Zipファイルを紙とペンで解凍してみた
こんにちは。ほそかわです。
社内勉強会用に、埋めていくだけでzipファイルの解凍ができるプリントを作りました。
普段、zipファイルの解凍はコンピュータにやってもらっていますが、
この記事を読みながらご自身の手を使って紙とペンでやってみましょう。
アルゴリズムとデータ構造を生で感じるチャンスです。
準備
これから使うプリントをダウンロードして印刷しましょう。
- ZIPローカルファイルヘッダ (Download)
- ZIPセントラルディレクトリファイルヘッダ (Download)
- ZIPセントラルディレクトリ終端レコード (Download)
- ZIPファイルデータ (Download)
- 16進数表 (Download)
「ZIPローカルファイルヘッダ」、
「ZIPセントラルディレクトリファイルヘッダ」、
「ZIPセントラルディレクトリ終端レコード」
記入してZIPの解凍を進めていくプリントです。
「ZIPファイルデータ」
この記事で解凍を行うzipファイルのバイナリデータです。
左側に書いてあるのは16進数で表されたバイナリデータです。主にこちらを使います。
16進数で書かれている行名と列名を足すと何byte目のアドレスにあるデータかが分かります。
右側に書いてあるのは文字列データが簡単に調べられるASCIIで表されたバイナリデータです。
「16進数表」
計算の手間を省くためのものです。
全て印刷して筆記用具も用意できたら準備はOKです。
今回用意したZIPファイルデータは、データ圧縮が行われていない特殊なzipファイルになってます。
圧縮を行わないzipファイルに意味なんてないと感じるかもしれませんが、圧縮に関する仕様は独立しているのでこの記事を読んだ後に別に勉強できます。
無圧縮のzipファイルはzipコマンドでも作れます。
zip -0 file.zip file.txtプロトコルのバージョンによって違いがあるかもしれないのでこの記事ではこちらで用意したファイルを使います。
概要
Zipファイルの中にはどんなデータが入っているのか見てみましょう。
ファイル全体の概要を図にしました。

Zipファイルはヘッダとファイルエントリ、終端レコードで構成されています。
ヘッダには2種類あります。
- ZIPローカルファイルヘッダ
- ZIPセントラルディレクトリファイルヘッダ
ZIPセントラルディレクトリファイルヘッダは、ZIPファイルの最後にあるZIPセントラルディレクトリという領域に入っています。そして、ZIPセントラルディレクトリの一番最後にアーカイブ全体についての情報が書いてある終端レコードが付いていてます。
ヘッダにはzipファイルに格納したファイルについてファイル名などの情報が書いてあり、ファイルエントリには格納したファイルの中身が入っています。
図のzipファイルにはA,Bの2つのファイルが格納されています。2種類のヘッダとファイルエントリがファイル数だけ繰り返されています。
ネタバレになってしまいますが繰り返しがあると手間が増えるばかりなので、今回使うzipファイルに格納されているファイルは一つです。
バイナリデータ
Zipファイルは普段扱っているテキストデータよりもコンピュータ向けなバイナリデータとして保存されています。
バイナリデータを扱う為に、16進数、2進数の変換方法とエンディアンについて知っておきましょう。
基礎的な知識なのでWikipediaをみてください。
エンディアンは様々なことが書いてありますが、zipファイルを扱うのにはリトルエンディアンとビックエンディアンのデータが読めるようになっていれば十分です。
リトルエンディアンでは1byteをかたまりとして並び順を逆にします。
AB CD EF 12であれば
12 EF CD ABとなります。
例えば、16進数で1B58という数値をリトルエンディアンで表すと
58 1Bとなります。
ビックエンディアンは並び順を変えないもので、
AB CD EF 12であれば、そのまま
AB CD EF 12となります。
ZIPセントラルディレクトリ終端レコード
これから紙とペンを使ってzipを解凍していきます。
まずは、アーカイブ全体の情報を得るために、セントラルディレクトリの終端レコードに記録してある情報を調べましょう。
使うプリントは、「ZIPセントラルディレクトリ終端レコード」です。
概要で説明したように、終端レコードはzipファイルの最後の領域にあります。
ZIPの仕様として終端レコードの頭には、
50 4B 05 06というシグネチャをつけることになっています。
終端レコードはファイルの末尾にあるので末尾から開始地点を表すシグネチャを探すことで、終端レコードの領域を知ることができます。
zipファイルデータの末尾からシグネチャを探しましょう。
アドレス0x5Cに見つかりました。
そこからセントラルディレクトリヘッダの終端レコードが始まってます。
次のアドレスから順番にプリントに書き込んでいくと終端レコードの解凍を進められます。
四角い枠一つが1byteに対応してます。
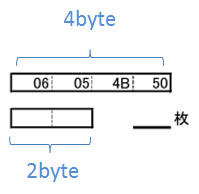
中には1byteのデータを書き込みます。
シグネチャは例としてリトルエンディアンで埋めてあります。
次の手順で全て埋めてみてください。
- 16進数で読み、数値データはリトルエンディアンで、(文字列)と書いてある文字列のデータはビックエンディアンで四角い枠の欄に記入する。
-
数値データは、16進数のデータを10進数に直して下線が引いてある欄に記入する。文字列のデータは1byteごとにASCII文字に変換してある右に表の同じ位置の文字を探して記入する。
(厳密には、文字列のデータもリトルエンディアンになっています。並び替えを行わないビックエンディアンとして扱えている理由は、1文字の1byte単位で保存が行われているからです。リトルエンディアンは1byteをかたまりとして並び替えるものなので、1byteのデータでは並び替えが行われず、リトルエンディアンになる並び替えが行われてないように見えています)
最初なので答えを載せます。

全ての記入が終わったら細かく見て行きます。
セントラルディレクトリレコードの合計数
セントラルディレクトリレコードの数はファイルの数と同じになっています。
このzipファイルに含まれるファイルは一つだけだと分かります。
セントラルディレクトリの開始位置のオフセット、セントラルディレクトリのサイズについて
セントラルディレクトリの開始位置のオフセットからは、ファイルの先頭から見てどのアドレスでセントラルディレクトリが始まるのか、セントラルディレクトリのサイズからはどこまで続いているのかが分かります。
セントラルディレクトリは、先頭から39byte目のアドレス0x27で始まって53byte後のアドレス0x5Bで終わっているということがわかります。
Zipファイルコメントと長さについて
このzipファイルにはコメントがないため長さには0が入っています。
コメントは可変長のデータなのでここで長さを定義してそのバイト数だけコメントとして扱うという作りになってます。
その他の項目については、今では使われない機能が多いので割愛します。
興味があったら調べてみてください。
ZIPセントラルディレクトリファイルヘッダ
次は、セントラルディレクトリファイルヘッダです。
使うプリントは、「ZIPセントラルディレクトリファイルヘッダ」です。
終端レコードの情報から、セントラルディレクトリはアドレス0x27で始まっているとわかりました。
セントラルディレクトリファイルヘッダのシグネチャは、
50 4B 01 02です。
探してみると、終端レコードで書いてあったようにアドレス0x27にあります。
終端レコードの時と同じようにシグネチャの次のバイトからプリントを埋めていきます。
zipでは、日付、時刻のデータがバイト単位で分けられてません。
2byteの領域に3つのデータが入っているので、
一度、2byteを繋げた2進数に変換してから区切り直して、10進数に変換します。
次の手順で行います。
- リトルエンディアンで2byte分を2進数に変換して一桁ずつ下線の上に書く
- 縦線で区切られているところで分けて2進数から10進数変換して、次の行に書き込む
- 秒は2倍、年は1980を足す
このやり方も初めてなので答えを載せておきます。
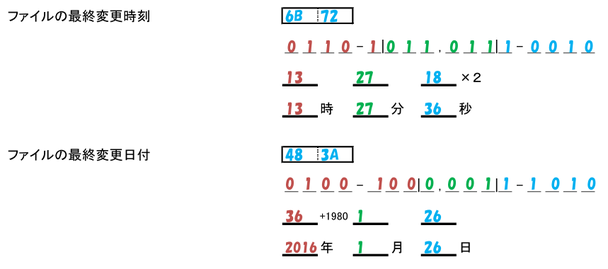
これでファイルの最終変更日時がわかります。
これも全ての記入が終わったら細かく見ていきます。
圧縮メソッド
ファイルエントリがどのプロトコルで格納されたかが書いてあります。
今回は無圧縮なので0が入っていますが8のDeflateが一般的です。
ファイルの最終変更時刻、最終変更日付
格納したファイルの最終変更日時です。
年は1980の下駄を履かせるので1980年からが使えます。
そして、なんと、秒はビットが足らず2秒刻みで丸められているので2倍します。
zipで圧縮を行ったファイルは最終変更日時の秒が保障されないことをご存知だったでしょうか。いつも使っているものでも意外な発見があるものなんですね。
CRC-32
格納前のファイルエントリで計算したCRC-32が入っています。
圧縮サイズ
格納後のサイズです。ファイルエントリのサイズが書いてあります。
非圧縮サイズ
格納前のファイルサイズです。
ファイル名の長さ、ファイル名
Zipファイルコメントと同じようにまず長さが定義されていて、その長さ分のファイル名データがあります。
ローカルファイルヘッダの相対オフセット
ファイル一個につき、セントラルディレクトリファイルヘッダとローカルファイルヘッダが一つずつあります。
対応するローカルファイルヘッダのアドレスが書いてあります。
最初のファイルのローカルファイルヘッダのアドレスなので0が入っています。
数が多いので他は割愛します。
調べてみてください。
ZIPローカルファイルヘッダとファイルエントリ
ローカルファイルヘッダはZIPセントラルディレクトリファイルヘッダと同じやり方で埋めていけます。
ローカルファイルヘッダの次のアドレスからファイルサイズのバイト数分だけがファイルエントリと呼ばれるファイルの中身のデータになってます。
圧縮が行われている場合には、ヘッダから得た圧縮プロトコル情報をもとにファイルエントリのデコードを行います。今回は無圧縮なので飛ばせます。
ファイルエントリをこれまでヘッダから得た情報をもとにファイルとして保存すればこのファイルは解凍されます。
今回は、
- ファイルの最終変更日は「2016年1月26日 13時27分36秒」
- ファイル名は「raccoon」
- ファイルの中身は「CA FE」
というファイルを作り、ファイルエントリをそのまま中に書き込めばこのzipファイルの解凍は成功です。
「CA FE」とは16進数で使われるA~Fまでの文字という制約で考えた単語「Cafe 」です。
」です。
最後に
お疲れ様でした!
Zipファイルが身近に感じられるようになったのではないでしょうか。
この記事は最短ルートでzipファイル概要を理解し解凍を体験できることを目標に書いたので多くの仕様を省略しています。
次のステップとして、圧縮アルゴリズムを勉強すると圧縮が行われている普通のzipファイルも解凍できるようになります。他にもパスワード付きや分割など多くの仕様があります。そして、反対のことを行えば圧縮もできます。
ZIPファイルフォーマットは様々なところで使われています。ZIPの知識を生かすことで仕事の幅が広がるかもしれません。このプリントを使って勉強会を開催するのも面白いでしょう。
これからの活躍につながるといいですね。
参考