージョンはメモリ上の物理的な位置が固定されるため、参照渡しではなく値渡しのような動作が一部で必要になります。つまり、実際の処理内容としては元の処理よりもオーバーヘッドが大きくなっています。Dalvik/ARTでは、そのオーバーヘッドよりもGCによる負荷のほうが大きいために高速化しましたが、「ヒープ領域が潤沢」「世代別GCが機能」「CPUの余剰コアがある」というPC環境ではGC負荷が大きくなかったため、むしろオーバーヘッドによって性能劣化したと考えられます。
チューニング③「NDKの導入」
前節まではDalvik/ART上でのチューニングを行ってきましたが、本節ではさらなるチューニングの手段として「NDKの導入」を行います。
アプリの開発中にパフォーマンスで困ったらNDKで高速化という話はよく出てきますが、具体的にどれくらいのパフォーマンス改善を望めるのかの目安がありません。そもそも、DalvikはJITによって、ARTはAOT(Ahead-Of-Time)によって、重要な部分は何もしなくてもNativeで実行されるのですから、わざわざ開発者が高速化を目的にNDKを利用する必要があるのか、という疑問もあります。
そこで、NDKの導入により実際にどれほど高速化されるのかを、スライドパズルアプリで調べてみます。
実装にはC言語を採用しました。C言語での実装の場合、Dalvik/ARTと違い、ヒープ領域の管理は開発者に任されます。そこで、Dalvik/ARTでのGCに変わる手段として今回は参照カウント方式を採用しました。「参照がゼロになった時点で即時解放」という単純な仕組みですが、GCで問題になっていた生存オブジェクトの探索コストがかからなくなるため、大幅な高速化が期待できます。
NDKを導入するのはスライドパズルアプリの中核である探索エンジン部分です。UI制御や問題の入力などはボトルネックではないので、実装はJavaのままとします。
また、アルゴリズムや処理内容での差異をなくすため、C言語で実装する探索エンジンはJava版と同一処理を実装します。実は、NDKによるC言語での実装を元々見越していたため、Java版の探索エンジンにはMap/Setなど標準コレクションを一切利用せず、代わりに2種類の軽量コレクションを独自に実装してあります。つまり、オブジェクトの確保・解放処理以外はほぼ同一の処理内容となります。
JavaからC言語への置き換えの例として、前節でも出てきた盤面を表すJava版の Field クラスを、C言語版では Field 構造体として実装しています。両者を比較してみましょう。
public static class Field {
// 盤面
private int[] field;
// equalsの呼び出し回数が多いのでhashCodeを事前に計算して保持しておく。
// 盤面(field)のみに依存
private int hashCode;
// 移動の回数
private short operationCount;
// 移動の記録(アクティブ)、operationsと合わせることで完全な移動の履歴になる
private byte currentOperation;
// 移動の記録(非アクティブ)、immutable。
// 子孫およびFieldOperationと同一オブジェクトを共有する
private byte[] operations;
public Field(FieldOperation fieldOperation) {
init(fieldOperation);
}
public void init(FieldOperation fieldOperation) {
this.field = fieldOperation.field;
this.operations = fieldOperation.operations;
this.currentOperation = fieldOperation.currentOperation;
this.operationCount = fieldOperation.operationCount;
this.hashCode = 0;
for (int fieldEntry : this.field) {
this.hashCode ^= fieldEntry;
this.hashCode *= 13;
}
}
@Override
public int hashCode() {
return hashCode;
}
@Override
public boolean equals(Object obj) {
if (obj == null || !(obj instanceof Field)) {
return false;
}
Field another = (Field) obj;
if (hashCode != another.hashCode
|| !Arrays.equals(field, another.field)) {
return false;
}
return true;
}
public String getOperations(boolean reverseMode) {
return FieldOperation.getOperations(operations, currentOperation,
operationCount, reverseMode);
}
}
typedef struct {
Uint32Array *field;
Uint8Array *operations;
int reference;
int hashCode;
uint16_t operationCount;
uint8_t currentOperation;
} Field;
Field *Field_alloc(FieldOperation *fieldOperation) {
Field *this = malloc(sizeof(Field));
if (this == NULL) {
return NULL;
}
this->reference = 1;
this->field = fieldOperation->field;
Uint32Array_retain(this->field);
this->operations = fieldOperation->operations;
Uint8Array_retain(this->operations);
this->currentOperation = fieldOperation->currentOperation;
this->operationCount = fieldOperation->operationCount;
int i;
this->hashCode = 0;
for (i = 0; i < this->field->length; ++i) {
this->hashCode ^= this->field->list[i];
this->hashCode *= 13;
}
return this;
}
int Field_equals(Field *this, Field *another) {
if (another == NULL) {
return 0;
}
if (this->hashCode != another->hashCode
|| Uint32Array_equals(this->field, another->field) == 0) {
return 0;
}
return 1;
}
void Field_retain(Field *this) {
this->reference++;
}
void Field_release(Field *this) {
if (--this->reference <= 0) {
Uint32Array_release(this->field);
Uint8Array_release(this->operations);
free(this);
}
}
void Field_getOperations(Field *this, unsigned char reverseMode,
char *operationsString) {
FieldOperation_getOperations(this->operations, this->currentOperation,
this->operationCount, reverseMode, operationsString);
}
Javaではコンストラクタで自動的にヒープ領域に確保されるのに対し、C言語では Field_alloc() および Field_release() 関数の内部でmalloc/freeを利用して領域の確保・解放を行っています。また、Javaでは equals() および hashCode() メソッドの規約に従うために int hashCode() メソッドをオーバーライドしているとか、C言語の Field_getOperations() 関数と値の戻し方が異なるとかいうように細かな差はあるものの、両者は同一の処理となっています。
では、測定結果を見てみましょう。
| 実行環境 | プール | Field | 処理時間(秒) | 処理速度(問/分) | |
|---|---|---|---|---|---|
| Dalvik | Nexus7 2013 | OFF | 標準 | 38,959 | 7.70 |
| Dalvik | Nexus7 2013 | ON | 標準 | 28,529 | 10.52 |
| Dalvik | Nexus7 2013 | ON | 配列化 | 16,740 | 17.92 |
| ART | Nexus7 2013 | OFF | 標準 | 24,169 | 12.41 |
| ART | Nexus7 2013 | ON | 標準 | 21,950 | 13.67 |
| ART | Nexus7 2013 | ON | 配列化 | 18,067 | 16.60 |
| NDK | Nexus7 2013 | OFF | 標準 | 8,784 | 34.15 |
| PC | Corei5 3.4GHz | OFF | 標準 | 179 | 1,675.98 |
| PC | Corei5 3.4GHz | ON | 標準 | 179 | 1,675.98 |
| PC | Corei5 3.4GHz | ON | 配列化 | 230 | 1,304.35 |
Dalvikの初期状態から比べると4.44倍、最も高速化したプールON、Fieldオブジェクトの配列化状態と比べても1.91倍というパフォーマンスが出ました。高速化に最も寄与したのは、GCが一切不要になったことです。他にも、JIT/AOTで生成されるJava特有のオーバーヘッドを含んだネイティブコードよりも、開発者がシンプルに書いた実装のほうがAndroidの環境では実行効率が良いことが考えられます。
チューニング 番外編「ARM向けの最適化」
ここまではヒープ領域の管理方法に着目してパフォーマンスチューニングを行ってきましたが、少し趣旨を変えて、ここではARM向けの最適化手法を紹介します。Android 5.0の登場と時を同じくして、NDKでも64ビットのARMがサポートされましたが、本章では現在最も普及しているARM v7a(32ビット)の環境を対象としています。
省メモリとアライメント
スマホアプリでは利用可能なメモリは限られているので、極力無駄なメモリを利用しないようにするべきですが、省メモリはCPU側の負担になる場合があります。
プロセッサの種類にもよりますが、一般にワード(4バイト)の処理が最も高速でハーフワード(2バイト)やバイト(1バイト)の処理には「ペナルティ」が付き、数サイクルの遅延が出ます。例えば、省メモリを目的として int 型(4バイト)を char 型(1バイト)に変更して3バイト節約したつもりが、CPU側に負担を強いる結果になります。省メモリが必要なのか、それとも計算速度が必要なのか、優先順位をしっかり決めて設計するべきです。
また、ARMプロセッサはメモリの「アライメント」が正しいことを大前提として動きます。アライメントとは、簡単に説明すると4バイトの変数を定義した場合、4バイト区切り(4の倍数)のアドレスに配置する必要があるということです。x86プロセッサではアライメントがずれている場合でも通常1サイクルのところを2サイクルに分けて読み込みが行われて正常に動作しますが、ARMの場合はそもそも正常に動作しなくなります。
アライメントは、基本的にはコンパイラが自動的に合わせてくれるため、普段は意識する必要はありません。しかし、その結果として開発者が省メモリしたつもりでも全く省メモリになっていない場合があります。
次のC言語のコードを見てください。int 型=4バイト、char 型=1バイトとします。
struct struct_a {
int int_field_1;
char char_field_2;
int int_field_3;
}
この struct_a 構造体は、int 型データの間に char 型データが挟まっているので、そのまま配置してしまうと int_field_3 のアライメントがずれてしまいます。そこでコンパイラは、3バイトのパディング(詰め物)を char_field_2 と int_field_3 の間に入れてアライメントを合わせます、このため、この構造体のサイズは12バイトとなります。
では、次の場合はどうなるでしょう?
struct struct_b {
int int_field_1;
int int_field_3;
char char_field_2;
}
実は、このように配置しても sizeof で返される数値は12となります。なぜかというと、sizeof は、malloc(sizeof(struct struct_b) * length) のように連続領域や配列を確保してもアライメントが合うサイズを返すからです。
配列で確保しない場合は、malloc(sizeof(struct struct_b) - 3) のようにすれば無駄はなくなりますが、 空いた領域は4バイト境界ではないので有効活用が難しく、結局空いたままになる可能性が高くなります。
結果として、この場合は char_field_2 を int 型にしてしまったほうが効率が良いといえます。char 型の場合、前述のとおりメモリからレジスタに読み込む LDR 命令でペナルティが発生しますが、int 型ならペナルティが発生しないからです。
除算(割り算)・剰余(余り)をなるべく利用しない
実は、ARM v7aには除算・剰余命令がありません。除算・剰余はシフト演算・減算をループで繰り返すマクロで代用されますが、何サイクルにも及ぶ演算が必要で、効率は非常に悪くなります。何度も演算が行われる部分ではなるべく除算や剰余を利用しないようにすると効果的です。
スライドパズルアプリで除算や乗算を排除した例を1つ挙げます。
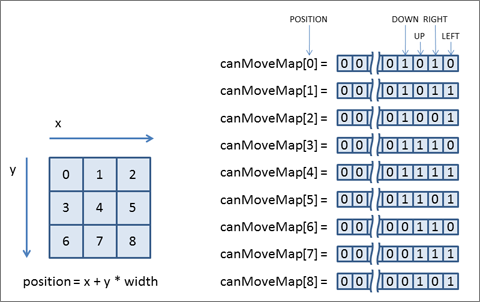
盤面は、図3のように各セルに左上から右下に向けて0~の数値を振って位置を識別しています。盤面の外や壁には移動できないので、移動可能な方向には制限があります。
position を移動の起点、width を盤面の幅とすると、左に移動可能かどうかを調べるには position % width > 0 が true となる必要があります。しかし、この計算には剰余の計算が必要です。
そこで、初期化時にすべての計算を終わらせておくという方法をとりました。図4のような canMoveMap を盤面の初期化時に作成しておき、移動可能かどうかを canMoveMap[position] & 1 << direction) != 0 という判定で行えるようにしています。direction は、LEFT=0,RIGHT=1,UP=2,DOWN=3 です。
移動可否の判定は最も多く行われるオペレーションの1つであるために削減効果は高く、NDK版で1割程度、実行速度が改善しました。このテクニックはNDKだけでなく、Dalvik/ARTでも意識しておくべきものです。
最後に
スマホアプリの開発とチューニングをしていると、時代に逆行しているような感覚にとらわれることがあります。制限事項が多い環境ほど、エンジニアとして基礎力を求められるシチュエーションが多くなります。本稿が、Androidアプリのパフォーマンス不足に悩んでいる方の一助になれば幸いです。


![[GA4] Google Analytics 4 でサイト速度を計測する方法](https://techblog.raccoon.ne.jp/wp-content/uploads/2022/04/00.ga4_sitespeed-500x500.jpg)