AIエージェント開発での課題とその処方箋
皆さんこんにちは、CTO室チームリーダーの川崎です。
最近営業やカスタマーサポート部門などSQLを書くことに慣れていない人のために、チャットUI経由でデータベースに問い合わせを行い回答を得ることができるAIエージェントを開発しました。今回はそのAIエージェント開発で直面した課題とその解決策についてお話します。
作ったAIエージェントの概要
- 機能
- 読み取り専用のOracle データベースからMCPサーバー経由でSQLを実行し結果を返却する
- SQLクエリ構築のため、ソースコードやDBスキーマ情報を全文検索する
- このAIエージェントにアクセスできる人と場所を制限する
- ユーザーとのやり取りはチャットUIで行う
- 構成
- フロントエンド: Assistant UI(Next.jsを拡張したフレームワーク)
- AIエージェントフレームワーク: Mastra
自然言語で受けた命令からSQLを実行するまでのデモ動画(開くと見られます)

このAIエージェントは営業やカスタマーサポート部門の方がちょっとした情報を取得したい時や書いたSQLのレビューなどで今も活用されています。
※セキュリティも考慮して構築していますがこの記事では説明を割愛します。
AIエージェント開発で直面した課題
- 必要なコンテキストが大きすぎて指示したフロー通り動いてくれない
- サンプルタスクの成功率が低い
- 必要な情報がコンテキストに含まれていない
- 高度なモデルだと回答精度は良いけどLLM利用料金が高い
こんな課題に直面した私が実際に試して効果があった解決策を紹介します。
またこれらの課題はAIエージェントに限らず、チャットボットや生成AIを活用したアプリケーション開発全般に共通する課題でもあると思います。ぜひ参考にしてください。
必要なコンテキストが大きすぎて指示したフロー通り動いてくれない
課題: 扱うコンテキストサイズが大きくてLLMのコンテキストウィンドウ制限内であっても、Lost in Context(文脈の喪失)が発生したりAPIのQuota制限に引っかかる場合があって辛い。
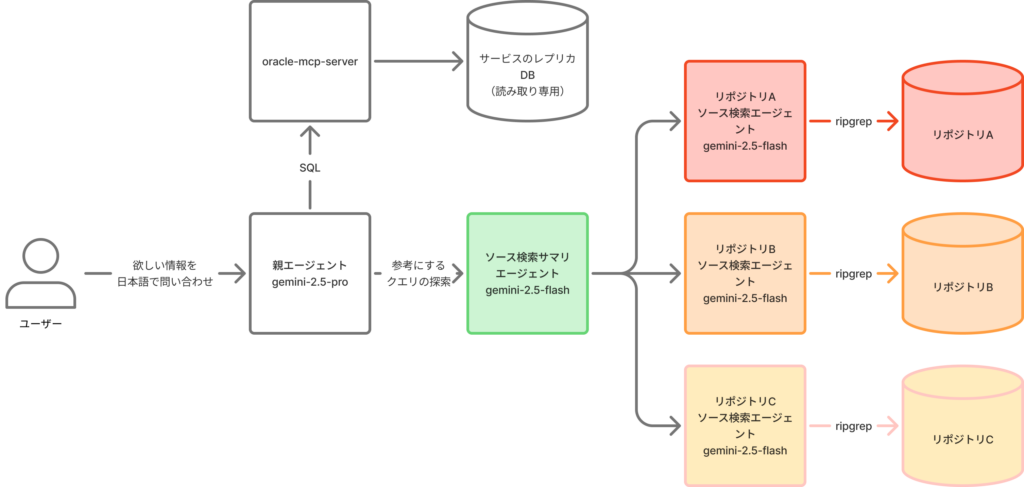
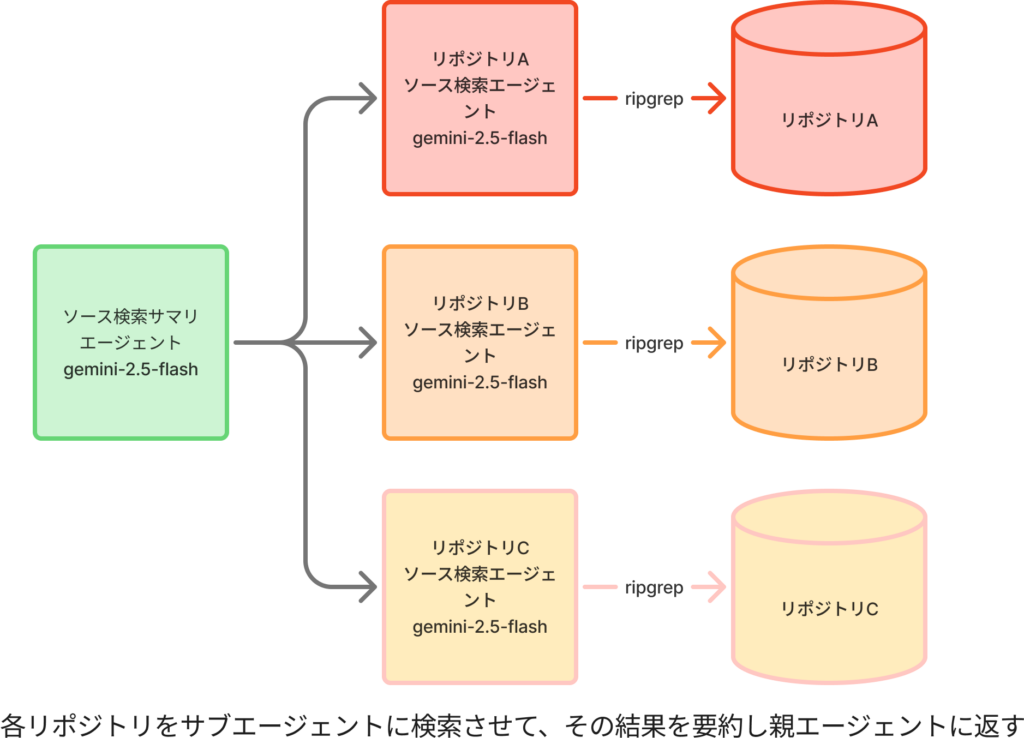
対策: コンテキストを分割しサブエージェントを導入することを検討しましょう。
膨大な情報を扱う箇所のみをサブエージェントに任せ、情報を参照した結果をメインエージェントに返すようにします。こうすることで、メインエージェントのコンテキストサイズを小さく保つことができ命令遂行の精度向上が期待できます。
私が作ったAIエージェントではSQLクエリを構築するためのソースコード検索をサブエージェントに任せています。ソースコードの検索は使用するコンテキスト量が大きくなりがちで、メインエージェントに任せると命令遂行の精度が落ちることが多かったためです。
サンプルタスクの成功率が低い
課題: サンプルタスクの成功率が低くPoCとして成立しない。
対策: Temperatureを下げたり、thinking budgetを設定したり、試行回数を増やすなどしてみましょう。
Temperatureの調整
- Temperatureを下げることで、回答の多様性を減らし、より安定した結果を得ることができます。
- 逆に、Temperatureを上げることで多様性を持たせ、創造的な回答を引き出すことが可能です。
ドキュメント検索など探索的タスクでは検索クエリの構築において多様性が必要なためTemperatureを高めに設定し、検索して取得したドキュメントの要約など多様性が不要なタスクではTemperatureを低めに設定するのが良いでしょう。
Temperatureを下げる場合は0.5~0.8の範囲で試してみるのがおすすめです。
Thinking Budgetの設定
- Thinking Budgetを増やすことで、エージェントがより多くの思考ステップを踏むことができ、複雑なタスクに対しても適切に対応できるようになります。
- 逆に、Thinking Budgetを減らすことで、実直に命令を遂行させることができます。
ここで注意したいのが、システムプロンプトにある命令の遵守率です。Thinking Budgetが大きいと、AIエージェントが命令から逸脱して余計なことをし始める場合があります。こうした場合はThinking Budgetを減らすことで命令に忠実に動かすことができます。AIエージェントに期待する役割に応じてThinking Budgetを調整しましょう。
試行回数を増やす
- 試行回数を増やすことで、エージェントが異なるアプローチを試みる機会が増え成功率の向上が期待できます。
- ただし、試行回数を増やすことで処理時間が長くなる可能性があるためバランスを考慮する必要があります。
- LLM利用料金も増えます
あわせて試行回数が多くなると本来行ってほしいタスク以外のことを実行する場合があります。
どうしてもうまくいかない場合は、 エージェントとしではなくワークフローのタスクの一つとしてLLMを呼び出すことを検討しましょう。 タスクの実行フローを遵守する必要があるときはそのほうが効果的です。MastraなどではワークフローにAIを簡単に組み込める仕組みが存在します。
必要な情報がコンテキストに含まれていない
課題: エージェントの回答に必要な情報がコンテキストに含まれていない。ベクトル検索を試したけどあまり効果がなかった。
対策: ベクトル検索だけでなく、全文検索やセマンティック検索も試してみましょう。特に、メタデータが整備されていない場合は全文検索の方が有効なことがあります。
特にPoCレベルではベクトル検索用にメタデータを整備したりハイブリッド検索を構築するコストが高くつく場合があります。まずは全文検索を試し必要に応じてベクトル検索を導入するのが良いでしょう。
冒頭に書いたSQLを構築してDBに問い合わせを行うAIエージェントの場合、ベクトル検索も試しましたがサービスのSQLコードなどを全文検索させたほうが作成するクエリの精度が高くなりました。これは当然ですがサービスで実際利用されるSQLコードにはテーブル名やカラム名などの情報が多く含まれているためです。とはいえベクトル検索もよりコストをかけて環境を整備すれば近い精度の結果は得られるかもしれません。
高度なモデルだと回答精度は良いけどコストが高い
課題: 高度なモデルを使うと回答精度は良いけどLLM利用料金が高くて辛い。
対策: 必要に応じてモデルを使い分けたり、Prompt Cachingを有効に活用したりしましょう。
必要に応じてモデルを使い分ける
高性能なモデルは高コストですが必ずしもすべてのタスクで必要なわけではありません。単純なサブタスクには低コストなモデルを使い、複雑なタスクには高性能なモデルを使うなどしてコストを抑えましょう。これは前述したサブエージェントの導入と組み合わせると効果的です。
Prompt Cachingを活用する
Gemini 2.5やOpenAI GPT-4o以降は暗黙的にPrompt Cachingが有効になっています。これを有効に活用するために現在時刻情報などを除いた、毎回固定のシステムプロントは先頭に置く必要があるという点に注意しましょう。
終わりに
AIエージェント開発の手法やベストプラクティスは日々進化しています。今回紹介した内容がずっと役に立つとは言えませんが皆さんのAIエージェント開発の一助となれば幸いです。今後も新しい知見が得られ次第、共有していきたいと思います。
余談ですがPoCを作るならAssistant UIとMastraを使うのがおすすめです。特にMastraはLLMの呼び出しやツールの実装が簡単にできるのでAIエージェント開発のハードルが大幅に下がります。
We are Hiring!
ラクーンホールディングスではサービスにおけるLLMの活用を強化しています。上述のAIエージェント作成以外にもBtoB ECサイトへの画像検索機能組み込みを作る機会が普通に存在します。弊社が運営サービスの開発を一緒にやりませんか?
採用への応募はこちらから!ぜひ一度お話しましょう!