そのまま使える、Oracleインデックスのキー圧縮ガイドラインとインデックス設計の話
こんにちは、羽山です。
今回は社内向けに用意していたOracleにおけるインデックスのキー圧縮(接頭辞圧縮)機能の利用ガイドラインに解説を加えて外部公開します。
この機能はインデックスのパフォーマンス改善に対して効果的な一方でガイドラインがないと適切な利用が難しくもあります。そういった場合はぜひこのガイドラインをそのまま活用していただけたらと思います。
また本稿はインデックス設計についても多分に触れているので、キー圧縮機能を学んでいたつもりがインデックス設計にも詳しくなれるというお得な仕様になっています。
キー圧縮(接頭辞圧縮)とは
キー圧縮はインデックス作成時に compress を付与することで利用可能です。
create index インデックス名
on テーブル名 (カラム1, カラム2 ...) compress <integer>;
データの繰り返し値を圧縮することでストレージ容量を節約するもので手軽なので利用している方も多いかと思います。
キー圧縮がうまくいくと1回のI/Oで取得できるレコード数が増加する上にデータベースバッファキャッシュも圧縮状態でキャッシュされるのでその点でも効率が上昇します。ストレージ容量とパフォーマンス両面で恩恵がある機能です。
(※I/Oとパフォーマンスの基礎知識は以前公開したデータベースチューニングの記事を参照ください)
しかしこのインデックスのキー圧縮機能は不適切な設定をするとインデックス容量が増加する場合もあるので全て有効にすればいいわけでもありません。うまく設定すれば恩恵を得られる一方で各開発者が適切な設定を判断することが意外と難しいので、ラクーングループで運用しているDBでも不適切な設定で作成されたインデックスが多数ありました。
そこで開発者がぱっと見てほぼ適切な設定を選択できるガイドラインを今回用意することにしました。
キー圧縮の書式
まずはキー圧縮を有効にする方法とその設定です。
以下書式でインデックスのキー圧縮を行います。
その際に compress 1 のように数値を指定しますが、この数値は先頭から指定された数値分のカラム数だけプリフィックスエントリ(※後ほど説明あり)という領域に保存されることを表します。
-- プリフィックスエントリに保存するカラム数を1で圧縮
create index インデックス名
on テーブル名 (カラム1, カラム2 ...) compress 1;
-- プリフィックスエントリに保存するカラム数を2で圧縮
create index インデックス名
on テーブル名 (カラム1, カラム2 ...) compress 2;
-- キー圧縮をしない(デフォルトの動作)
create index インデックス名
on テーブル名 (カラム1, カラム2 ...) nocompress;
-- 既存インデックスのプリフィックスエントリに保存するカラム数を1に変更
alter index インデックス名 rebuild compress 1;
-- 既存インデックスのキー圧縮を無効化
alter index インデックス名 rebuild nocompress;
詳しい書式はOracleの公式ドキュメントを参照ください。
キー圧縮設定の決定ガイドライン
次に今回定めたガイドラインを公開します。
このガイドラインはあくまで おおむね適切な設定が可能 なもので、データの分布次第では最適でないケースもある点はご了承ください。
完璧な設定を期待するならばキー圧縮機能を熟知した担当者がデータ分布を元に判断する必要がありますが、このガイドラインはそこまでの労力をかけずに わりと適切な設定 を決定することを目的としています。
1. キー圧縮機能について十分な知識を持っていて自ら判断可能ですか?
├ YES: 適切な設定を判断の上で実施してください
└ NO : 次の質問に進む
2. インデックスの対象カラムで絞り込む用途がメインですか?
├ NO : nocompress またはDBに詳しい人へ判断を仰いでください
│ ※ORDER BY狙いのインデックスやカバリングインデックスなど
└ YES: 次の質問に進む
3. ユニークインデックスですか?
├ YES: compress <カラム数 - 1> ※カラムが単数の場合は nocompress
└ NO : 次の質問に進む
4. インデックスの対象カラムは単数ですか?複数ですか?
├ 単数: 同じ値のレコードが4回以上繰り返されることが多いですか?少ないですか?
│ ├ 多い: compress 1
│ └ 少ない: nocompress
│
└ 複数: 全カラム同じ値のレコードが4回以上繰り返されることが多いですか?少ないですか?
├ 多い: compress <カラム数>
└ 少ない: compress <カラム数 - 1>
それでは以降でキー圧縮機能のメカニズムを解説しながらこのガイドラインの理由を解き明かしていきますが、ここから先は基礎的なOracleの知識を要します。読み進める場合は必要に応じて冒頭でもご紹介した、データベースの構造を解説した記事も参考にしてください。
もし手軽にキー圧縮を利用したいだけならばここで閉じても問題ありません。
とはいえ、本心では機能の動作原理を知った方がより適切な利用が可能なので読み進めて理解を深めることをオススメします。
キー圧縮の仕組み
インデックスはツリー構造となっていて枝分かれを表す ブランチブロック とキー値とレコードへのROWIDを保持する リーフブロック で構成されます。今回利用するキー圧縮機能は後者のリーフブロックに作用します。
文字列カラム2つと数値カラム1つに対して作成されたインデックスを例に、まずは キー圧縮を利用しないリーフブロック の論理構造を以下の図に示します。

キー圧縮が行われない場合のリーフブロックの構造は単純でインデックスの対象である 文字列カラム2つ, 数値カラム1つ と テーブルのレコードへのROWID の合計4項目がレコードごとに格納されます。
次は同じインデックスをプリフィックスエントリに保存するカラム数を2(compress 2)として圧縮した状態のリーフブロックの論理構造です。
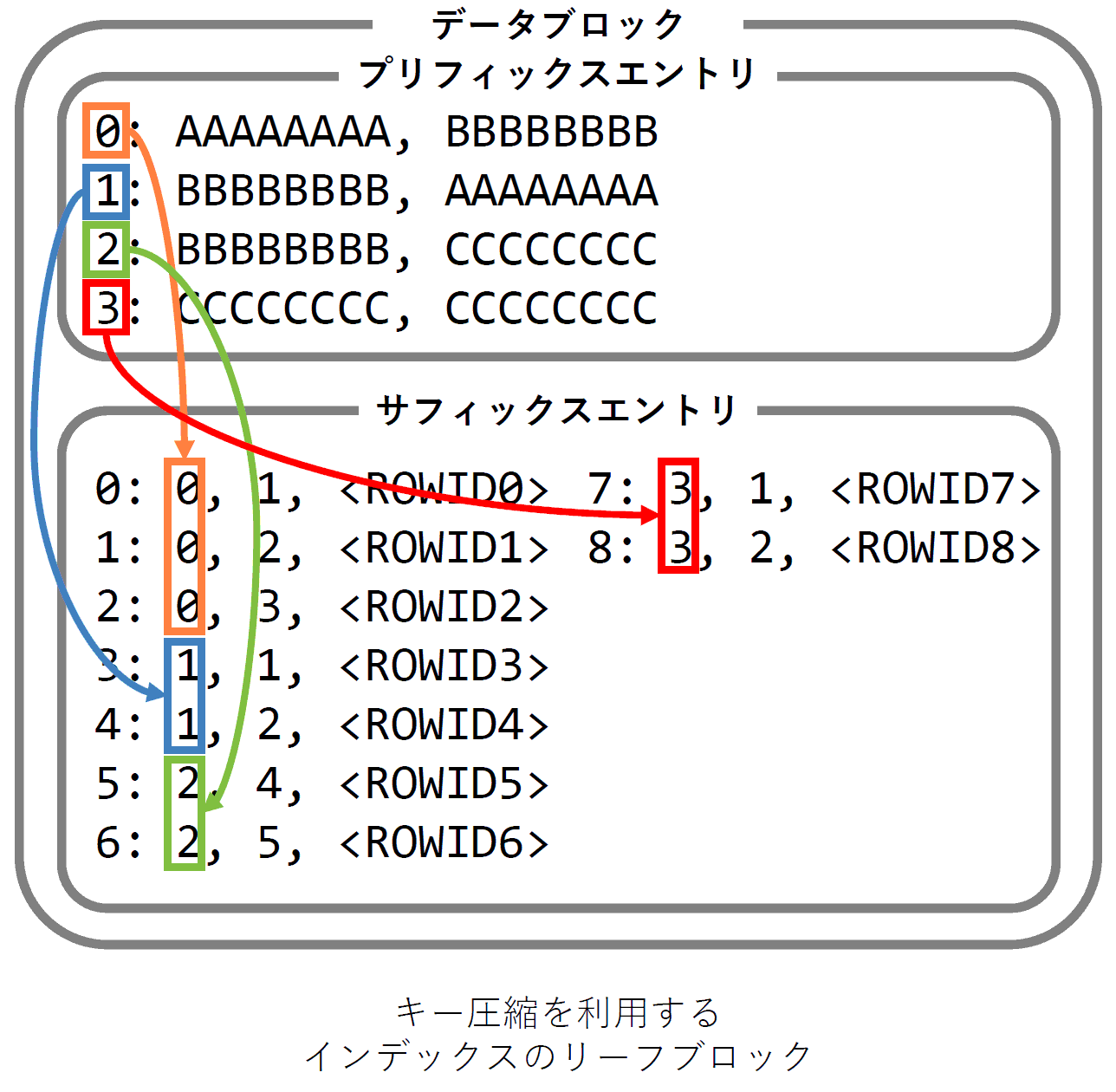
キー圧縮を有効にすると プリフィックスエントリ と サフィックスエントリ に分離されて先頭から指定した数のカラムがプリフィックスエントリに、それ以降のカラムがサフィックスエントリに格納されます。そしてサフィックスエントリからプリフィックスエントリのレコードを参照します。
プリフィックスエントリに格納される値が同一ならば1回だけの記録で済むのでストレージ容量を節約できます。
しかしここで注意点としてプリフィックスエントリは カラムごとに同一の値が登録されるのではなく全てのカラム値がまとめて登録される ということに気をつけましょう。これは重要なのでしっかり意識が必要です。
例えばプリフィックスエントリに2カラム格納する設定(compress 2)でインデックスを作成します。そのデータの分布として先頭のカラムは同じ値が繰り返されているものの次のカラム値がバラバラだったとすると圧縮効果は得られません。この場合はプリフィックスエントリのカラム数を1(compress 1)とするのが最適です。
またこの構造からも分かりますがキー圧縮はデータブロック単位(OracleにおけるI/Oの最小単位)で行われるので圧縮データを復元するためのI/Oは必要ありません。対象データブロックを取得すればCPUとメモリの処理で元データを復元できるのでオーバーヘッドは最小で済みます。
圧縮効果の比較
いくつかのパターンで実際の圧縮率を比べてみましょう。
- 繰り返しのある文字列カラム(単数)
- 繰り返しのある数値カラム(単数)
- 複合インデックス
繰り返しのある文字列カラム(単数)
文字列カラムを1つ持つテーブルを作成して30byteの文字列を1000万レコード挿入しました。登録した文字列は同じ値が5回ずつ繰り返されています。
create table index_compress_test_1 (
id varchar2(30) not null
);
| ID |
|---|
| 000000000000000000000000000001 |
| 000000000000000000000000000001 |
| 000000000000000000000000000001 |
| 000000000000000000000000000001 |
| 000000000000000000000000000001 |
| 000000000000000000000000000002 |
| 000000000000000000000000000002 |
| 000000000000000000000000000002 |
| ... |
| 000000000000000000000002000000 |
| 000000000000000000000002000000 |
次にキー圧縮を利用せずにインデックスを作成します。
create index idx_index_compress_test_1
on index_compress_test_1 (id);
この状態でインデックスのサイズは 472MB となりました。
ではプリフィックスエントリのカラム数を1で圧縮します。
alter index idx_index_compress_test_1
rebuild compress 1;
結果は 208MB となり、56%ほど削減できました。
長い文字列をレコードごとに毎回格納していたのがキー圧縮によって5回に1回の格納で済むようになったのが容量削減の要因です。
繰り返しのある数値カラム(単数)
次は数値カラムを1つ持つテーブルを作成します。
create table index_compress_test_2 (
id number(30) not null
);
このテーブルには以下のように 1 ~ 2000000 の数値が5回ずつ繰り返されるレコードを1000万レコード挿入しました。
| ID |
|---|
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 2 |
| 2 |
| 2 |
| ... |
| 2000000 |
| 2000000 |
まずは先ほどと同様に圧縮を利用せずにインデックスを作成します。
create index idx_index_compress_test_2
on index_compress_test_2 (id);
この状態でインデックスのサイズは 184MB となりました。30byte の文字列に対して作成したインデックスよりもこの時点でだいぶ小さめです。
では以下SQLを実行してプリフィックスエントリのカラム数を1で圧縮します。
alter index idx_index_compress_test_2
rebuild compress 1;
結果は 152MB となり、削減率は17%ほどでした。30byte の文字列のケースより圧縮率は下がっています。
数値は値の保存に必要なバイト数が 30byte の文字列よりも小さいので、圧縮の効果も必然的に低くなります。
圧縮率で数値カラムと文字列カラムを比較すると数値カラムの方が不利です。
しかし一般的に文字列カラムにインデックスを作成するケースは数値カラムと比べると多くないのと、文字列カラムは同一値となるケースがそもそも多くありません。
もし文字列カラムに同一の値が繰り返されている状況があるならば、キー圧縮よりも先にマスタ化や正規化を気にした方が良いかもしれません。
ガイドラインで文字列カラムかどうかを判断材料に入れていないのはこれが理由です。キー圧縮は数値や日時カラムをメインで考えるべきでしょう。
複合インデックス
次は複合インデックスを試してみます。
まずはテーブルを作成します。
以降の解説でも利用するため実践的なテーブルになっています。
-- 注文テーブル
create table orders (
id number(12) not null,
customer_id number(12) not null,
order_date date not null,
shipped number(1) not null,
note varchar2(100)
);
このテーブルに対して以下のINSERT文で1000万件のデータを登録します。
insert /*+ append */ into orders(id, customer_id, order_date, shipped, note)
select
no,
trunc(dbms_random.value * 1000) + 1,
to_date('2020-01-01', 'yyyy-mm-dd') + dbms_random.value * 365,
case when dbms_random.value >= 0.99 then 0 else 1 end,
lpad(to_char(no), 30, '0')
from
(
select
rownum as no
from
(select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
cross join (select 1 from dual union all select 1 from dual)
where
rownum <= 10000000
);
少し脱線しますが Oracle で任意の行数を得る方法はいろいろあり、最もポピュラーなのは以下の connect by を利用した方法でしょうか。
select rownum from dual connect by level <= 1000;
しかしこの方法はレコードの生成過程でメモリに保持する必要があり、膨大なレコードの取得を試みるとメモリ確保に失敗して実行できません。
そこで私がよく使う方法が前述の2行返すテーブル(select 1 from dual union all select 1 from dual)を cross join によるデカルト積で倍々と増やしていく方法です。2の24乗が 16,777,216 で1000万を超えるため、今回は24個結合しています。
確保するメモリが最小で済むので膨大なレコードでもそれに見合う処理時間さえあれば正常に実行可能です。
ただし生成した膨大なレコードに対して実行計画における後続処理でソートしたり別テーブルにハッシュ結合したりすると、その時点で全レコード分のメモリ確保が必要になるので実行に失敗する可能性があります。NESTED LOOP結合などのフィルタ的な処理ならば時間はかかるものの問題ありません。
では話を戻して、各カラムに登録されるデータの概要です。
| カラム | 説明 | カーディナリティ | 値の概要 |
|---|---|---|---|
| id | 注文ID | 最も高い | 1 ~ 10,000,000 の連番 |
| customer_id | 顧客ID | 低い | 1 ~ 1,000 のランダム値 |
| order_date | 注文日時 | 高い | 2020-01-01 00:00:00 ~ 2020-12-31 23:59:59 のランダム値 |
| shipped | 出荷フラグ | 最も低い | 0, 1 ※0は全体の1% |
| note | メモ | 最も高い | id値の先頭を0埋めして30桁とした文字列 |
customer_id はカーディナリティが低いので繰り返し値は多め、一方 order_date は秒の精度で記録されているためカーディナリティが高く9割以上のレコードには同一日時がありません。
カーディナリティとは
あるカラムに格納されるデータの種類数のこと。高い低いで表現し、カーディナリティが高い場合はレコードごとにより異なるデータが保存され、カーディナリティが低い場合は複数のレコードに同じデータが格納される状態を表す。
このテーブルに対して様々な複合インデックスを作成してキー圧縮の効果を試してみました。
| No. | カラム1 | カラム2 | nocompress | compress 1 | compress 2 |
|---|---|---|---|---|---|
| No.1 | customer_id | order_date | 256MB | 210MB (-18%) | 320MB (+25%) |
| No.2 | order_date | customer_id | 256MB | 298MB (+16%) | 320MB (+25%) |
| No.3 | customer_id | shipped | 200MB | 162MB (-19%) | 128MB (-36%) |
| No.4 | trunc(order_date) | customer_id | 256MB | 170MB (-34%) | 136MB (-47%) |
まずは No.1 の customer_id, order_date に対するインデックスです。customer_id はカーディナリティが低めで同じ値のレコードが多いため、customer_id をプリフィックスエントリに保持するように compress 1 とすると容量が18%ほど削減されました。
続いて compress 2 として order_date もプリフィックスエントリに追加すると、order_date はカーディナリティが高いので customer_id, order_date の両カラムが一致するレコードはほとんどなくなってしまい、結果として元のサイズから25%も容量が増加してしまいました。
No2 は No.1 と同じカラムで順番をひっくり返した(order_date, customer_id)インデックスを作成しました。
逆順ではありますが同一カラムが対象なので nocompress の場合のサイズは同一です。(ただしブランチブロックの配置やリーフブロックでのレコードの並び順は大きく異なるので多少の差が出る場合もあります)
続いてキー圧縮を試すと今回は先頭の order_date のカーディナリティが高いので compress 1 の時点で16%も容量が増加してしまいました。
さらに compress 2 で customer_id もプリフィックスエントリに加えると No.1 と同一の25%増となります。2つのカラムの一致は順番が異なっても変わらないのでほぼ同じサイズになります。
No.3 は No.1 と比較用に2カラム目をカーディナリティの低い shipped カラムに変更してみました。
compress 1 の対象カラムは No.1 も No.3 も同じ customer_id なので当然データ分布は同一、そのためインデックスサイズの削減率もほぼ同じで18 ~ 19%程度となっています。
注目すべきは compress 2 とした場合です。No.1 はカーディナリティの高い order_date だったので容量が増加してしまったのに比べ、No.3 の shipped は値の種類が 0, 1 だけとカーディナリティが低いので -36% となり compress 1 よりさらに容量が削減されています。
No.4 はファンクションインデックスを使って order_date の時刻を 00:00:00 に丸めた状態でインデックスを作成しています。
以下のような任意の1日での絞り込みや日の範囲検索に利用可能です。
select
*
from
orders
where
trunc(orders.order_date) = to_date('2020-10-10', 'yyyy-mm-dd');
では No.4 と No.2 を比べてみます。対象カラムおよび順番は同一ですが、No.2 は order_date に時刻がそのまま入っていて、No.4 は時刻が 00:00:00 に丸められています。
キー圧縮無効では両インデックス共に 256MB で同じサイズになりました。No.4 は時刻情報を丸めているだけでDate型自体の精度や保持に必要なサイズが変化しているわけではないので納得の結果です。
次の compress 1 では大きな差が出ています。order_date をそのままプリフィックエントリに保存した No.2 は元のサイズから 16% も増加したのに対して、時刻を丸めた No.4 は 34% 削減されています。時刻を丸めるとカーディナリティが低くなるのでこれも納得の結果です。compress 2 で customer_id がプリフィックスエントリに追加されると差がさらに大きくなります。No.2 は order_date だけでも同じ値のレコードが少なかったのに、そこに customer_id が加わるとさらに状況が悪化します。
ガイドラインの解説
それではここまでの知識を元にガイドラインに戻ってみましょう。
最初の「キー圧縮機能について十分な知識を持っていて自ら判断可能ですか?」については、このガイドラインの不完全さを表しています。
やはりキー圧縮機能とデータ分布を熟知している開発者が適切に判断をすることができる状況ならそれがベストです。
次の「インデックスの対象カラムで絞り込む用途がメインですか?」は後で解説するので、ここでは絞り込みを目的としたインデックスを前提とします。
3. ユニークインデックスですか?
├ YES: compress <カラム数 - 1> ※カラムが単数の場合は nocompress
└ NO : 次の質問に進む
まずユニークインデックスです。ユニークインデックスは対象カラム全体で一意となるので全てのカラムをプリフィックスエントリに保存してしまうと繰り返しは全くなくなります。それでは無駄なのでプリフィックスエントリに保存するカラム数として設定可能なのは最大で「カラム数 - 1」です。
絞り込みを目的とした複合インデックスは途中のカラムのカーディナリティを低くしないとそれ以降のカラムでの絞り込みにインデックスが有効に機能しません。
その理由を先ほどの orders テーブルに対する order_date, customer_id の複合インデックスで考えてみます。
データの分布は以下の通りです。
- customer_id: カーディナリティ低、1 ~ 1,000 のランダム値
- order_date: カーディナリティ高、2020-01-01 00:00:00 ~ 2020-12-31 23:59:59 のランダム値
| 検索パターン | 検索条件 | 適正 |
|---|---|---|
| (A) | order_date の単一値 | ◎ |
| (B) | order_date の単一値 かつ customer_id の単一値 | ◎ |
| (C) | order_date の単一値 かつ customer_id の範囲 | ◎ |
| (D) | order_date の範囲 | ◎ |
| (E) | order_date の範囲 かつ customer_id の単一値 | ○ |
| (F) | order_date の範囲 かつ customer_id の範囲 | ○ |
| (G) | customer_id の単一値 | × |
| (H) | customer_id の範囲 | × |
order_date の単一値検索(パターンA~C)は全てのケースで最大の適正がありますが、範囲検索(パターンD~F)になると適正なのは order_date のみに対する範囲検索(D)に限定されます。
例えばパターン(E)の「order_date の範囲 かつ customer_id の単一値」の動作を考えると、指定された order_date の範囲すべてを INDEX RANGE SCAN した上で条件に含まれる customer_id のレコードをピックアップすることになるので、customer_id の絞り込みについては効率が良いとは言えません。とはいえ次点の○適正となっているのは INDEX RANGE SCAN でヒットしたレコードに対してそれぞれROWIDでテーブルからデータを取得するよりはインデックス内にデータがあった方が速いためです。しかしこれは以降で解説するカバリングインデックスに近い使い方なので基本的なインデックス設計の範囲を少し逸脱しています。
次に(A)~(C)の order_date の単一値検索ですが、インデックスの適正としては確かに◎なのですが order_date はカーディナリティが高いので customer_id もインデックスに含める必要性はさほどありません。
利用頻度の高いであろう order_date の範囲検索も普通に設計したら前述の通り customer_id はインデックスに追加されないことが多いです。
つまり対象とするインデックスが普通に設計されているならば「カラム数 - 1」の設定でほぼ理想的な結果が得られることになります。
より高度なパフォーマンスチューニングを目的として設計されたインデックスの場合は「カラム数 - 1」では適正値を得られなくなりますが、そのようなインデックスを設計する開発者にはキー圧縮の設定も含めて適切に設定できることを期待しましょう。
では次は非ユニークインデックスです。
4. インデックスの対象カラムは単数ですか?複数ですか?
├ 単数: 同じ値のレコードが4回以上繰り返されることが多いですか?少ないですか?
│ ├ 多い: compress 1
│ └ 少ない: nocompress
│
└ 複数: 全カラム同じ値のレコードが4回以上繰り返されることが多いですか?少ないですか?
├ 多い: compress <カラム数>
└ 少ない: compress <カラム数 - 1>
非ユニークインデックスは対象カラムに対して同一値の繰り返しがあるので、キー圧縮の設定は全てのカラムをプリフィックスエントリに保存するように指定することができます。
一方で非ユニークインデックスには様々なユースケースがあるので繰り返しが多いデータもあれば、実質的にはほとんどユニークに近いデータ分布の場合もあります。
こればかりは画一的な決定が難しいのでガイドラインでは実際のデータを元として繰り返しが概ね4回より多そうなら全カラムをプリフィックスエントリに保存し、4回未満なら「カラム数 - 1」として最後のカラムをプリフィックスエントリから除外しています。
「カラム数 - 1」なのは上記のユニークインデックスで書かれた理由と同一で、通常のインデックス設計では最後のカラム以外はカーディナリティが低くなることが多い(=データの繰り返しが多い)からです。
要するに非ユニークインデックスでの悩みどころは、最後のカラムをプリフィックスエントリに加えるべきか否かというだけです。
では次に「インデックスの対象カラムで絞り込む用途がメインですか?」の解説ですが、これはORDER BY狙いのインデックスやカバリングインデックスが該当します。
ORDER BY狙いのインデックス
ORDER BY狙いとはなにか考えてみます。
先ほどの注文テーブルとそのデータを利用します。
-- 注文テーブル
create table orders (
id number(12) not null,
customer_id number(12) not null,
order_date date not null,
shipped number(1) not null,
note varchar2(100)
);
この注文テーブルから注文日の新しい順に100件取得したい場合は以下のSQLになります。
select
*
from
(
select
*
from
orders
order by
order_date desc,
id desc
)
where
rownum <= 100;
細かい点ですが、並び順の指定で order_date だけではユニークにならないので、ここでは id も追加しています。
ユニークになるカラムまで指定しないと同一値だった場合の順番が未定義となるので、システムで利用する場合に問題が発生することがあります。
この場合の実行計画は以下です。
注文日の逆順を取得するには当然ながら全レコードを取得した上でソート処理が必要になります。
SELECT STATEMENT Cost = 3
COUNT STOPKEY
VIEW
SORT ORDER BY STOPKEY
TABLE ACCESS FULL ORDERS
ここで order_date, id に対する複合ユニークインデックスを作成します。
-- 注文日(order_date)とidにインデックス作成
create unique index idx_orders_order_date
on orders (order_date, id);
インデックス作成後にもう一度同じSQLの実行計画を取得すると以下のように変化します。
SELECT STATEMENT Cost = 1
COUNT STOPKEY
VIEW
TABLE ACCESS BY INDEX ROWID ORDERS
INDEX FULL SCAN DESCENDING IDX_ORDERS_ORDER_DATE
テーブルフルスキャンとソート処理がなくなって代わりに INDEX FULL SCAN DESCENDING が登場しています。
先ほど作成したインデックスの逆順が今回のSQLで指定されている order_date desc, id desc と一致するので、インデックスを最後の要素から逆順に取得すればソートが不要になるのです。
INDEX FULL SCAN となっていますが COUNT STOPKEY によって100行取得したら処理が中断するので実際にはフルスキャンされません。
ではこの ORDER BY 狙いのインデックスへキー圧縮を適用してみます。
| No. | カラム1 | カラム2 | nocompress | compress 1 | compress 2 |
|---|---|---|---|---|---|
| No.5 | order_date | id | 264MB | 312MB (+18%) | ---MB (---%) |
ORDER BY 狙いのインデックスは最初のカラムが主な並び順を決定する日付などカーディナリティの高いカラムであることが多く、安易にキー圧縮すると逆効果になります。
今回のケースでは order_date のカーディナリティが高いので compress 1 で 18% もサイズが増加してしまいました。2カラムのユニークインデックスのため compress 2 は設定できません、このインデックスの場合は nocompress が最適です。
さらに複雑なケースでは ORDER BY と絞り込みの両方を狙うこともあって画一的な判断を難しくしています。
例えば検索条件に shipped = 1 を追加して「出荷済みの最新100件」を取得する要件ならば、shipped, order_date, id 3カラムの複合インデックスを設計することもあり、その場合の最適な圧縮設定は shipped だけをプリフィックスエントリに保持する compress 1 です。
カバリングインデックス
次はカバリングインデックスを考えます。
以下のSQLは2020年10月1日の顧客ごとの注文数を取得しています。
select
customer_id,
count(*)
from
orders
where
order_date >= to_date('2020-10-01', 'yyyy-mm-dd')
and order_date < to_date('2020-10-02', 'yyyy-mm-dd')
group by
customer_id;
インデックスがないと当然テーブルフルスキャンになります。
SELECT STATEMENT Cost = 21480
HASH GROUP BY
TABLE ACCESS FULL ORDERS
次に order_date にインデックスを作成します。
普通に設計したら大抵の方はこのインデックスを作ると思われます。
create index idx_orders_order_date
on orders (order_date);
すると実行計画は以下のように変化しました。
まずは INDEX RANGE SCAN でインデックスから対象行のROWIDを取得。次にROWIDでテーブルからレコードを取得した上でグループ化するという内容で、これは十分に効果的なインデックスです。
SELECT STATEMENT Cost = 9028
HASH GROUP BY
TABLE ACCESS BY INDEX ROWID ORDERS
INDEX RANGE SCAN IDX_ORDERS_ORDER_DATE
では次は customer_id もインデックスに加えてインデックスを作り直してみます。
create index idx_orders_order_date
on orders (order_date, customer_id);
すると以下のような実行計画になり、テーブルからのデータ取得が必要なくなりました。
SELECT STATEMENT Cost = 31
HASH GROUP BY
INDEX RANGE SCAN IDX_ORDERS_ORDER_DATE
インデックスはテーブルの持つデータのコピーなのでインデックスに含まれるカラムだけで必要なデータを取得できるならばテーブルへのアクセスが必要なくなり、パフォーマンスがさらに上昇します。
しかしこのカバリングインデックスへキー圧縮を適用すると、複合インデックスの途中のカラムでもカーディナリティが高いことが多いので「カラム数 - 1」では最適な設定にならないケースが大半です。
ファンクションインデックスを利用したデータ削減手法
最後に少々トリッキーなインデックスを紹介します。
trunc(order_date) でカーディナリティを下げてキー圧縮効率を上昇させる例を紹介しましたが、その応用です。
まずは30桁の文字列カラムを1つだけ持つテーブルを定義して、一意の値を1000万レコード挿入します。
create table function_index_test (
id varchar2(30) not null
);
実際のレコードは以下のようになっています。
| ID |
|---|
| 000000000000000000000000000001 |
| 000000000000000000000000000002 |
| 000000000000000000000000000003 |
| ... |
| 000000000000000000000000030002 |
| 000000000000000000000000030003 |
| ... |
| 000000000000000000000009999999 |
| 000000000000000000000010000000 |
この時点でテーブルのサイズは 400MB になりました。
create unique index idx_function_index_test
on function_index_test(id);
次にユニークインデックスを作成すると 456MB でした。
元のテーブルは 400MB でしたが、インデックスは全く同じデータを持つものの B+Tree 構造で容量が多少増加しています。
では擬似的に2カラムに分割したファンクションインデックスを compress 1 で作成します。
create unique index idx_function_index_test
on function_index_test(
substr(id, 1, 28),
substr(id, 29)
) compress 1;
| ID | SUBSTR(ID, 1, 28) | SUBSTR(ID, 29) |
|---|---|---|
| 000000000000000000000000000001 | 0000000000000000000000000000 | 01 |
| 000000000000000000000000000002 | 0000000000000000000000000000 | 02 |
| 000000000000000000000000000003 | 0000000000000000000000000000 | 03 |
| ... | ... | ... |
| 000000000000000000000000030002 | 0000000000000000000000000300 | 02 |
| 000000000000000000000000030003 | 0000000000000000000000000300 | 03 |
| ... | ... | ... |
| 000000000000000000000009999999 | 0000000000000000000000099999 | 99 |
| 000000000000000000000010000000 | 0000000000000000000000100000 | 00 |
このインデックスはSUBSTR関数で先頭28文字と最後の2文字に分割しています。
キー圧縮はファンクションインデックスで作られたカラムにも有効で、この場合は先頭28文字のカラムは100回ずつ繰り返されるので圧縮効果は高いはずです。
実際にこのインデックスのサイズは 152MB でした。元のインデックスが 456MB だったことを考えると劇的にサイズが削減されている上に、元テーブルの 400MB と比べても半分未満になりました。
検索時に28文字と2文字に分離が必要など扱いは少し面倒ですが、このファンクションインデックスを利用してカバリングインデックスとして利用するとI/O効率が上昇します。
-- 000000000000000000000000030 から始まるキーを検索
select
substr(id, 1, 28) || substr(id, 29) as id
from
function_index_test
where
substr(id, 1, 28) like '000000000000000000000000030%';
SELECT STATEMENT Cost = 35
INDEX RANGE SCAN IDX_FUNCTION_INDEX_TEST
SELECT で取得する値もファンクションインデックスで分割された2カラムを結合(substr(id, 1, 28) || substr(id, 29))しているので、元テーブルにはアクセスせずに取得可能です。
元テーブルを完全に再現可能なカバリングインデックスが元テーブルの半分以下のサイズとなるのは面白い現象です。
まとめ
今回はキー圧縮機能のガイドラインから始まって、機能の背景とさらにインデックス自体の解説でした。
キー圧縮機能は知ってみると意外と考えることも多く奥深い機能だったのではないでしょうか。またインデックス設計についての気づきも提供できていたらなと思っています。
本稿の内容は元々ラクーングループ内で利用するガイドラインとして用意を始めた資料だったのですが、キー圧縮機能は Oracle を利用するどの環境でも有用なものなので外部公開用に書き直して公開しました。
ぜひ活用されていない方は本ガイドラインを元にキー圧縮機能デビューしてみていただけたらと思います。