理屈で考える、データベースのチューニング
こんにちは、羽山です。今回はOracleデータベースのチューニングで少し踏み込んだ内容です。途中で比較対象としてMySQLも登場します。
日頃からSQLチューニングの機会があってそれなりに得意としているのに、それでもなぜかパフォーマンスがでないSQLに悩んだ経験はありませんか?
謎の遅い現象は特に大規模データベースになってくると発生しがちなのですが、速い場合も遅い場合も必ず理由があります。そこで本記事ではデータベースのチューニングにおいて意外と見落とされがちなローレベルな部分に着目して、さらに一歩上のパフォーマンスチューニングに必要な知識を解説します。
この記事を書くきっかけとなったのは私たちの運営する仕入れのECサイト スーパーデリバリーでした。
すでにオープンから18年間ほど経過しており、それなりのデータ量があります。
今現在最もレコード数の多いテーブルで3億レコード以上あり、しっかりとパフォーマンスを意識した処理と設計をしないとたちどころに破綻します。
スーパーデリバリーをはじめとしたラクーングループの各事業はITを活用したサービスが中心のため昨今のコロナ禍で需要が伸びています。
そうなると増えてくるのがDBの負荷ですが、今年の6月頃に速度や負荷に関する様々な監視項目が一斉に悲鳴をあげはじめたことから、最優先課題としてここ3ヶ月間ほど負荷軽減施策を集中して実施していました。
その結果DBの負荷は6月時点から1/3にまで減少することに成功し当面は安心できる状態になりました。しかしこのままなにもしなければまた徐々にDB負荷が増えていくことは必然です。
そこで開発メンバーのDBパフォーマンスに対する知識を底上げするために勉強会を開催する運びとなり、当記事はその資料の公開と簡単な解説を加えたものです。
理屈で考える、データベースチューニング スライド (SpeakerDeck)

はじめに
今回の主題は 「内部構造を知る」 です。
一般にパフォーマンス界隈では「推測するな、計測せよ」と言われることが多いですが、実は私自身はこの言葉を尊重しつつも「推測」を優先することが多々あります。
なぜならば今現在のようにシステムを取り巻く環境の高度化・複雑化が進んだ状況では、生半可な「計測」では逆に問題の本質が掴みにくくなることがあるからです。
そこで重要なのは内部構造(アルゴリズム・データ構造)を知り正しく推測することです。計測は推測の実証手段として最後に行います。
特にDBは魔法のチューニング機能の塊で、表面的な「計測」では問題の尻尾をなかなか掴ませてくれません。
あるSQLを実行すると最初は遅かったような気がするけど、以降の実行は瞬時に終わるのでパフォーマンスに問題はないと考えてしまうなど、心当たりはありませんか?
ストレージの性能を知る
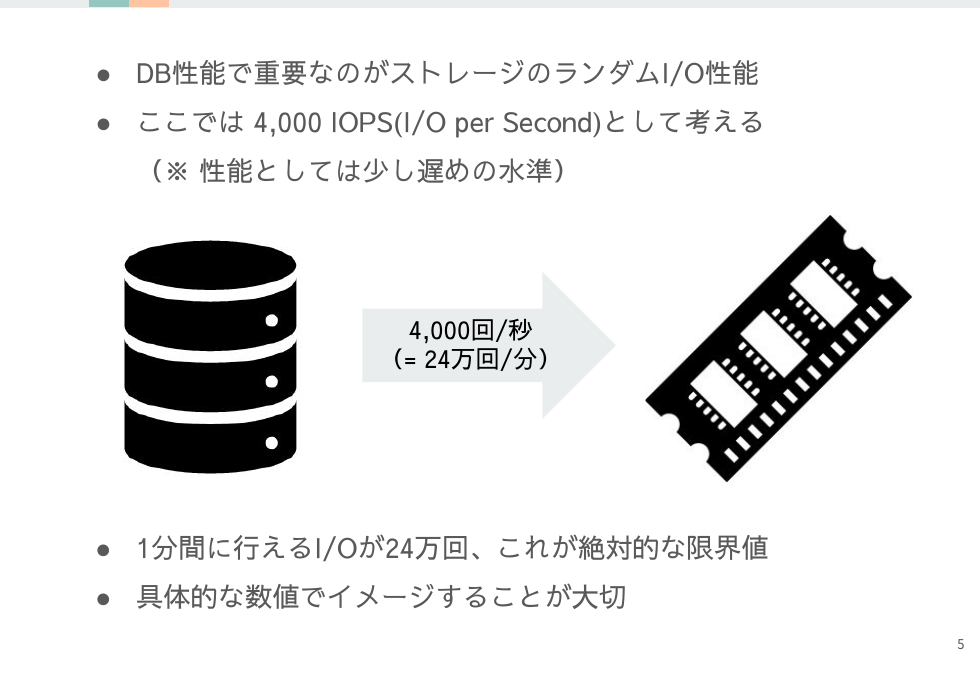
ストレージはDB性能を評価するファクターとして最も重要です。
その性能を大まかでもいいので具体的な数値で、どれくらいのI/Oを行えるのかをイメージすることが大切です。
DBで発生するのはランダムI/Oが中心、そしてI/Oの回数であるIOPSが最も性能を表しやすい指標です。
なぜDBの内部構造の理解が必要か?

負荷の高いSQLを分析すると、テーブルフルスキャンが潜んでいることはありがちです。
順不同で並んだ英和辞典を渡されて単語を探してくださいと言われたら苦行ですよね。しかしDBには平気でそんな処理が流れてきます。
DBの立場になって自分が手作業で処理することを考えると、いかにその処理が遅いのかの理解がしやすくなります。
データブロックを理解する
テーブルデータの保存先を考えると表領域・セグメント・エクステントなどの複雑な単語がでてきますが、覚えておく必要があるのはデータブロックだけです。
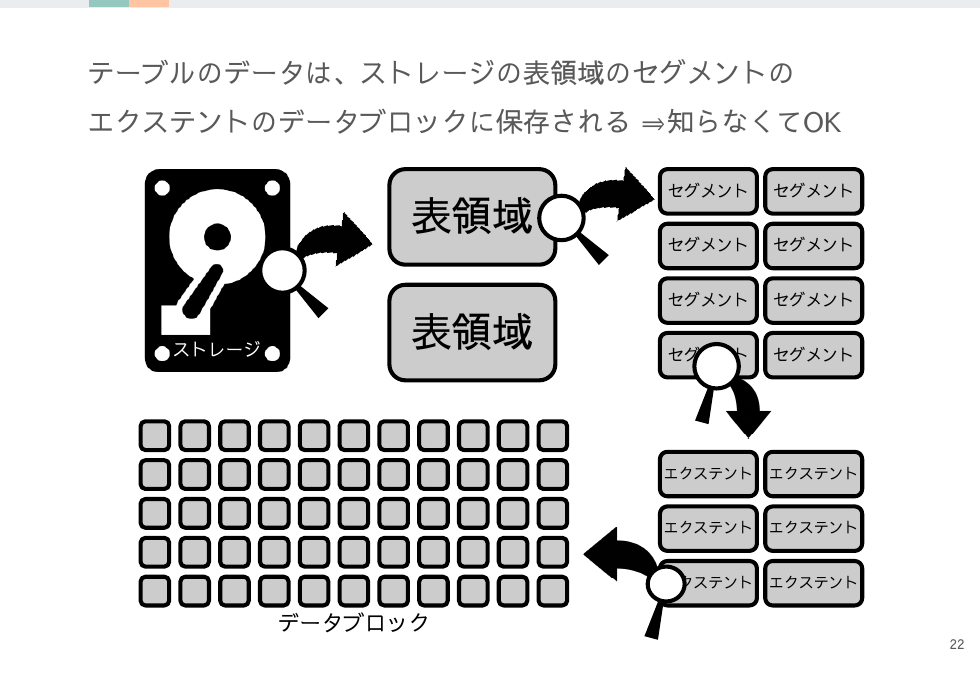
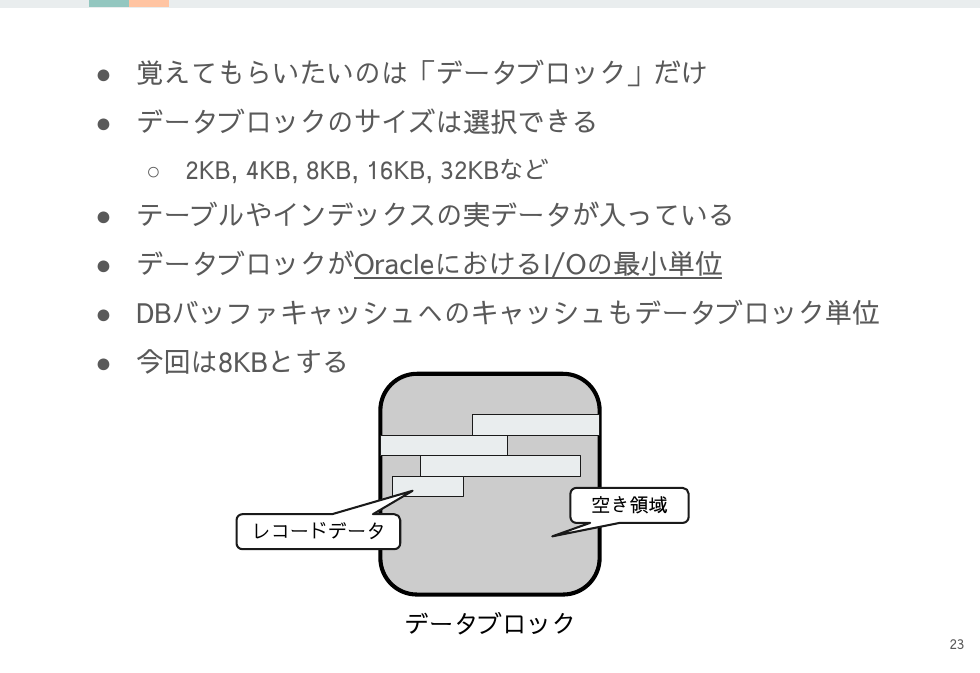
データブロックはOracleにおけるI/Oの最小単位で基本的にこの単位でI/Oが発生します。(ただしマルチブロックリードなどの例外はある)
さきほどストレージの性能としてはIOPSを考えましょうと書いた理由がここにあります。
Oracleはデータブロック単位でI/Oを行うので、ブロックサイズを8KBにすると 4,000 IOPSの性能を持つストレージからは以下の容量を読み込めることになります。
- 1秒間 ⇒ 8KB × 4,000 IOPS ≒ 32MB
- 1分間 ⇒ 32MB × 60秒 = 1,920MB ≒ 2GB
1分間で2GBという数値は思ったより遅い印象ではないでしょうか?ランダムI/OでIOPSから計算すると実は読み込めるのはこの程度なのです。
そしてテーブルから1レコードを取得する際にOracleが実行しているのは「必要なデータブロックを1つストレージから読み込む」ということです。
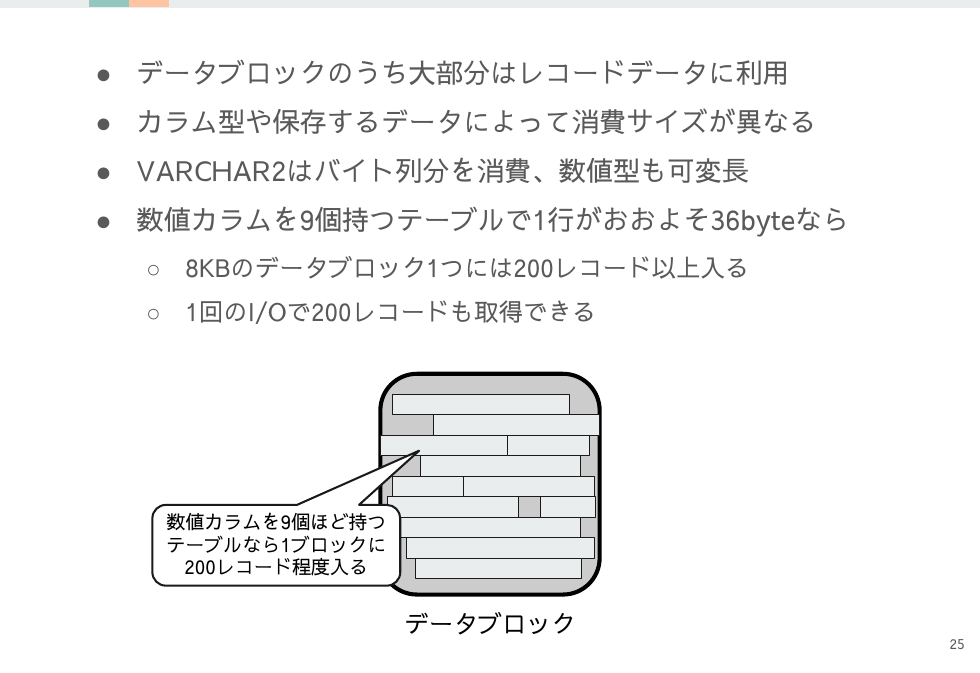
データブロックのうち大部分の領域は当然レコードの実データの記録に利用されます。
カラムの型や保存内容によりますが、大抵の型は可変長で必要分量だけ消費します。
例えば数値カラムを9個持つテーブルの場合は1レコードがおおよそ36byte程度で8KBのデータブロック1つには200レコードほど入ります。
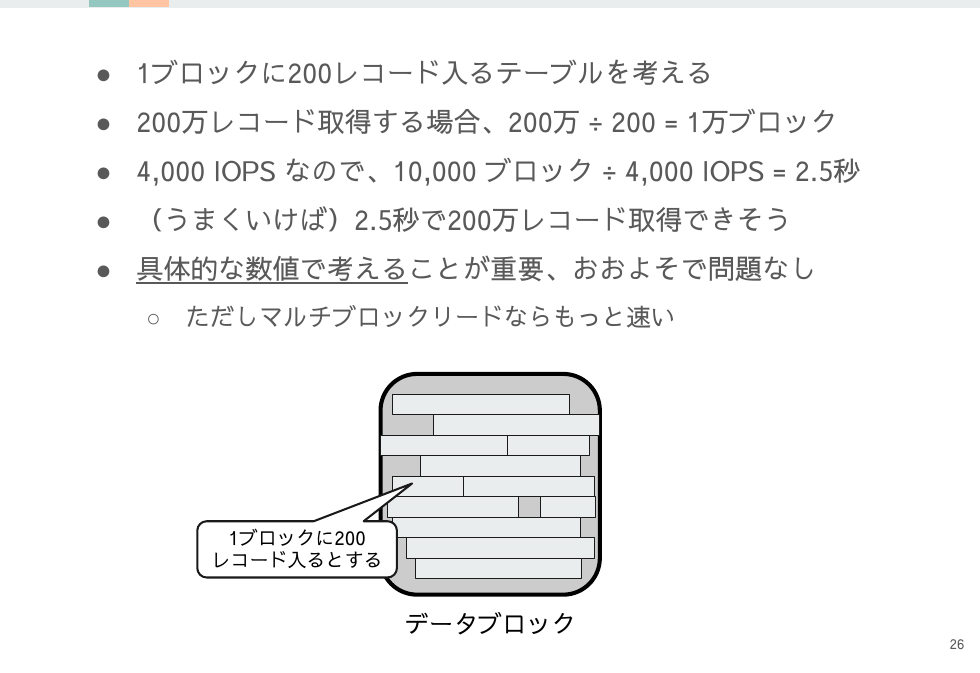
厳密に把握する必要はありませんが、1ブロックに200レコード入るのか、50レコード程度なのか、もしくは2レコードしか入らないのかなど、ざっくりと状況を把握することが大切です。
例えばあるテーブルから200万レコード読み込む場合を考えてみます。
1ブロックに200レコード入る場合
- 200万レコード ÷ 200 = 1万ブロック
- 1万ブロック ÷ 4,000 IOPS = 2.5秒
1ブロックに50レコード入る場合
- 200万レコード ÷ 50 = 4万ブロック
- 4万ブロック ÷ 4,000 IOPS = 10秒
1ブロックに2レコード入る場合
- 200万レコード ÷ 2 = 100万ブロック
- 100万ブロック ÷ 4,000 IOPS = 250秒
1ブロックに入るレコード数によって2.5秒で終わることもあれば250秒かかることもあり、100倍も違うのでこれはパフォーマンスを考える上で外せません。
ここで1つ問題

設問の状況の場合にパフォーマンスの差がでるかどうかわかりますか?
両方ともインデックスによる範囲スキャンが可能で、取得するレコード数もほぼ同等という条件です。

答えは「1. 2019年5月の注文」の方が早く取得可能です。
なぜ速度に差がでるのかを理解するにはデータブロック内の必要なレコードの分散状況が鍵となります。
同時期にINSERTされたレコード達は同じデータブロックに入っている可能性が高いので、INSERTタイミングと相関のある条件である「注文日」の方が読み込むブロック数が少なくなります。
この例では1ブロック取得で200レコード取得できる注文日の絞り込みと、1ブロック取得で1~2レコードしか取得できないジャンルでの絞り込みでは100倍くらいのパフォーマンス差があります。
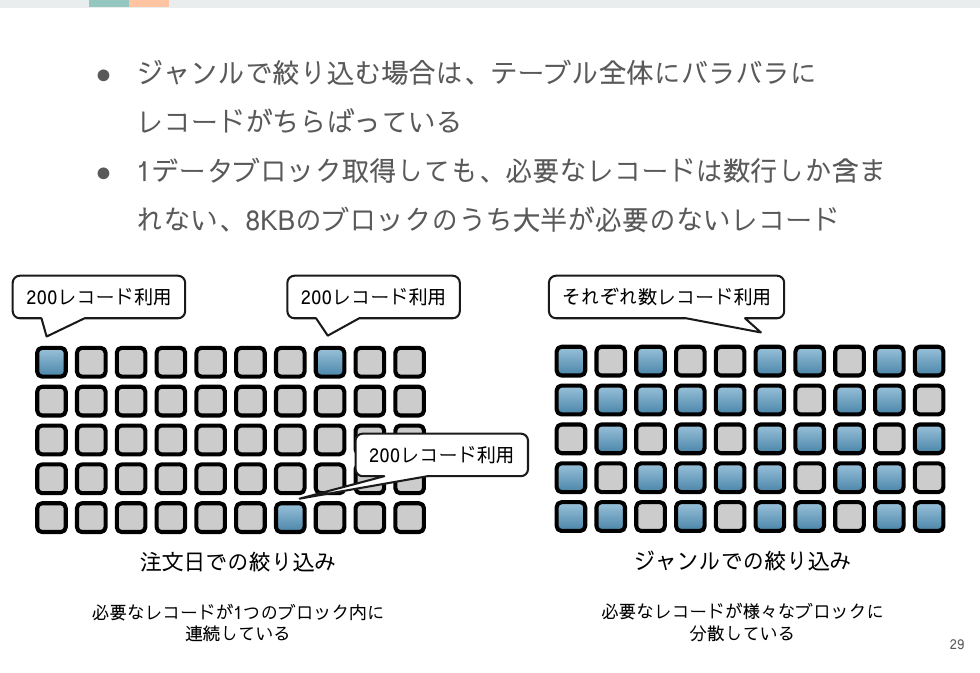
レコードがINSERTされるタイミングは実はこれほどまでにパフォーマンスに関わってきます。
Oracleは基本的に最初にINSERTされたブロックからデータを移動しないので、ブロック内の隣人になるレコードは半永久的に同タイミングにINSERTされたレコードとなります。
データブロックの使用可能と使用済みの状態遷移
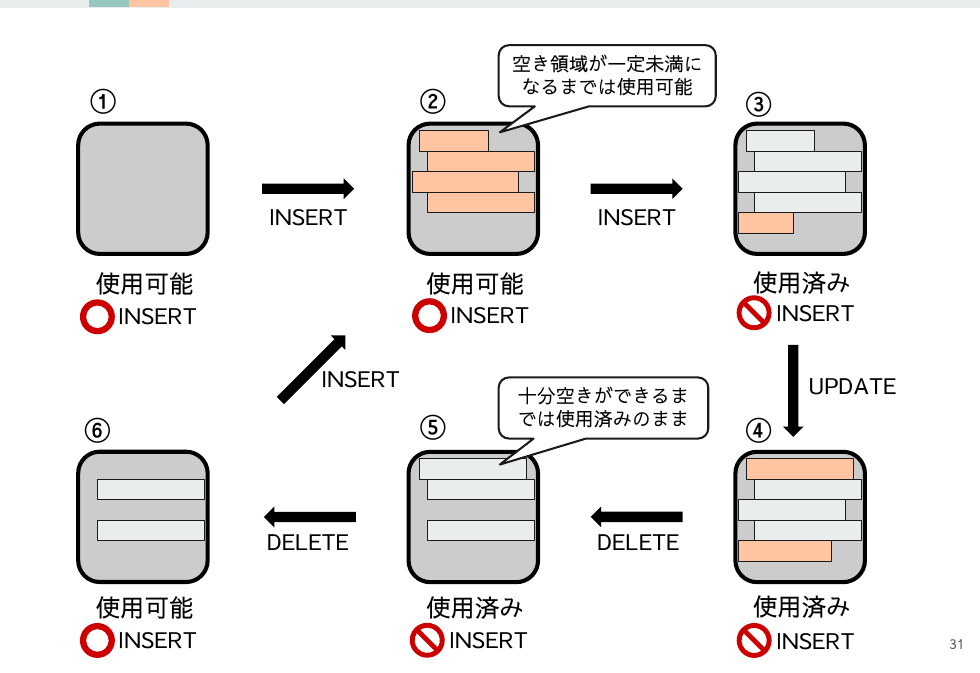
DELETEが頻繁に行われるテーブルだと空き領域が断片化してINSERTされるブロックはバラバラになるのではと疑問を持つかもしれませんが、その点についてもOracleはしっかり考慮されています。
データブロックには「使用可能」と「使用済み」という状態があり、INSERTは「使用可能」なブロックにのみ行われます。
そして一度「使用済み」になったブロックはある程度の大きな空き領域ができるまでは「使用済み」のままになります。これにより「使用可能」になったタイミングではある程度の空き容量が保証されるのです。
- 「使用可能」ブロックにINSERT可能
- 残り10%など一定容量未満になると「使用済み」になってINSERT不可
- 十分に空くまでは「使用済み」のまま
- 十分に空くと再び「使用可能」となってINSERTが可能になる
ブロックサイズとIOPSとスループット
では次は具体的なデータブロックのサイズについて考えてみます。
単純にスループットだけで考えると、ブロックサイズが大きくなるほどスループットも上昇します。
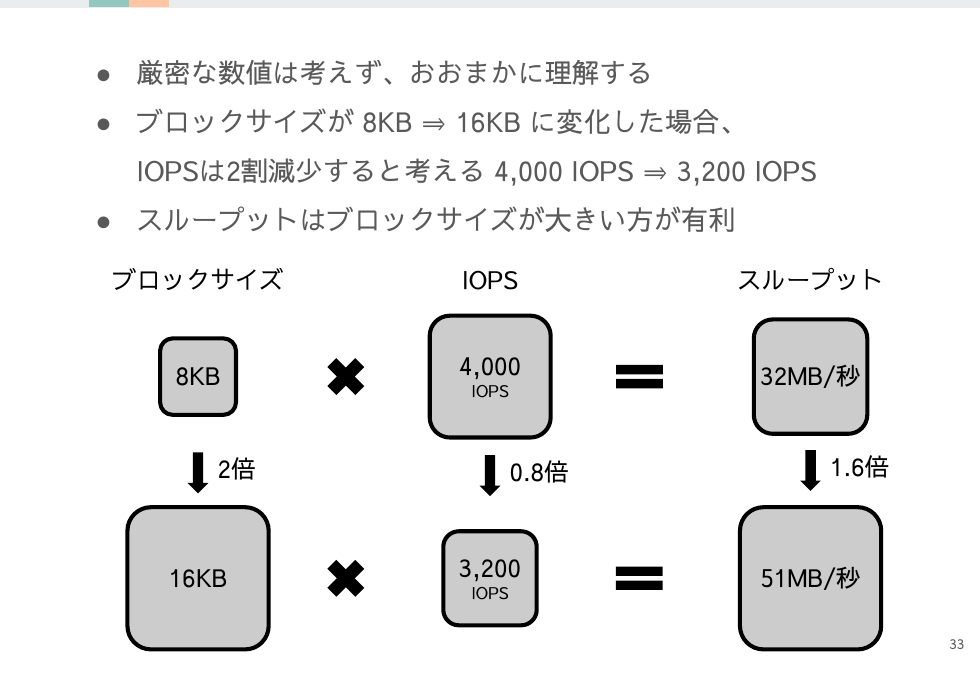
では、ブロックサイズが大きい方が有利なのかと言えばそうではありません。
まずはブロックサイズが大きい場合を考えてみましょう。
大きいブロックサイズの考察
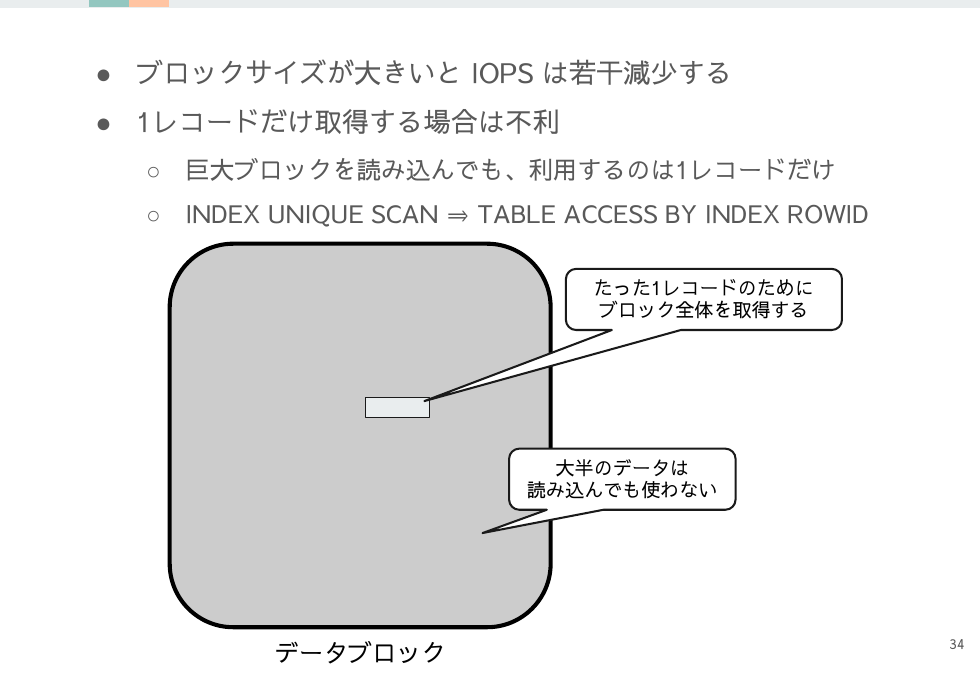
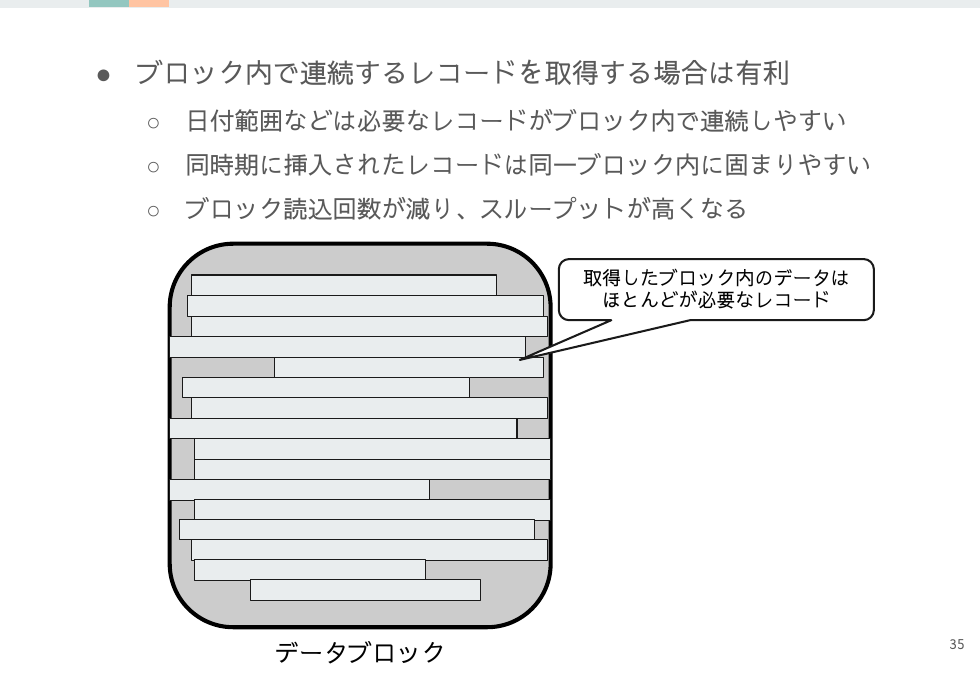
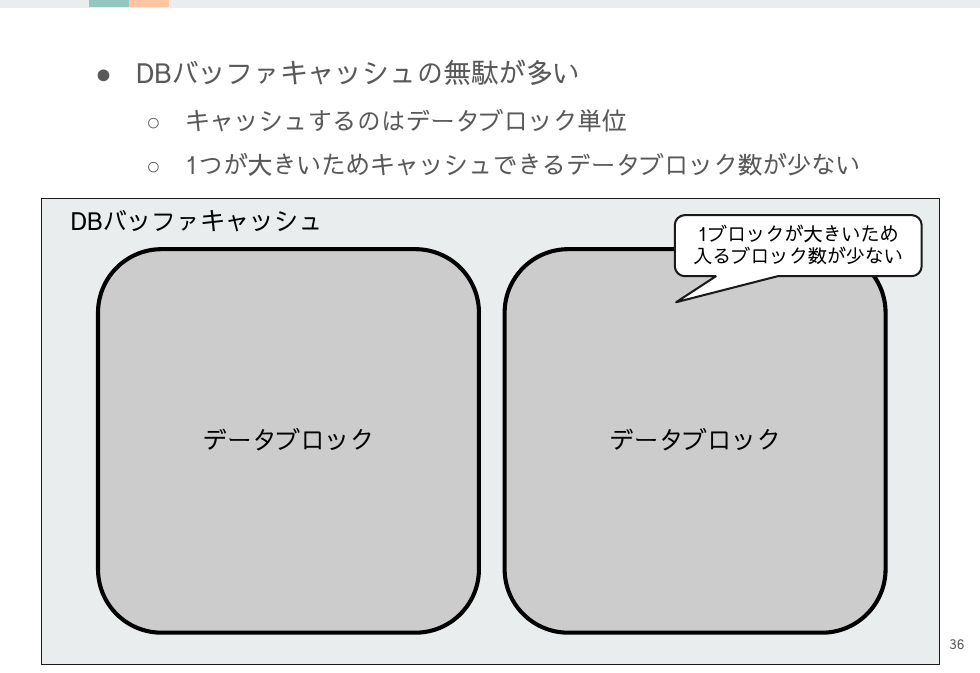
データブロック取得のスループットが増加するのはいいのですが、ブロック内に必要なレコードが少ない状況だと大半は無駄なデータとなってスループットは低くなります。
また大きなサイズのままDBバッファキャッシュに入るので、キャッシュの利用効率が悪い点も大きなデメリットです。メモリが潤沢ならばカバーできますがそういう恵まれた状況は少ないでしょう。
一方でブロック内に必要なレコードが連続している場合は全てのデメリットはメリットに転じます。
では、次はブロックサイズを小さくした場合を考えてみます。
小さいブロックサイズの考察
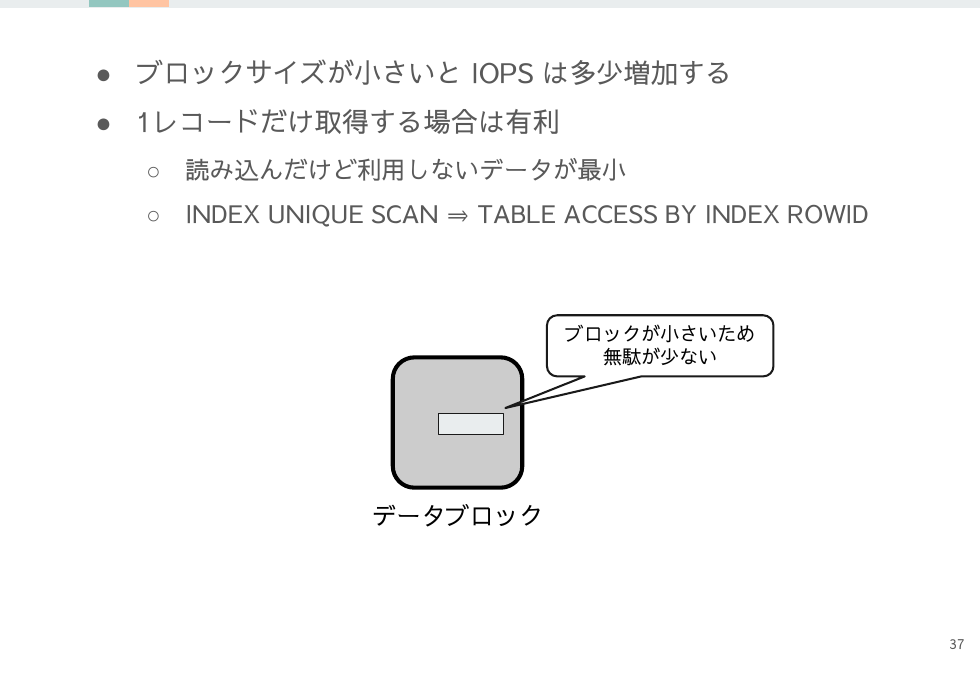
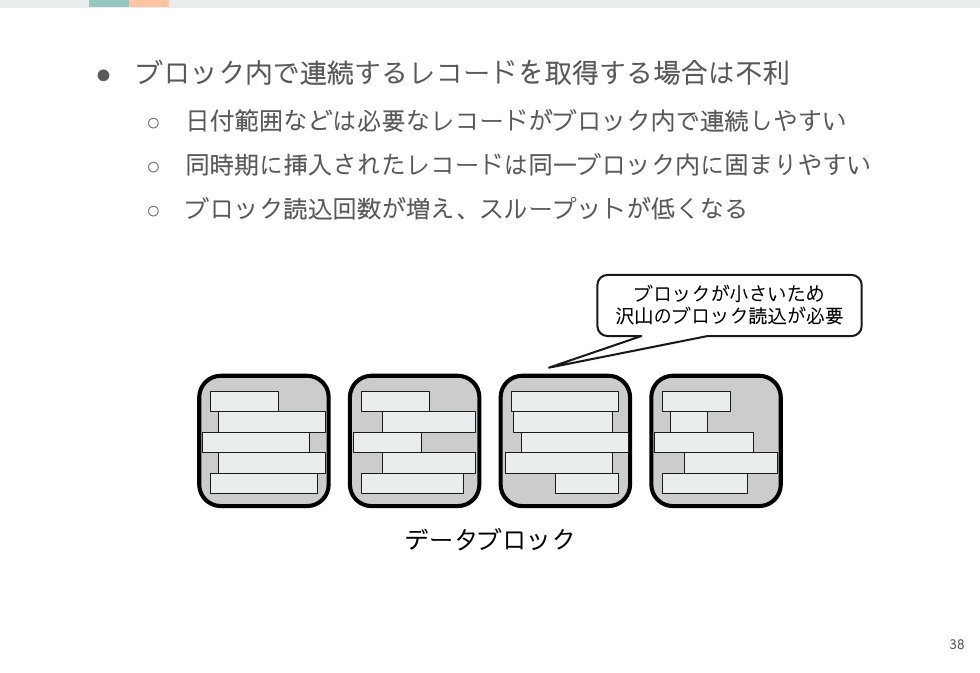
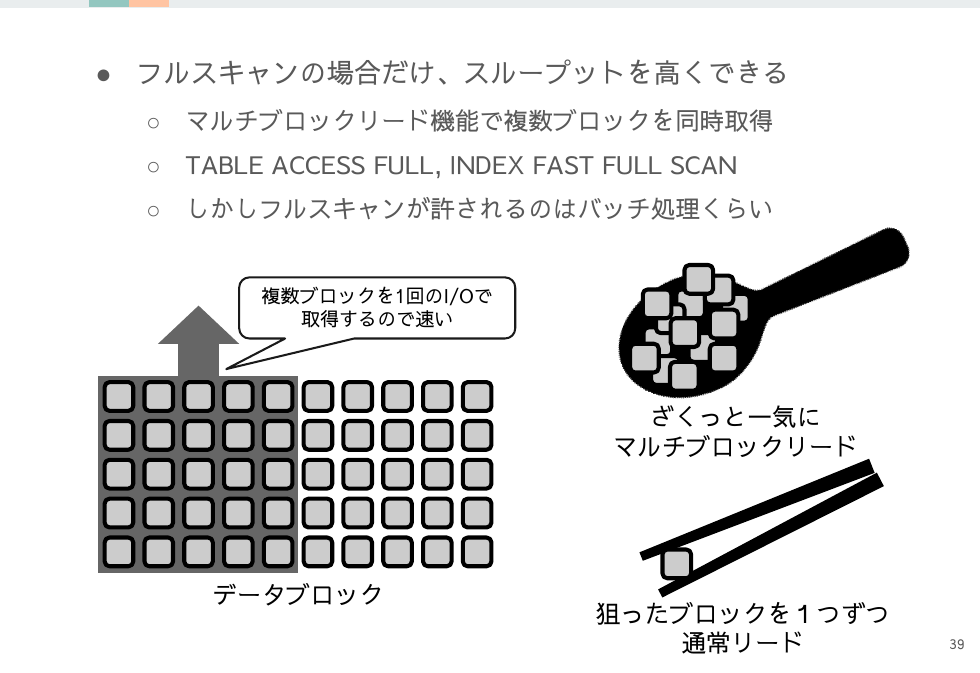
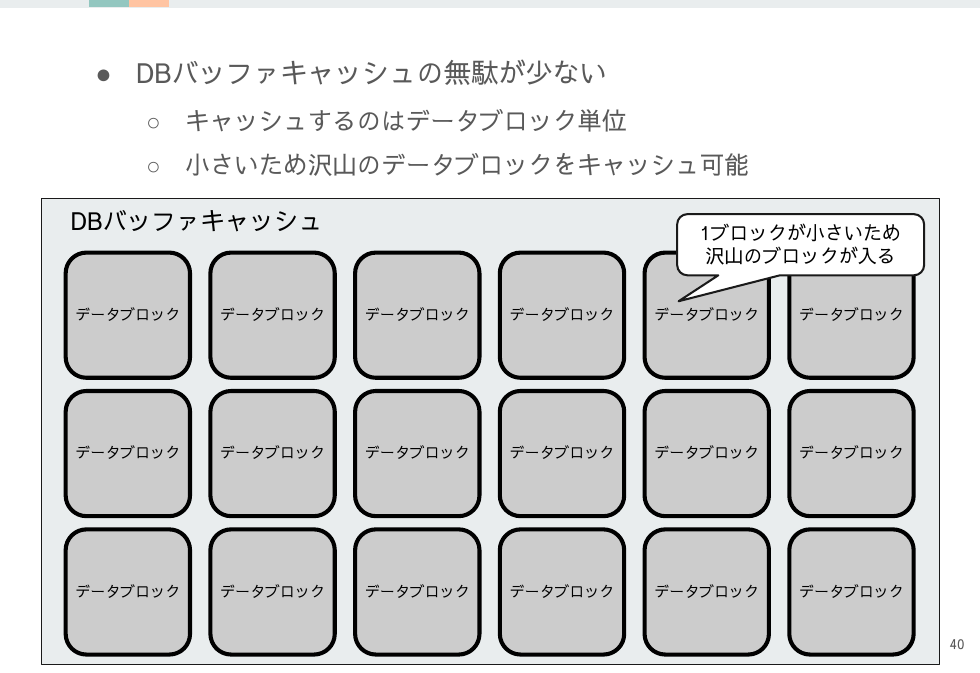
すべてのメリットデメリットが大きなブロックサイズと反転しますが、唯一異なるのはマルチブロックリードによるブーストを使える点です。
フルスキャン限定なので使いどころは難しいですが、うまく設計に取り入れられたら小さいブロックサイズのメリットと大きいブロックサイズのメリットをいいとこ取りできるかもしれません。
上記のスライドではフルスキャンはバッチのみと記載していますが、テーブルサイズをある程度小さめに保ってフルスキャン狙いとするのはチューニングの設計としてあり得ます。

ブロックサイズを各テーブルごとにチューニングできたらベストですが難易度は高いので、開発者としてはブロックサイズ自体をチューニングするのではなく、与えられたブロックサイズを知った上でそのブロックサイズにおいてベターなチューニングを行うことをオススメします。
ROWIDとは何か

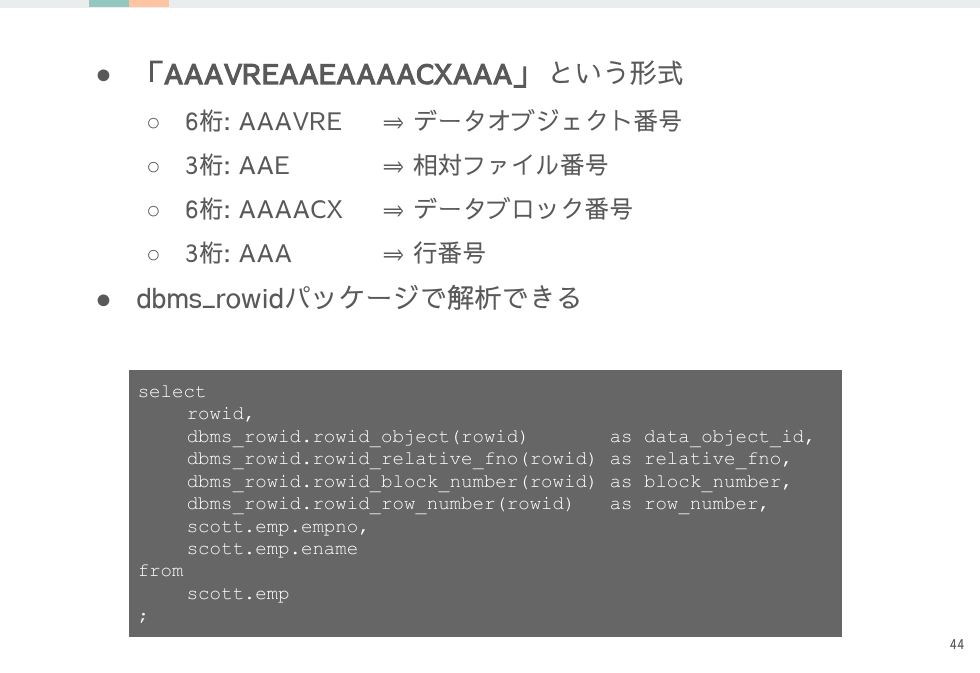
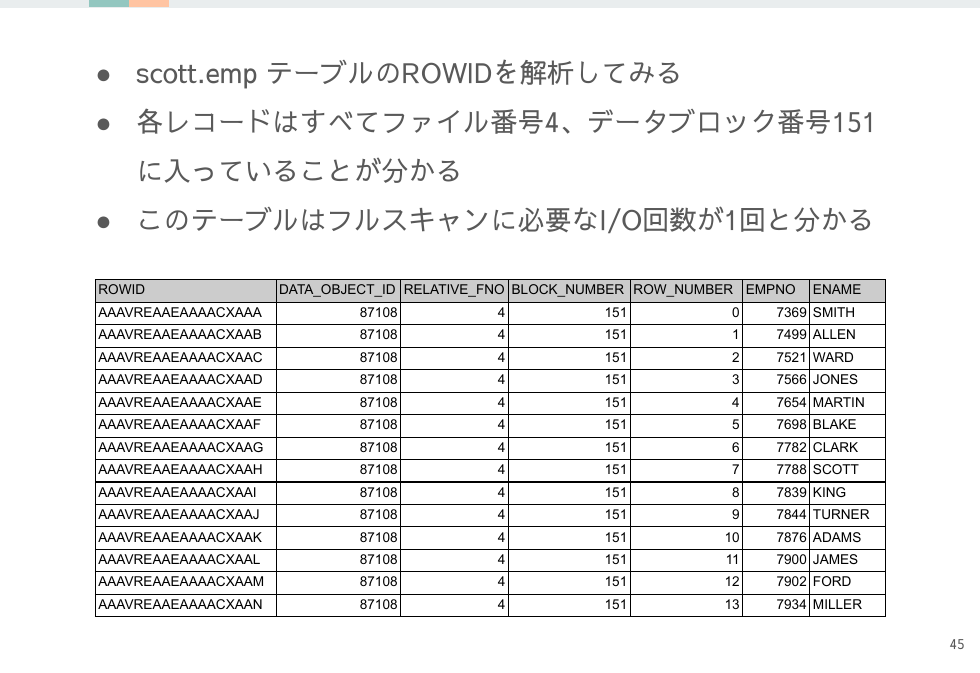
各レコードが持つROWIDからはファイル番号とブロック番号が分かるので、ストレージ内の物理的な位置を特定できます。
スライドでは14行しかない scott.emp 表を使っていますが、より大規模なテーブルやチューニングしたいSQLの各レコードに対してブロック番号を解析すれば、レコードが保存されているブロックが分散しているのか、何回I/Oが必要だったのかなどの実態を把握することができます。登場したブロック番号の数だけDBはI/Oを行っているのです。
ROWIDはインデックスに使われる
チューニングのための解析に便利なROWIDですが、DB内ではインデックスに使われています。
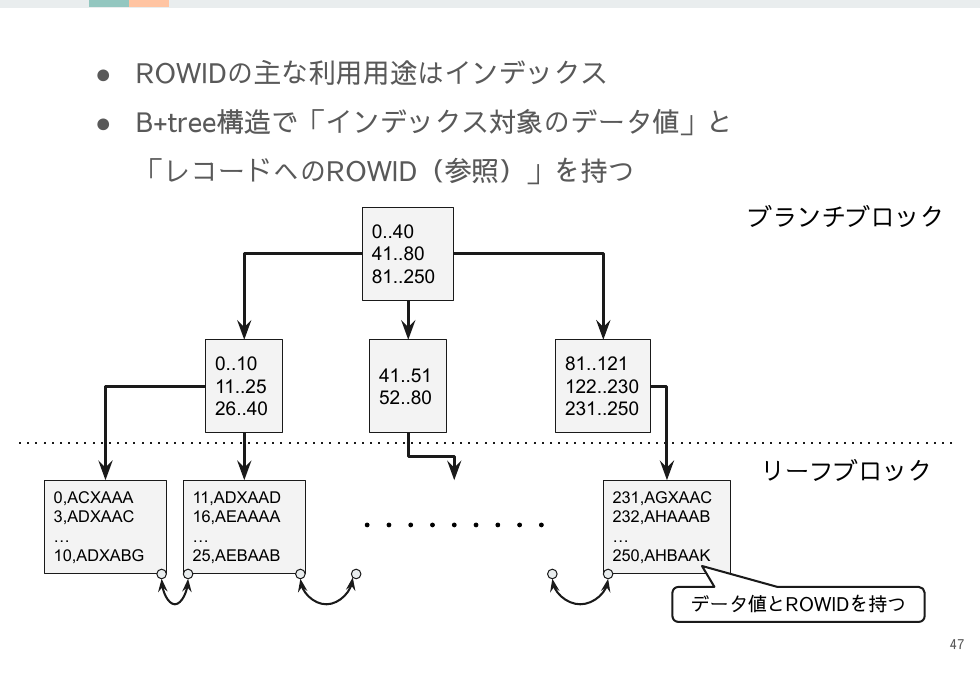
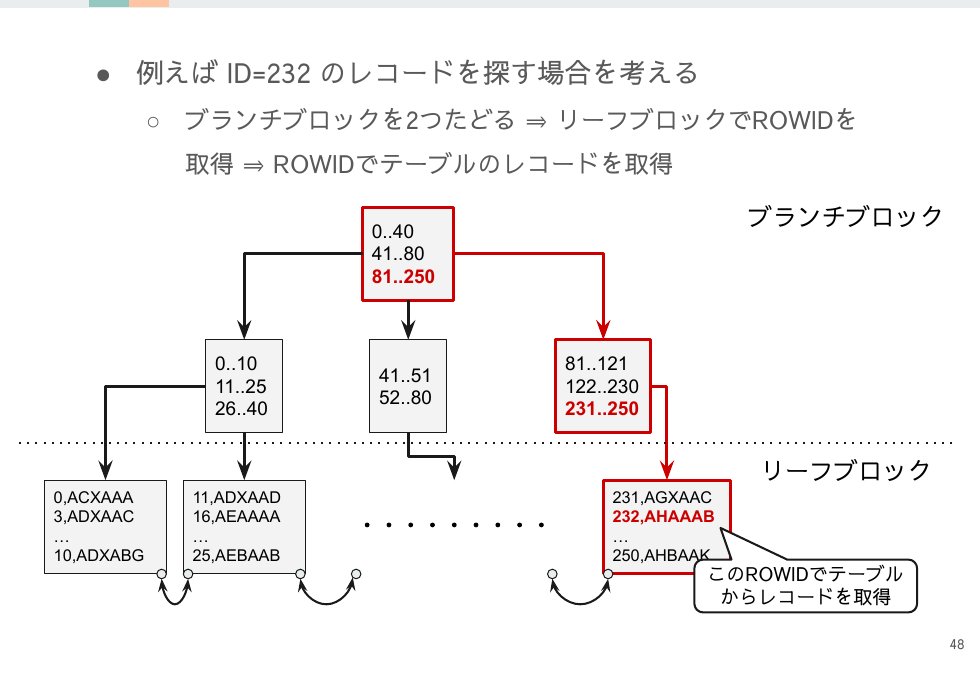
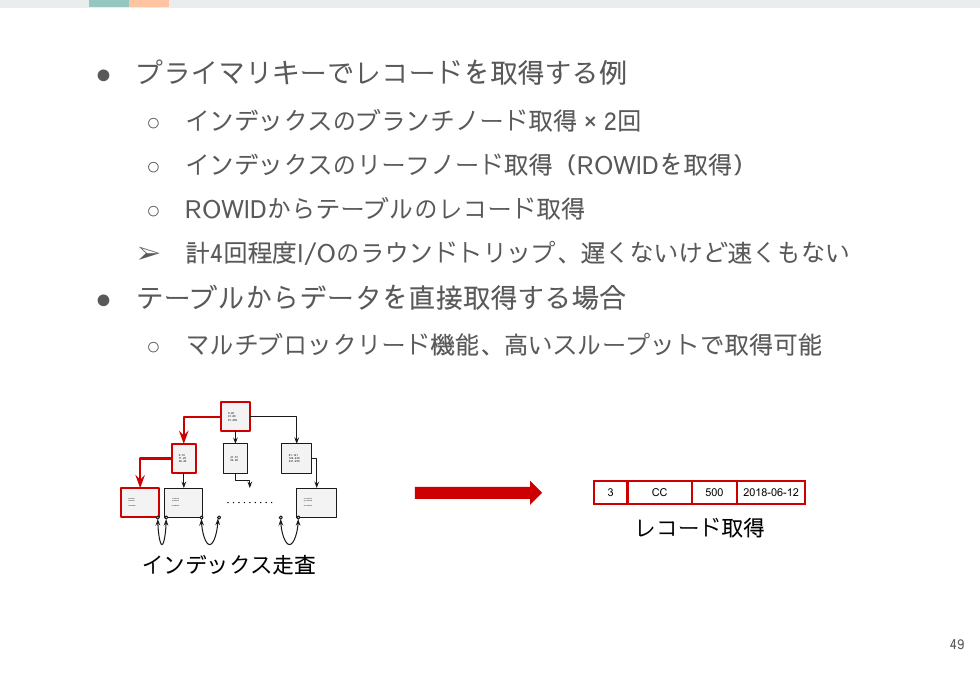
インデックスは少ないレコードを取得するのに最適ですが、大量レコードを取得する場合はインデックスとテーブルでI/O回数が非常に多くなります。
一方テーブルのフルスキャンではマルチブロックリードも使えることも合わせるとインデックス経由で大量のレコードを取得するのは遅くなる原因となります。
MySQL(InnoDB)との比較
ここまでOracleの内部構造を解説してきましたので、少し気分を変えてMySQLのInnoDBを見てみましょう。
世の中には様々なDBがあってそれぞれ違いがあります。しかしどれかが圧倒的に優れているわけではなく、あくまで特徴の違いです。
どんなDBも銀の弾丸の謎技術で高速化されているわけではなく、思想や設計に基づいた得意分野と不得意分野があります。
つまり他のDBの特徴を知って比較することは、Oracleの理解をさらに深めることに繋がるのです。
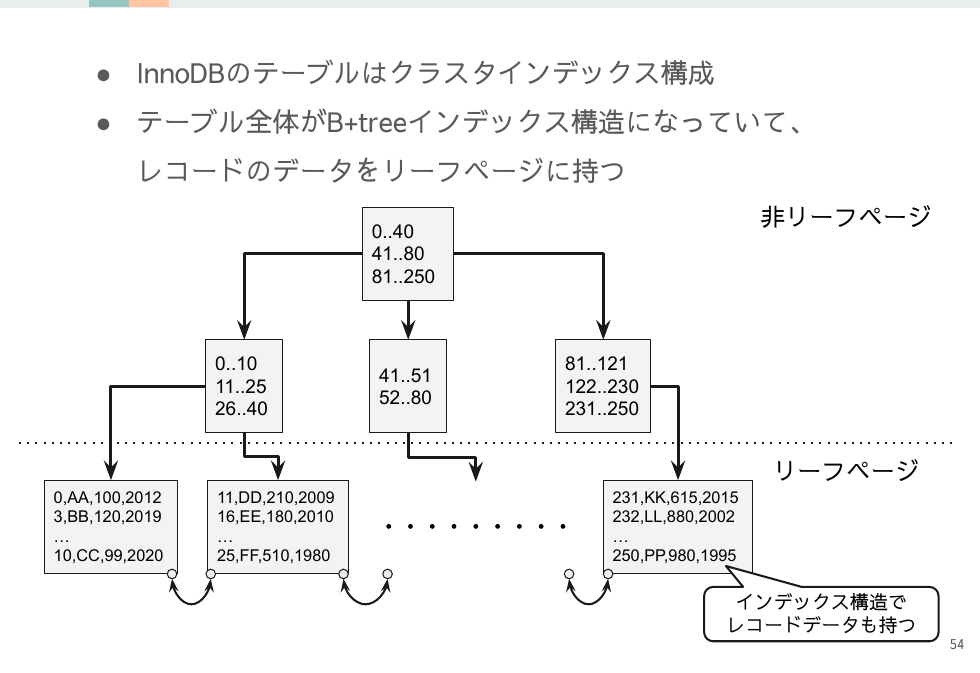
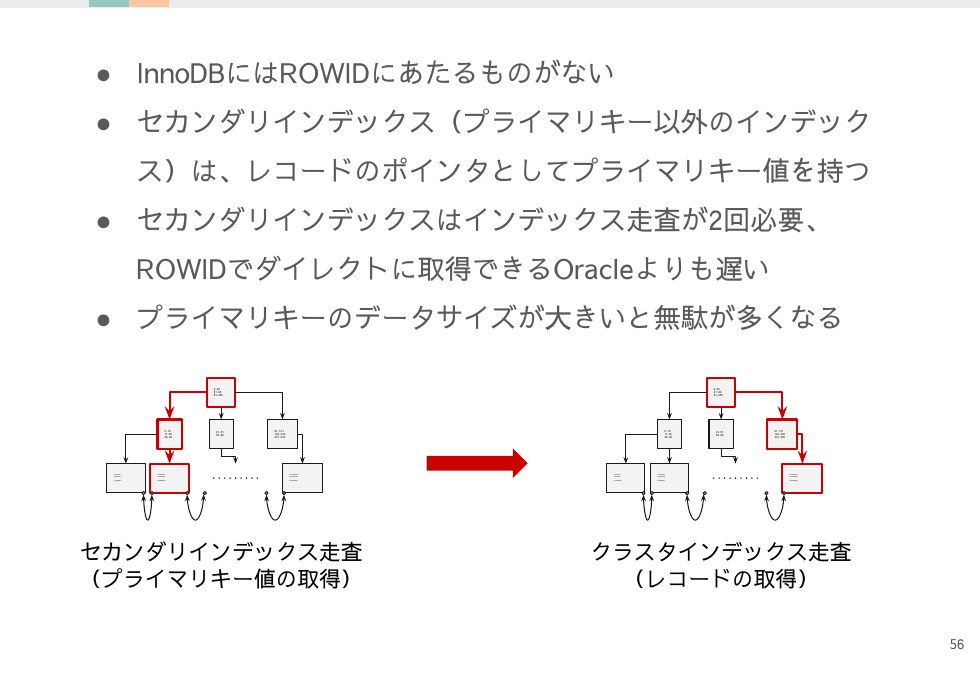
InnoDBの最も特徴的な点はクラスタインデックス構成であることです。テーブルがインデックスのB+tree構造でリーフページにレコードのデータを含みます。
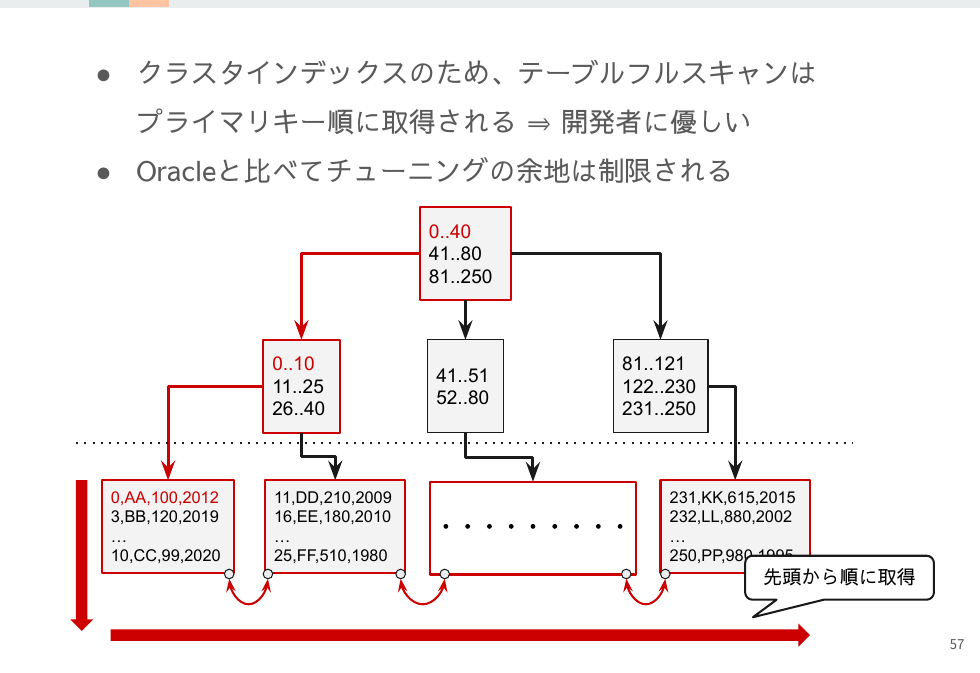
プライマリキーの走査でテーブルデータも取得できるためOracleのようにROWIDからレコードを取得する一手が必要ありません。またフルスキャンのレコード返却がプライマリキー順となるのは開発者にとって扱いやすいと言えます。
しかし一方でB+tree構造なのでストレージ内の記録場所は一定ではありません。リーフページの再編成が行われると移動してしまいます。
そのためOracleのROWIDのように一手で場所を特定できる手段は存在せず、常に論理ID(=プライマリキー)を使ってレコードを特定することになります。
そうなると一番デメリットを被るのがセカンダリインデックスです。セカンダリインデックスはリーフページに論理ID(=プライマリキー)を持つので、レコード取得するまでに2回のインデックス走査が必要となってしまいます。
レコードの物理配置が確定しているOracleと比べてチューニングの余地には差がでてきます。
Oracleをメインで使っている方はプライマリキーと追加のユニークインデックスで何か差があるのか疑問に思ったことはありませんか?DBについて学ぶとプライマリキーでの絞り込みの方がパフォーマンスが良いと記載されていることもあったり、でもはっきりとしたことはよく分からないし体感としても差を感じないなど。
そうです、Oracleはプライマリキーだろうと追加のユニークインデックスだろうとヒープ表のROWIDに対するB+tree構造に違いはありません。
パフォーマンスに違いのでる要因としては絞り込み条件に対してインデックスのブランチブロック・リーフブロック・テーブルのブロックが分散しているかしていないかというだけです。
レコードサイズとパフォーマンス
ブロックサイズについて学んだので、次はレコードサイズとの関係性について考えてみましょう。

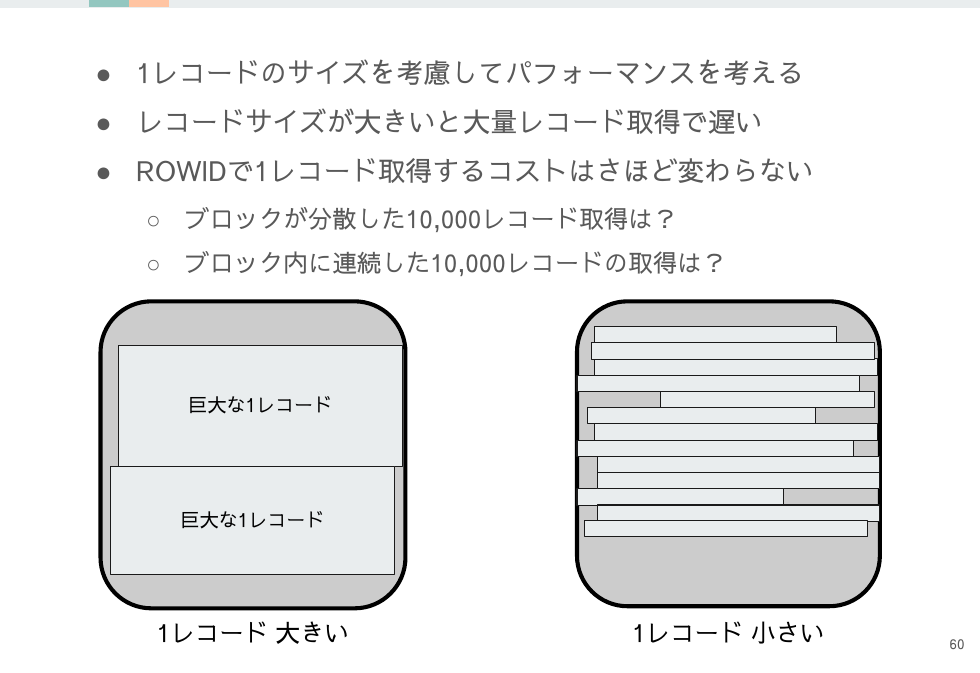
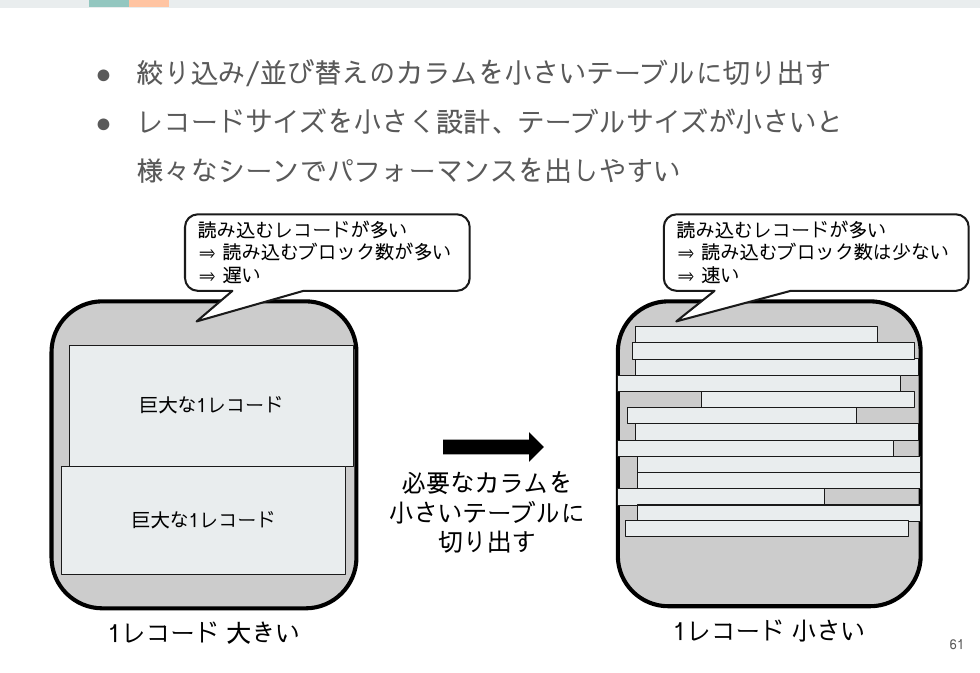
SQLチューニングは技巧的な面が多々ありますが、実は1レコードのサイズが小さければ行数がかなり多めでも意外とパフォーマンスをだすことができます。
利用するサーバのスペックにもよりますが、100万レコードあっても1レコードのサイズが小さければフルスキャンしてもさほど待たされずに処理できます。
いろいろ悩んでチューニングするよりも「一方ロシアは鉛筆を使った」のように肩の力を抜いて考える、この場合ならテーブルを小さくする方が最適な場合もあります。
レコードの分散
レコードとデータブロックの関係性が分かってきたので、レコードの分散について今度は具体的な例で考えてみましょう。
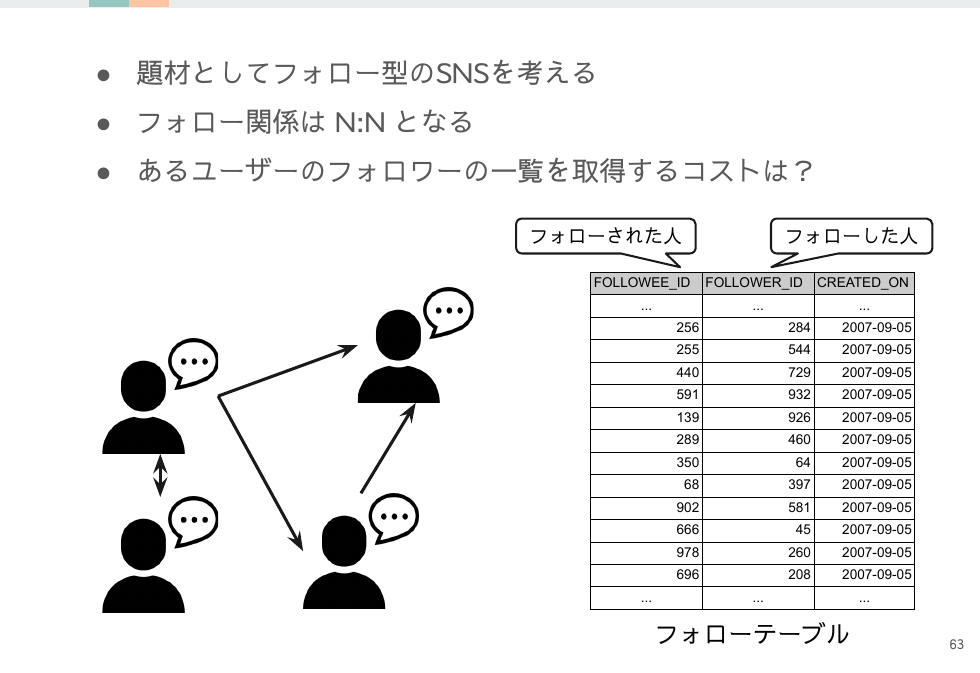
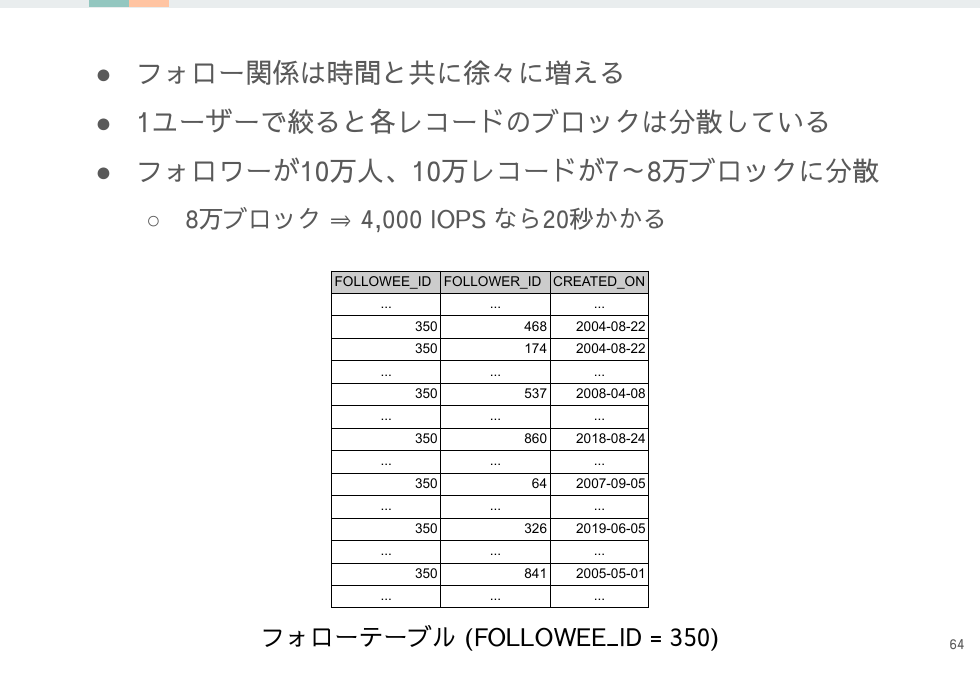
取得したいレコードがどのようにブロックに格納されているのかをイメージすると、取得にかかる時間も必然的にイメージできるようになります。
有名人のアカウントの場合は10万人がフォローしていることは普通に想定できる状況な一方で、フォロワーは徐々に増えるのでそのユーザーへのフォローレコードが同一ブロックに固まる可能性は高くありません。そうなると10万レコード取得するのは10万ブロックに近いブロック数を取得することとイコールになります。フォローテーブル自体はシンプルな構造で1ブロック内にレコードを沢山詰め込めますが、その利点もレコードが分散していたら生かせません。
また、Oracleは明示的な操作をしないとレコードの物理位置は変化しないようにできています。これは物理位置の変更が必然的にインデックスに記録されたROWIDにも影響が及ぶなどコストの高い処理とされているからです。
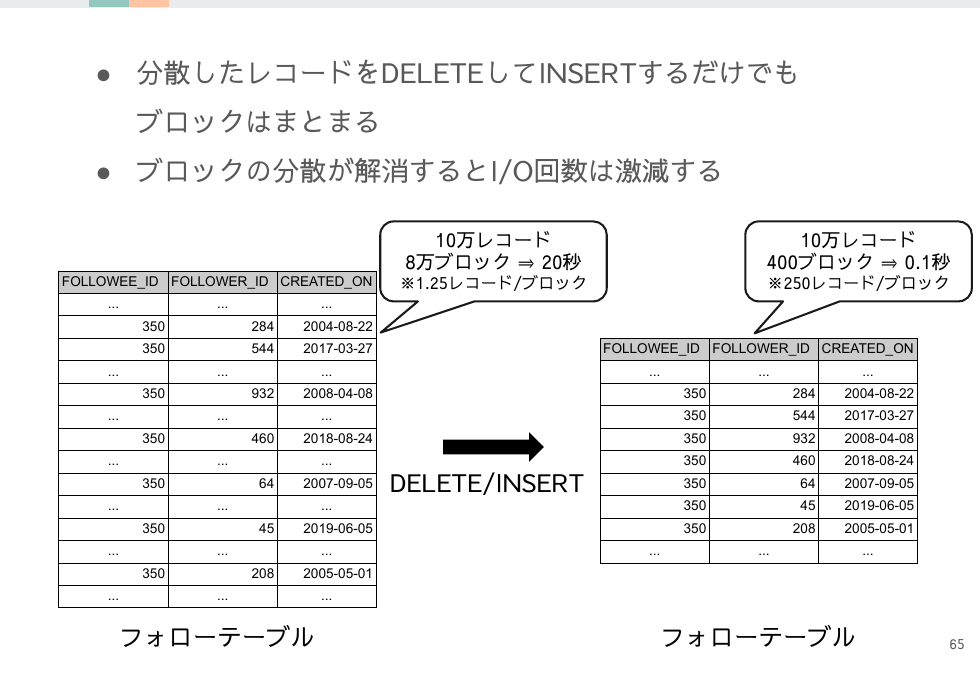
しかし場合によっては、その一時的なメンテナンスコストを支払ってでも物理位置を調整した方が長期的なパフォーマンスが改善することはあります。
今回の問題の場合はDELETEしてからINSERTするだけで物理位置はまとまり、対象のレコード群の取得コストを下げることができます。
10年後を考える
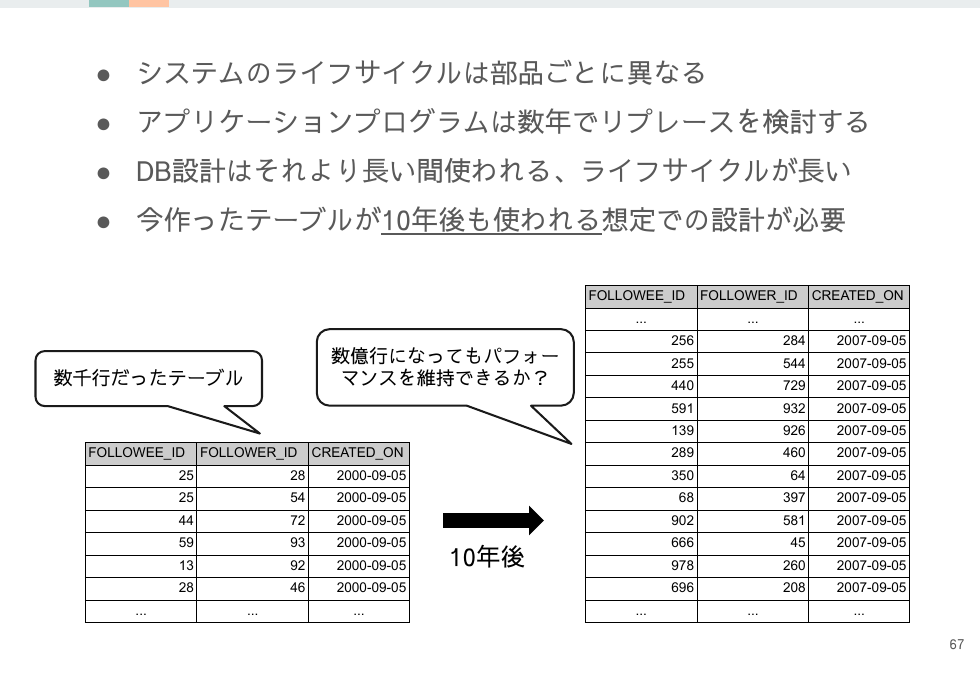
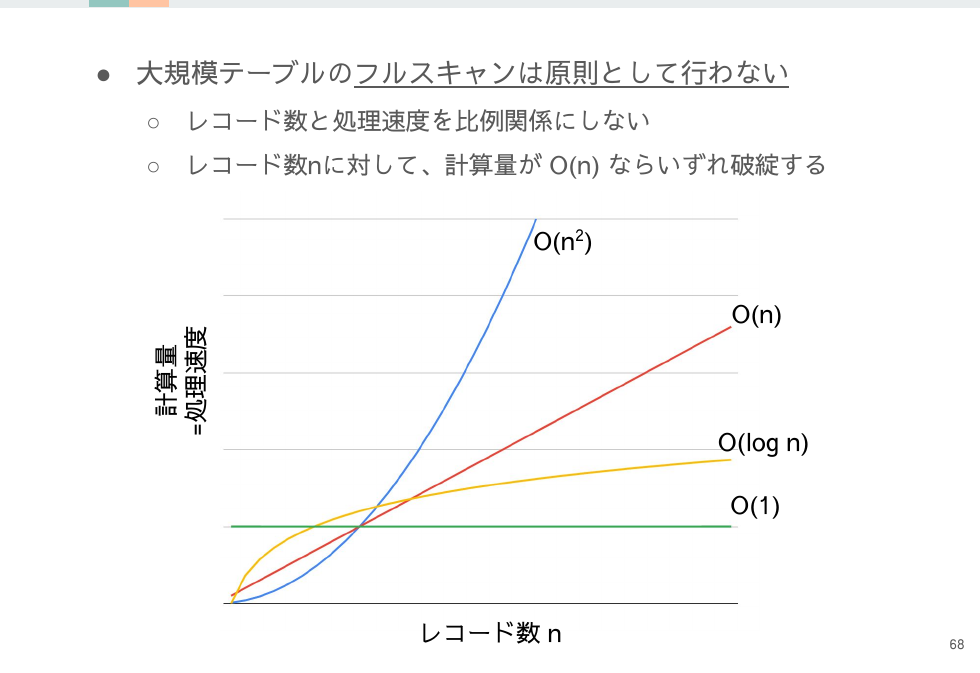
レコード数に対する処理速度を考えましょう。
- レコードが増加し続けるテーブルか?
- 増加速度は速いか遅いか?
レコードの増加速度の速いテーブルならば、計算量(=処理速度)は O(1) か、最悪でも O(log n) にする必要があります。
計算量を減らす為に必要なことは「要件を工夫」「アルゴリズムを工夫」「テーブル設計を工夫」など様々あります。
DBはSQLを実行すれば魔法のように望む結果を返してくれますが、大規模なテーブルにフルスキャンをすれば当然遅くなります。
例えばさほど意識せずに order by をしてから先頭の100レコードを取得したことはありませんか?しかしDBとしては事前ソート済みのインデックスを利用できない場合は対象レコードを全て取得してからソート処理が必要となり、実質フルスキャンを行うことになります。
これらは開発段階ではDBバッファキャッシュなどの影響で見かけ上は速く処理されてしまい、本番リリース後にパフォーマンス劣化として現れることが多々あります。
「計測せよ」で満足せず、その計測結果が本当に正しいのかを内部構造から考えて「推測」してみてください。
まとめ
今回は当社で実施したOracleデータベースのチューニングスキルをさらにもう1段階上げるための勉強会の資料の公開と解説でした。
この勉強会を実施したら早速部内からは「あのSQLが遅いのはブロックが分散していたのか・・・」などという声がチラホラ聞こえてきたりしました。
当社では様々な分野の勉強会がよく開かれているのですが、それぞれのエンジニアが持っている知見を共有してくれるのは非常にためになって、すぐにでも業務に生かせるものが沢山あっていつも楽しみにしています。
今回実施した勉強会は一般的なOracleデータベースのチューニングの話題だったのでこの場で公開させてもらいました。この資料が少しでもみなさんの役にたてば幸いです。
また、この記事では冗長な部分を省略して掲載しておりますので、スライド全体はこちらからご覧ください。
Oracleデータベースの話が中心でしたが、1つのデータベースをしっかり理解すると他のDBの内部構造も比較的簡単に理解できるようになります。
例えばレコードサイズを小さく保つ利点を解説しましたが、MySQLのInnoDBはクラスタインデックス構造なのでレコードサイズが大きくなった場合はOracleよりもパフォーマンスに対する悪影響が顕著です。しかしMySQLは多くの人によって長らく磨かれたプロダクトなのでそれを緩和するための工夫がされています。一例としては文字列カラムが一定サイズ以上になった場合はオフページという別領域に保存してクラスタインデックス内にはポインタだけを保存するように設定できます。つまり絞り込みやソートに使う数値カラムなどは高速に取得できて、最終的に100件だけオフページから文字列まで取得するということができます。
こういった柔軟性はOracleよりも高く、似たことをOracleでもやりたい場合はCLOB型を使うことになります。しかし文字列カラムをレコードから隔離したい目的だけのためにCLOBを使うのはシロアリ駆除にマシンガンを使うような印象でイマイチしっくりきません。
各DBの特徴をしっかり掴むことは相乗効果で理解が深まっていくので、MySQL中心で利用している方も「Oracleはこうなってるんだ」と参考にしていただけたらと思います。
パフォーマンスチューニングはバックエンドからフロントエンドまで全てのレイヤでの対処が必要となるので、以下の記事もぜひご覧ください。
- フロントエンドのパフォーマンスを徹底解説!ブラウザの気持ちで理解するHTML/Javascript/CSSの話
- rel=”preload”を極めるために必要な2種類のプリロード機能