

【研修資料公開】低レイヤを学ぶ、Linuxカーネルとコンテナの仕組みの研修
こんにちは、羽山です。
今回はラクーンホールディングスの座学研修で私が講師を担当する 3年次 Linux && Docker研修 をご紹介します。当社は教育制度に力をいれており、入社直後に5~6ヶ月間の研修があります。そしてさらに n年次研修 という枠組みで2年次、3年次、4年次と定期的に研修を実施して、経験を積んだ各ステージに必要な知識・スキルを補完しています。
3年次 Linux && Docker研修は入社から3年目の1~2月頃(4年目目前)に実施していて、エンジニアとしての実力も付いてきた段階で受けることになります。
4年目目前ともなれば Linux や Docker を普段から開発に利用していて基本操作には困っていないはずです。
一方で Linuxカーネルの役割を聞かれたら返答に窮したり、コンテナとはプロセスと言葉では知っていても実はよく分からなかったり、そういうあたりが本研修のターゲットです。システムの土台となる低レイヤをしっかり理解して、エンジニアとしての基礎力を高めることを目的としています。
資料全体を SpeakerDeck で公開しています。
本研修はスライドの内容を講師がターミナルで実演しながら進めることを想定しています。もしこの研修資料で実際に研修を実施する場合は是非参考にしていただけたら幸いです。
Linux && Docker研修 株式会社ラクーンホールディングス (SpeakerDeck)

また本研修の主題である低レイヤの重要性を解説した 「プログラマーのためのCPU入門」は入り口として丁度よい! という LT も以前実施しています。合わせて参考にしていただけたらと思います。
では本題である以降のブログ記事では、研修の要点をかいつまんで解説します。
カーネルとは何か?
プログラミング言語には必ず用意されている画面表示用の関数たち、 print puts System.out.println がどういう仕組みなのか気になったことはありませんか?
print() 相当の機能を作ってください、と言われると自力で開発できると思いますか?
この、どう実装すれば良いのか分からない不思議なメソッドはカーネルの機能を利用して作られています。

カーネルが OS の中核機能とはご存じの方が多いと思いますが、どういう意味かよく分からないですよね?
具体的には起動しているプログラムの中で唯一デバイス操作の権限を持ちます。ここで言う デバイス操作 とは広義であり「メモリ領域確保」「ディスプレイに文字を出力」「キーボード入力を受け付け」「TCP通信」などなど、あらゆる処理が該当します。CPU での単純な演算処理以外のすべてだと理解してもさほど間違っていないです。
カーネル以外のアプリはすべて ユーザー空間 というカーネルが作った鳥かごのようなものの中で動き、鳥かごの外へは直接干渉できません。そこでディスプレイに文字を出力する場合は「カーネルさん、画面に『Hello World』って表示してください」とお願いします。このお願いのことを システムコール と呼びます。
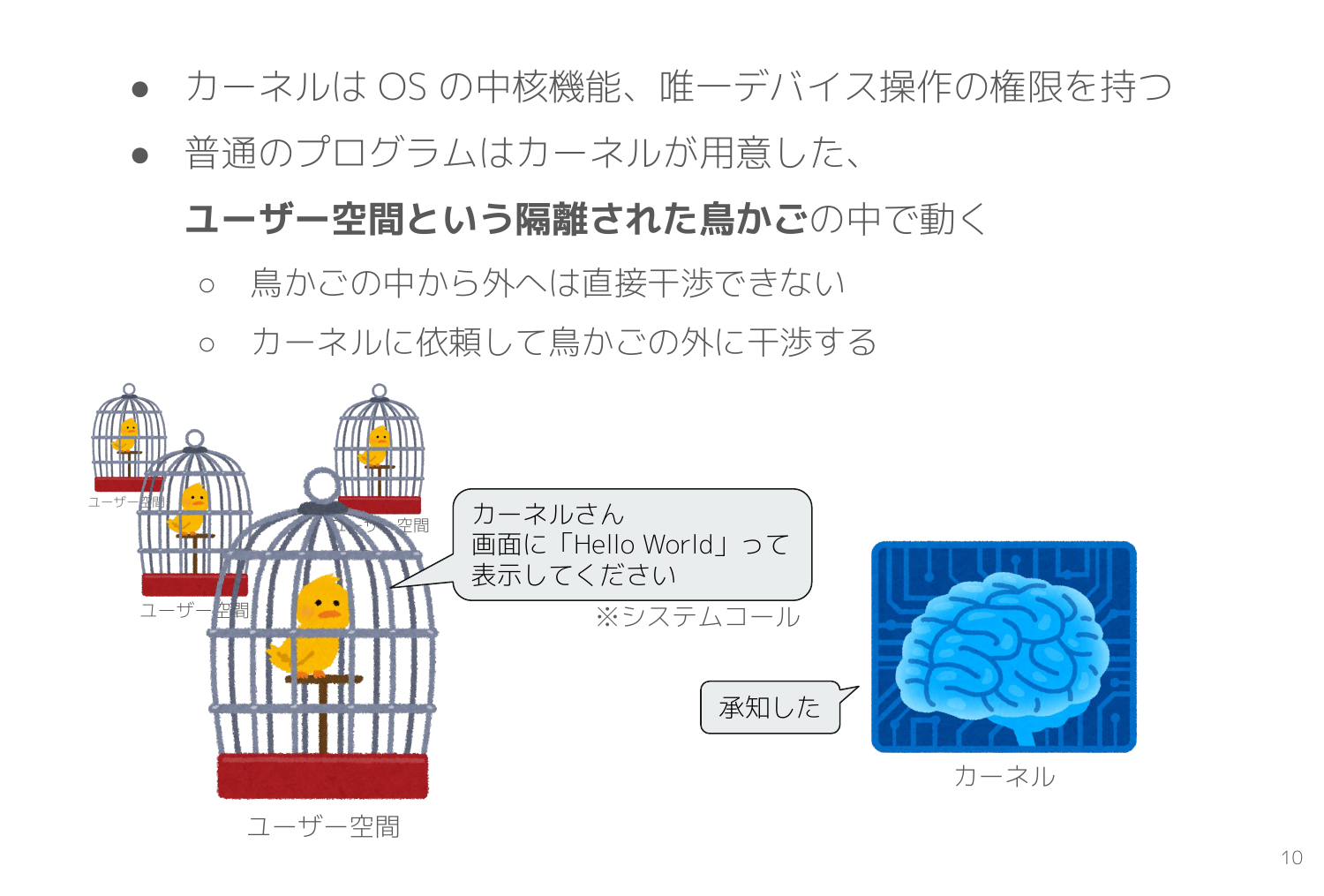
Linuxカーネルとシステムコール
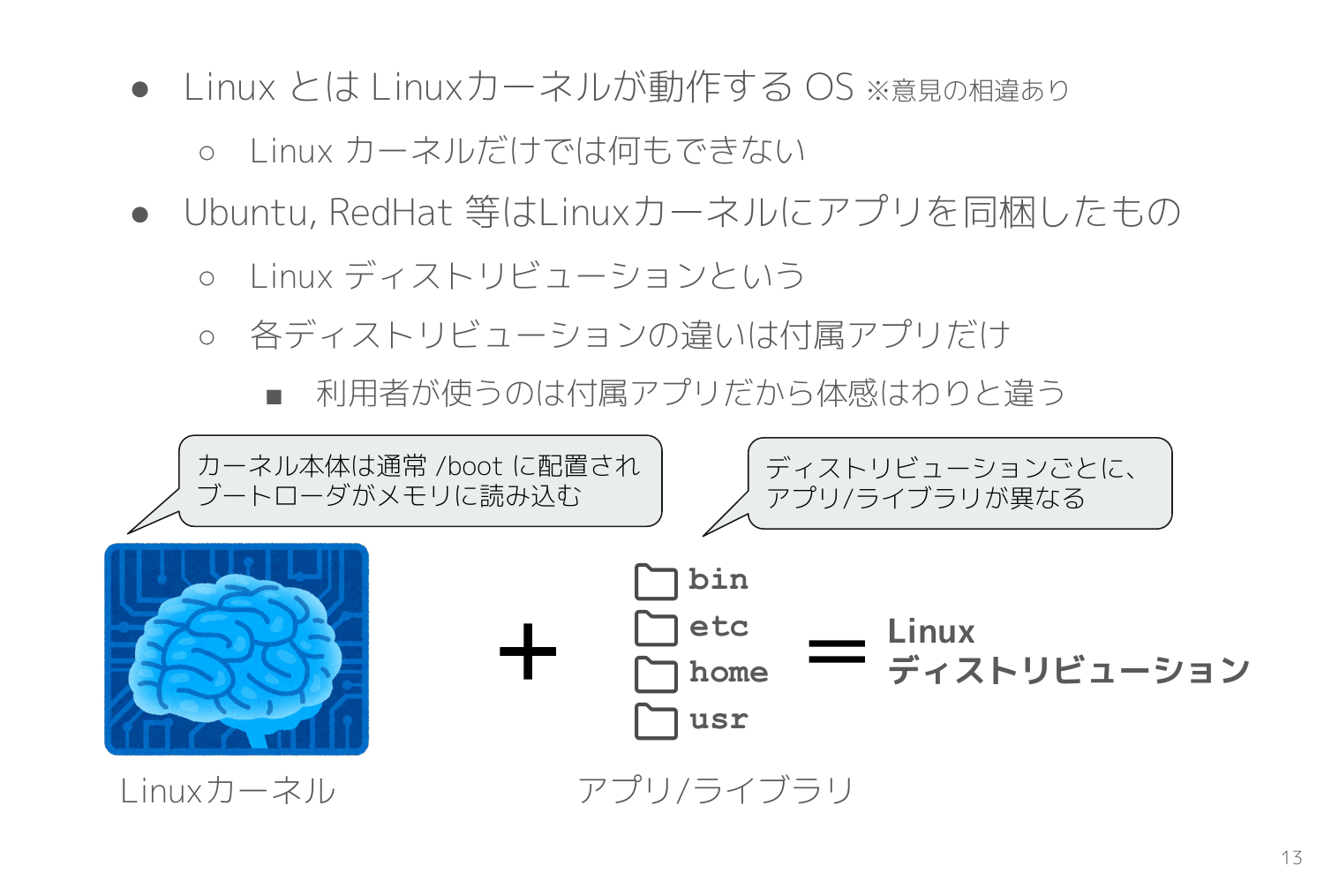
Linux とはなにか?という定義には意見の相違はありますが、ここでは Linux カーネルが動作する OS とします。
Linuxカーネルは OS の中核機能であり唯一デバイス操作可能な機能を持ちますが、実は Linux カーネルだけではなにもできません。
そこで登場するのが Ubuntu, RedHat のようなディストリビューションです。単体ではなにもできない Linux カーネルにアプリやライブラリを組み合わせて、利用者が使いやすい OS としたものが Linux ディストリビューションです。
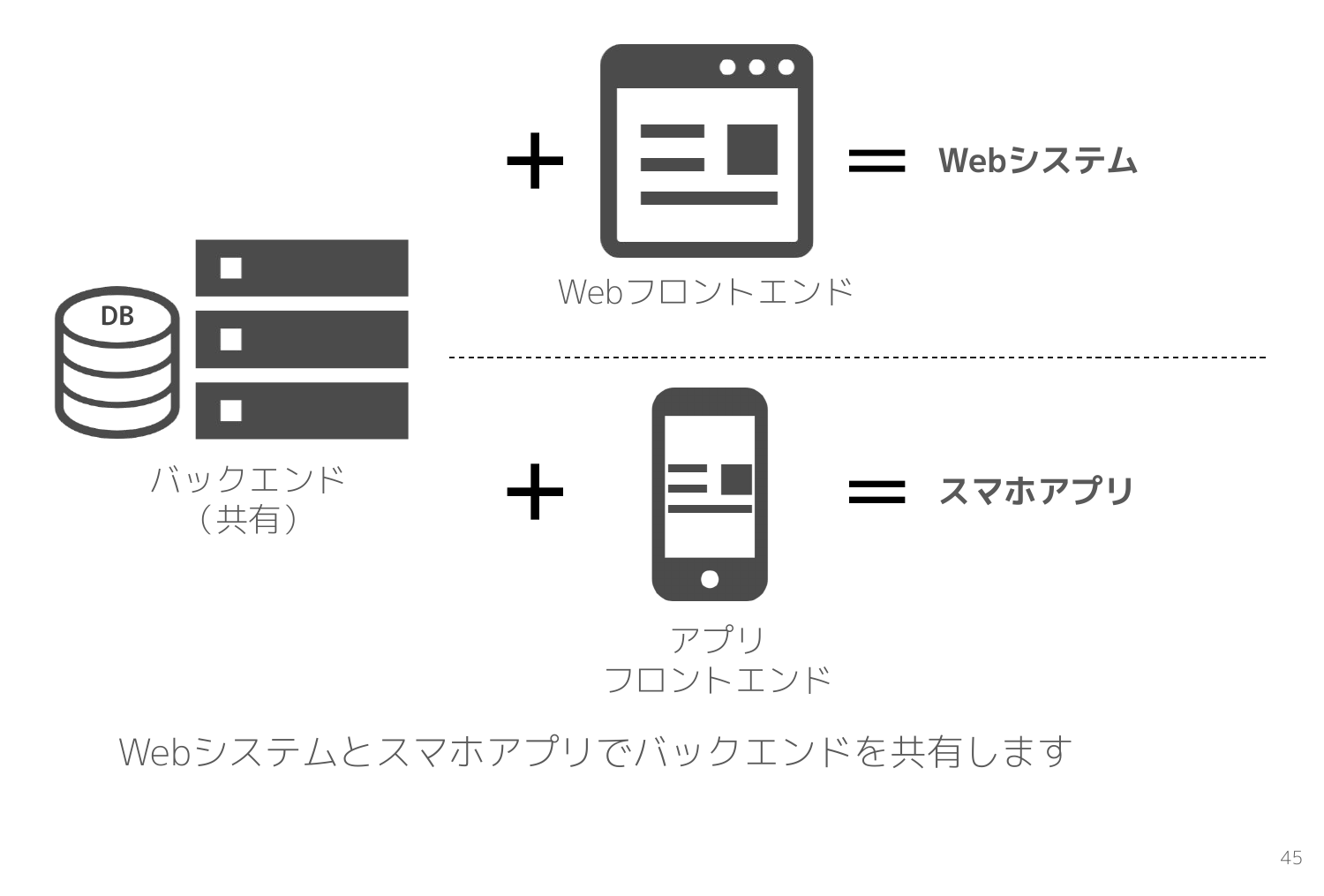
Webエンジニアに分かりやすく例えるならば、 Linuxカーネルとは Webシステムのバックエンド のようなものです。
共通のバックエンドに Web用のフロントエンドと組み合わせると Webシステムとなり、スマホアプリのフロントエンドと組み合わせるとスマホアプリになります。
同一の Linuxカーネルでも組み合わせるアプリやライブラリが異なると、Ubuntu になったり RedHat になったりします。そしてユーザーが直接利用するのはそれらのアプリやライブラリなので、使い勝手や印象はディストリビューションごとに大きく異なります。
Linuxカーネルには重要な機能が多数ありますが、Webシステムのバックエンドと同様で単体では利用できません。
システムコールを観測
Linuxカーネルは有り難いことに 外部から動きを観測しやすい設計 になっています。前述のシステムコールと呼ばれるカーネルへの依頼は strace コマンドで観測できます。
次のスライドは Python の REPL(Read-Eval-Print-Loop)で画面出力とファイル読み込みを行ったのを、スライド右画面の strace で観測した例です。

Python の os パッケージにはシステムコールをそのままラッピングした関数が多数用意されていて、例えば os.write() 関数は write() システムコールに対応します。
スライドの赤枠に注目すると、左画面の REPL で os.write(1, b"Hello, world\n") を実行すると、strace の右画面では write(1, "Hello, world\n", 13) = 13 が出力され、write システムコールが実行される様子を観測できます。
黄色枠は >>> というプロンプトも REPL が write システムコールで表示していることを示しています。
プログラムの骨格はシステムコールの組合せ でできているといっても過言ではないので、strace で観測するとソースコードを持たない未知のプログラムでもおおよその動作仕様を知ることができます。
ファイルディスクリプタと procfs(/proc)
カーネルの持つ膨大な情報を取得するためにそれぞれシステムコールを用意するのは大変なので、Linuxカーネル は procfs と呼ばれる /proc ディレクトリからも様々な情報を取得できるように設計されています。
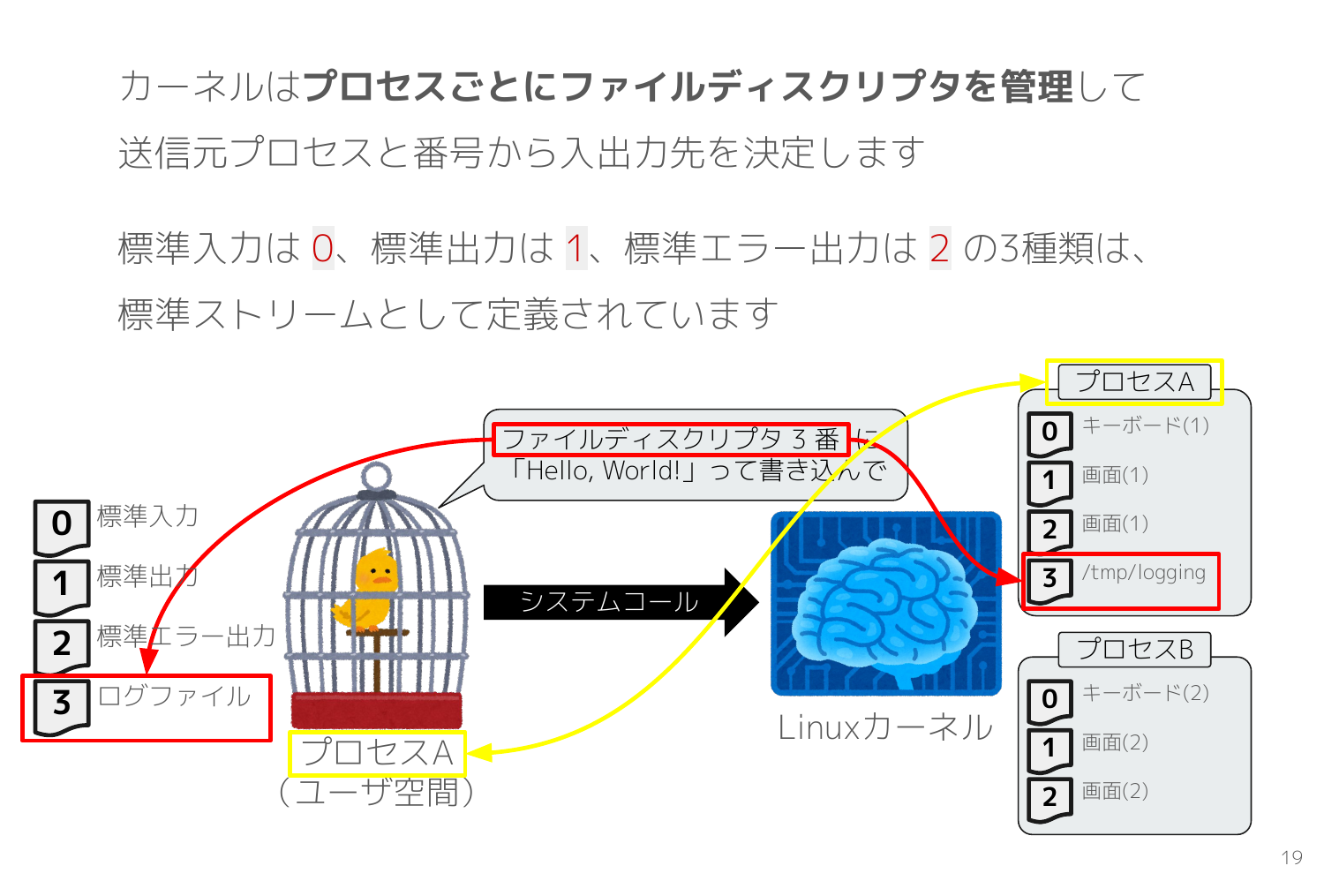
次のスライドは ls -al /proc/<pid>/fd で、sleep infinity 3>/tmp/logging のプロセスが持つファイルディスクリプタの一覧を取得しています。このプロセスは、標準入力0、標準出力1、標準エラー出力2に加えて、ファイルディスクリプタ3 で/tmp/logging を開いていることが procfs の情報から分かります。
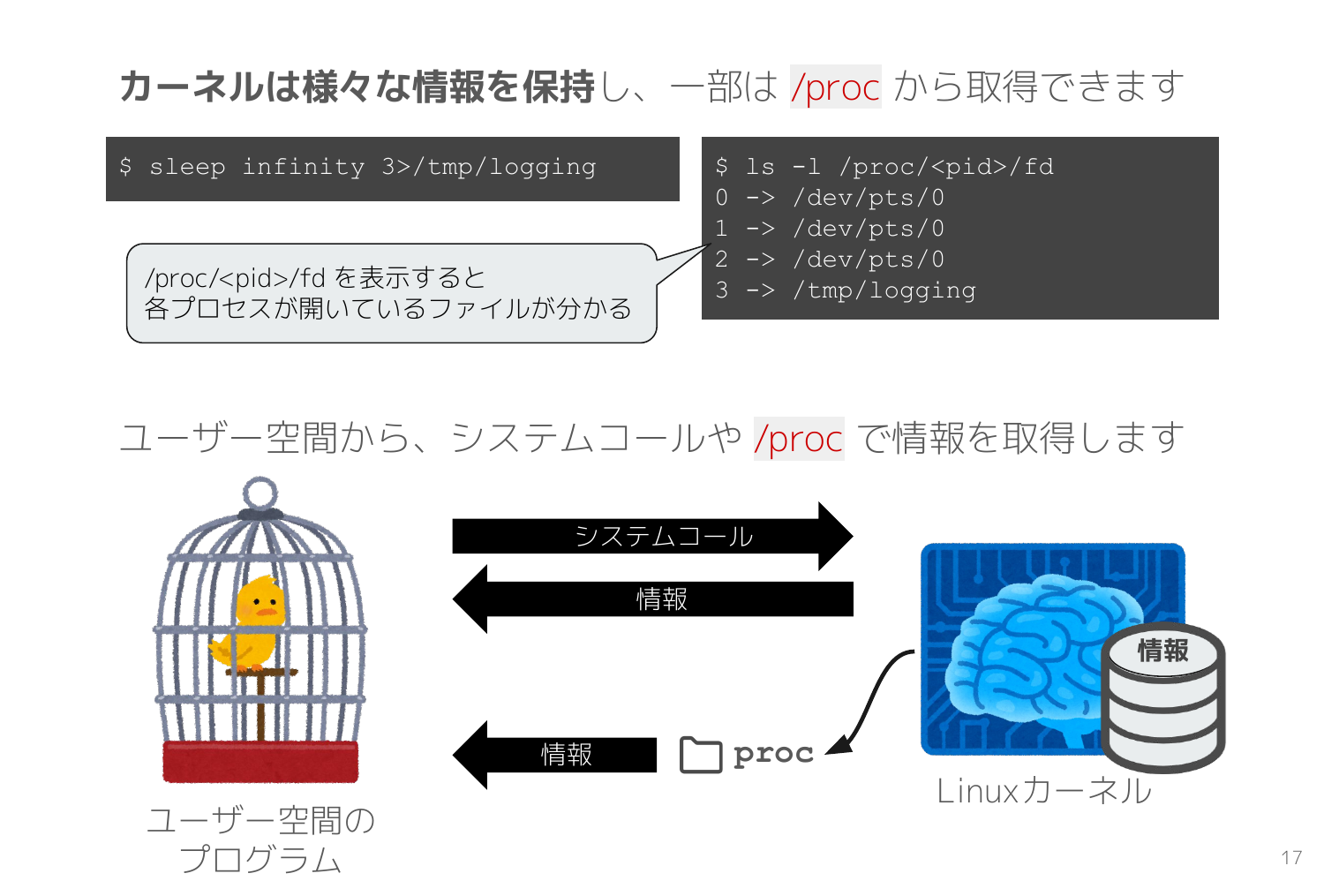
ファイルディスクリプタはカーネルとユーザー空間のプログラムの双方で管理する数値 であり、システムコールで入出力先を指示するために利用されます。
次のスライドの赤枠に注目すると、プロセスAがファイルディスクリプタ3番に書き込むシステムコールを発行して、カーネルはそのシステムコールを受けてプロセスAのファイルディスクリプタの中から3番を探して /tmp/logging に書き込みます。
Python でファイルを開いてデータを書き込む流れを、ファイルディスクリプタ・システムコールの動きと共に観測してみます。
strace を -f フラグ付きで実行すると指定したプロセスの子プロセスも自動的に観測対象としてくれます。
そこで bash のプロセスID を echo $$ で確認して、そのプロセスIDを指定した次のコマンドで strace を開始してから Python の REPL を実行します。
strace -f -p <pid> --trace=openat,write,close
--trace は観測対象とするシステムコールを指定できます。プログラム実行開始から観測すると膨大なシステムコールが表示されて分かりづらいので、必要なシステムコールだけにします。
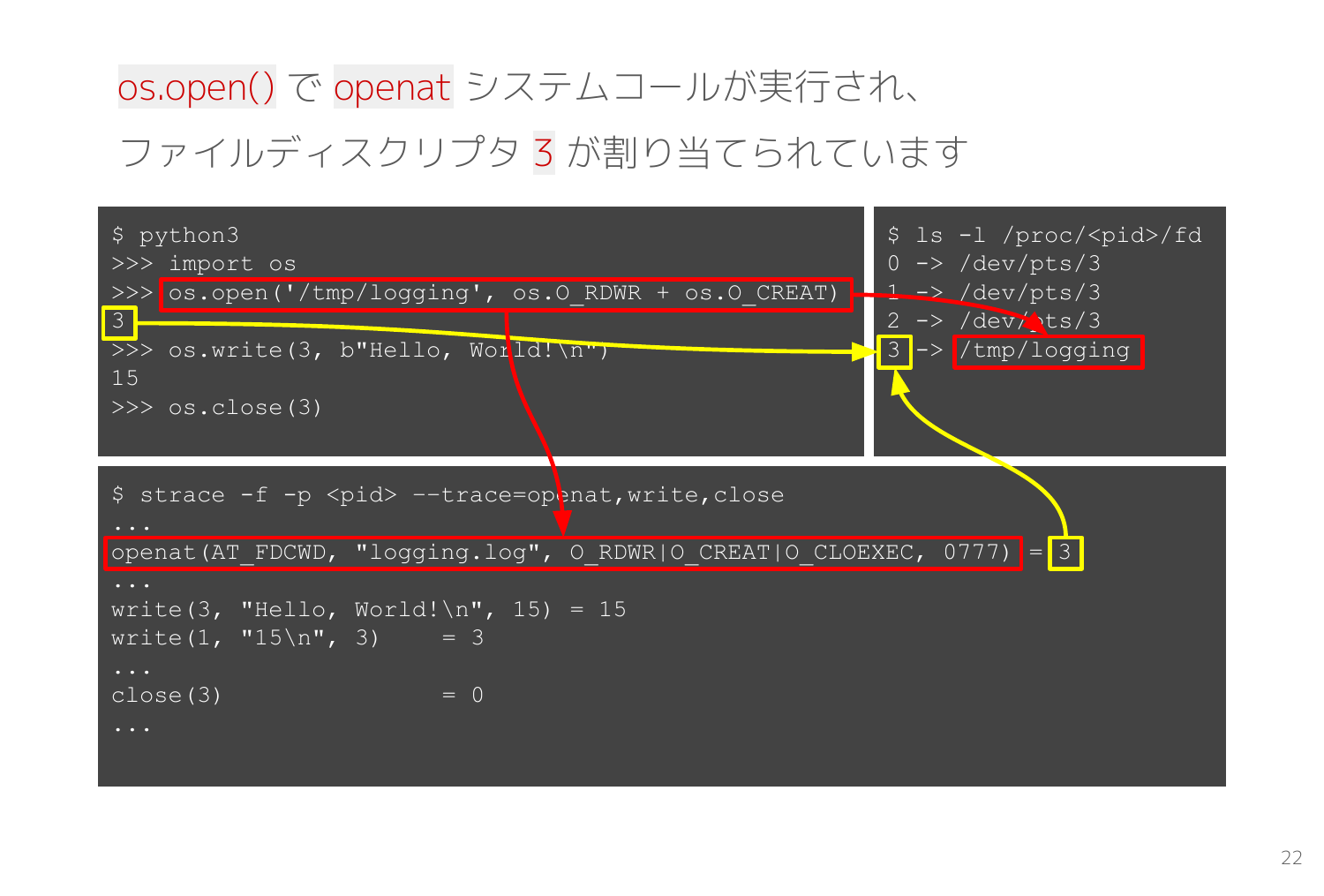
スライドの赤枠を見ると、REPL で os.open('/tmp/logging', os.O_RDWR + os.O_CREAT) を実行すると(※左上)、strace では openat(AT_FDCWD, "logging.log", O_RDWR|O_CREAT|O_CLOEXEC, 0777) が出力されて(※下)、ファイルディスクリプタに 3 -> /tmp/logging が増える(※右上)状況を観測できます。
os.open() openat() の戻り値は開かれたファイルディスクリプタです。その後の os.write() で書き込む先のファイルディスクリプタとして利用して、最後は os.close() で閉じています。
シェルのリダイレクト
bash などのシェルが持つリダイレクト機能の実体はファイルディスクリプタの操作です。
>dev/null を付けて実行したプログラムのファイルディスクリプタを /proc で確認すると、標準出力 1 -> /dev/null となっています。
あまり知られていませんが、リダイレクト機能ではファイルディスクリプタを閉じることもできます。
>&- を付けて実行したプログラムを /proc で確認すると、以下のスライドの通り標準出力1が無くなってしまっています。標準ストリーム(0, 1, 2)はプログラムが正常動作する前提条件なので、たいていのプログラムは正常動作しません。

リダイレクト機能で開かれたファイルディスクリプタは実行されたプロセスから利用できます。
bash から python3 10>logging で実行した Python プロセスはファイルディスクリプタ10 を持っているので、os.write(10, b"Hello!\n") を実行すると、カレントディレクトリの logging ファイルに Hello! が書き込まれます。複数のリダイレクトを付けて実行すれば複数のファイルディスクリプタを利用できます。
通常のシステム開発では高レイヤのファイル操作API を利用するのでファイルディスクリプタを理解しにくいですが、実際に低レイヤで操作してみると単なる数値で管理されて、その数値を指定して書き込むだけの単純な仕組みだと分かります。

プロセス起動のシステムコール
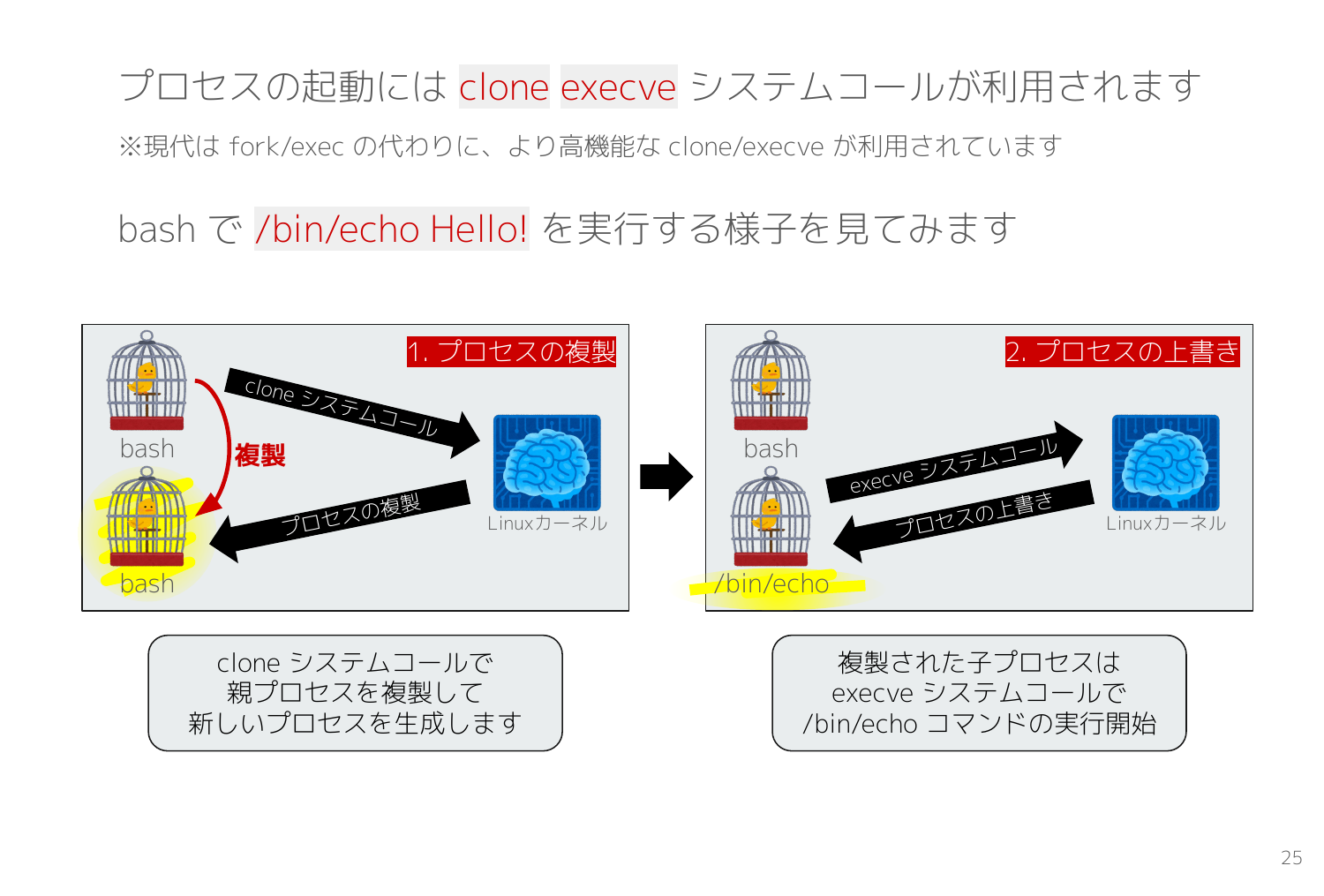
次はプロセス起動に利用する clone execve システムコールを観測します。昔は fork/exec でしたが今はより高機能な clone/execve が利用されています。
次のスライドは /bin/echo を実行する様子を表します。Linuxカーネルにおけるプロセスの作成とは、親プロセスをコピーしてそっくり同じものを作ることであり、clone システムコールで実施します。しかしそれだけでは親プロセスのプログラムが動いてしまうので、続けて複製された子プロセス側で execve システムコールを発行して実行したいコマンド(/bin/echo)に上書きすることで任意のプログラムを実行します。
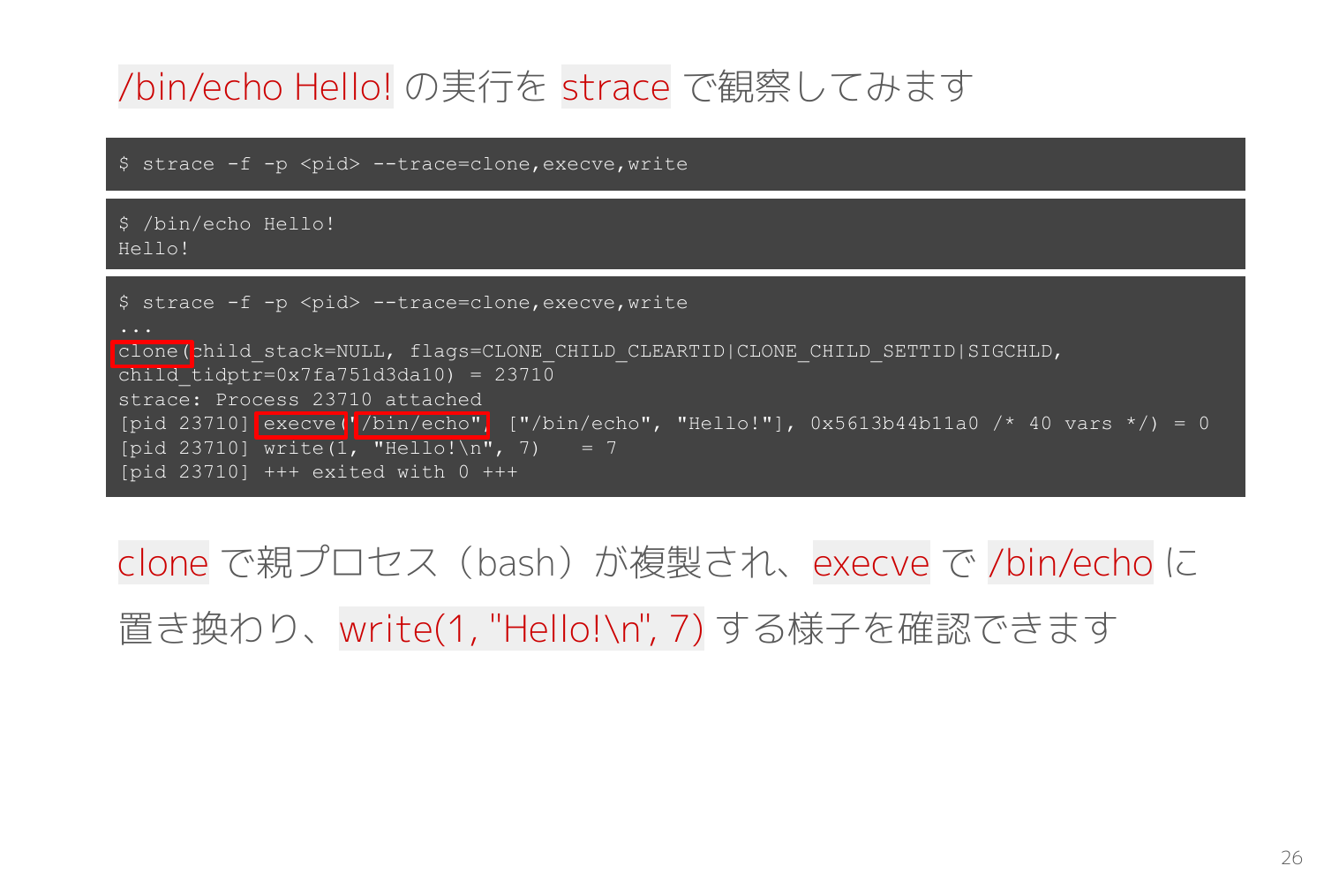
実際にプロセス起動のシステムコールを観測したのが次のスライドです。
clone システムコールのタイミングで strace -f が新たに生成された子プロセスを観測対象としている様子と、その子プロセス側で execve システムコールが発行されて /bin/echo に置き換わる様子を観測できます。
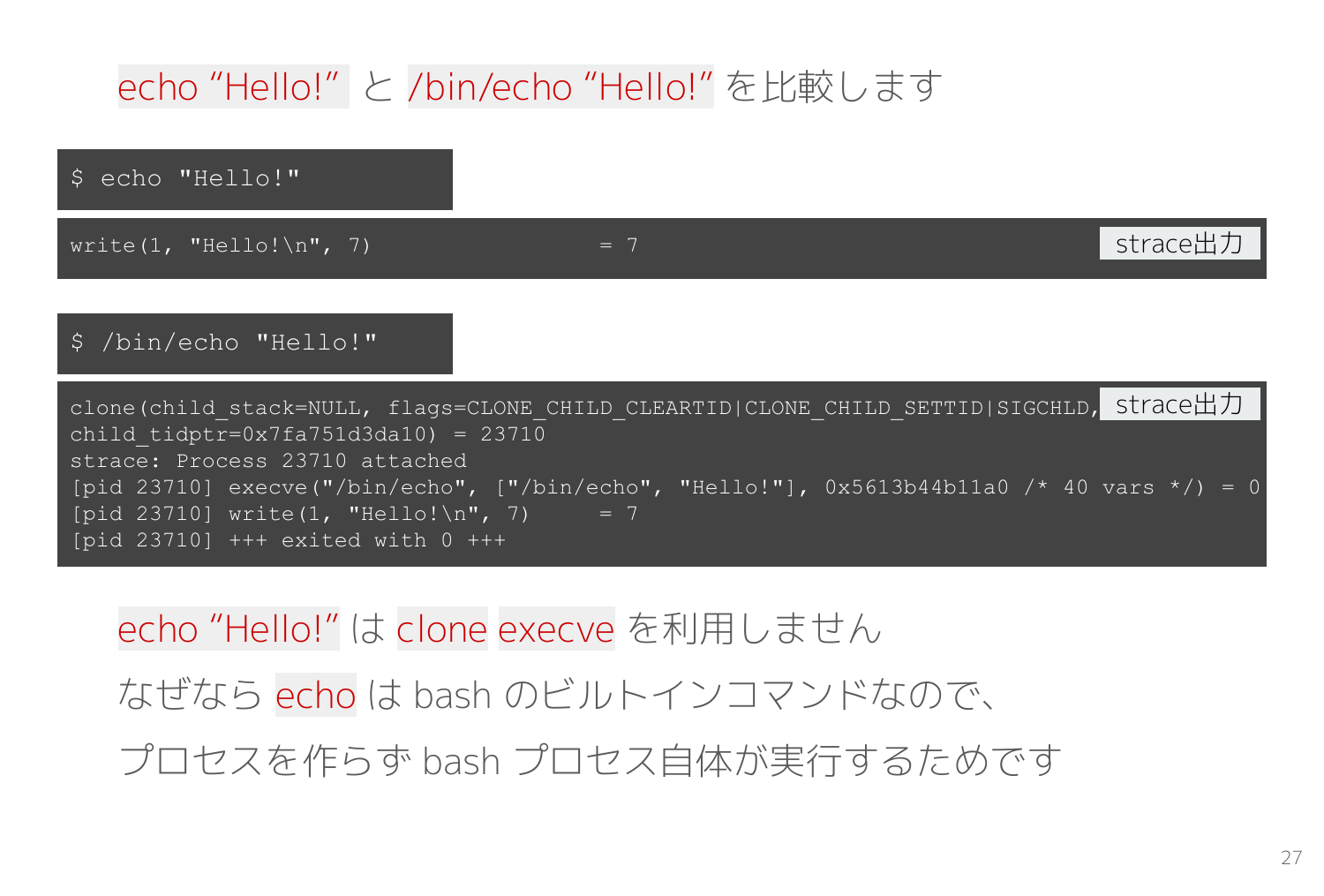
ところで、先ほどはわざわざ /bin/echo としたのは理由があります。
bash には echo という同名のビルトインコマンドが存在するため、単に echo とするとビルトインコマンドが実行されます。
次のスライドではビルトインコマンドを実行してシステムコールを観測していますが、当然のことながらビルトインコマンドは bashプロセス自体が処理するため clone execve で新しいプロセスは作られず、代わりに bash が write(1, "Hello!\n", 7) を実行する様子を観測できます。
clone は元にするプロセスをそっくりそのまま複製して子プロセスを作り出すので、ファイルディスクリプタも複製されます。
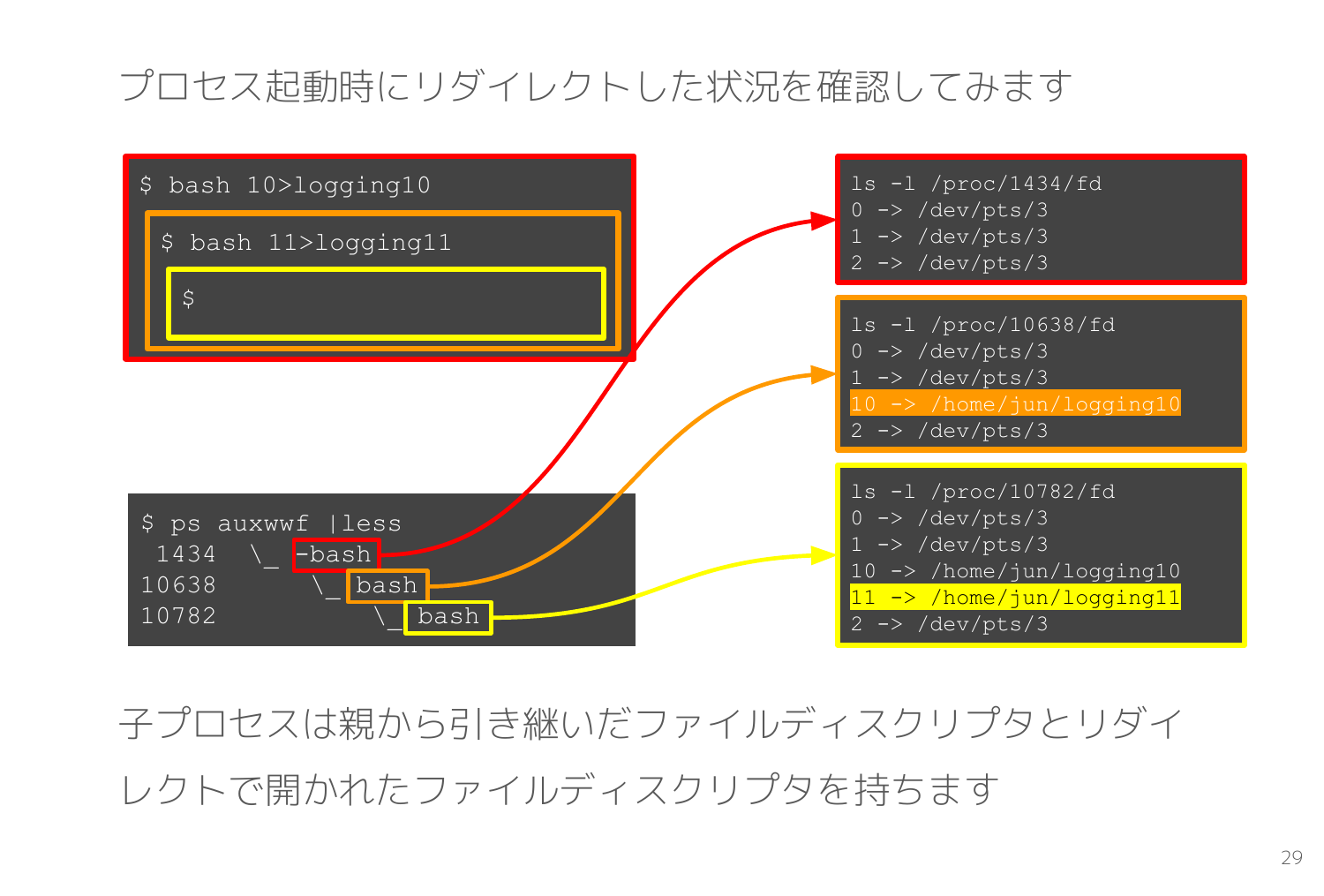
以下のスライドでは親の bash から bash 10>logging10 で子プロセスを起動して、さらに孫プロセスとなる bash 11>logging11 を起動しています。
すると孫プロセスである黄色枠で示した bash プロセスは子プロセス実行時に開いたファイルディスクリプタ10 と孫プロセス実行時に開いたファイルディスクリプタ11 の両方を持ちます。
tty/pts とは
ユーザーと Linux OS の接点となる画面やキーボードは tty/pts という端末アプリで制御されています。ls -al /proc/<pid>/fd で表示される /dev/pts/<n> が tty/pts です。
そこで、tty/pts の動きを探ってみます。
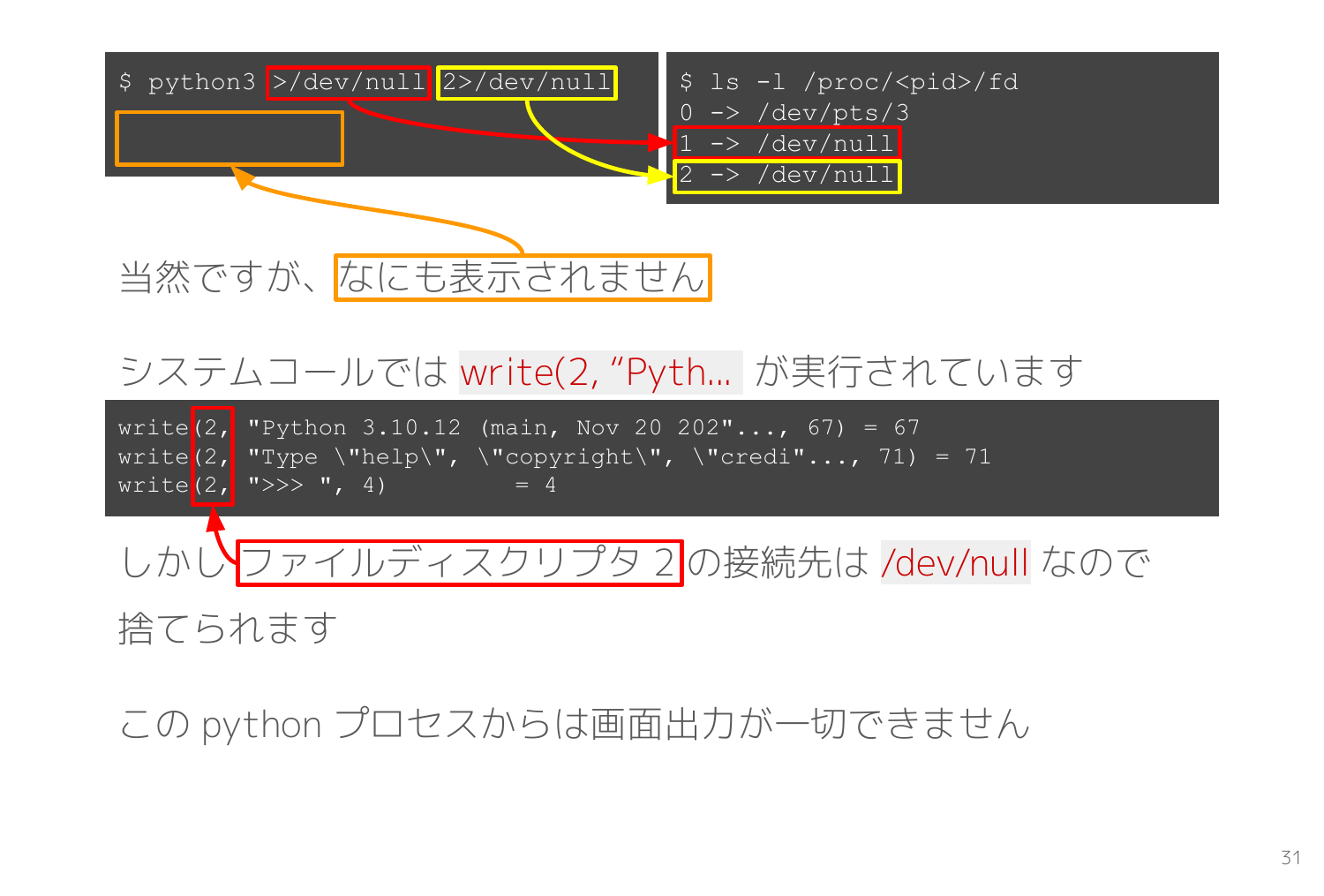
標準出力・標準エラー出力を /dev/null へリダイレクトした状態で Python の REPL を起動してみます。
REPL を起動すると write(2, "Python 3.10.12 (main, Nov 20 202"..., 67) というシステムコールが発行されて、通常は Python 3.10.12 (main, Nov 20 202... という起動メッセージが表示されます。 しかし今回は以下のスライドの通り、ファイルディスクリプタ2 の接続先が /dev/null なので画面には何も表示されません。
>>> というプロンプトも表示されず、画面には一切の表示がありません。
ここまでは /dev/null へリダイレクトした際のよくある動作なので皆さんもなじみ深いと思いますが、この状態からでも画面表示を行う方法があるとしたら興味を惹かれませんか?
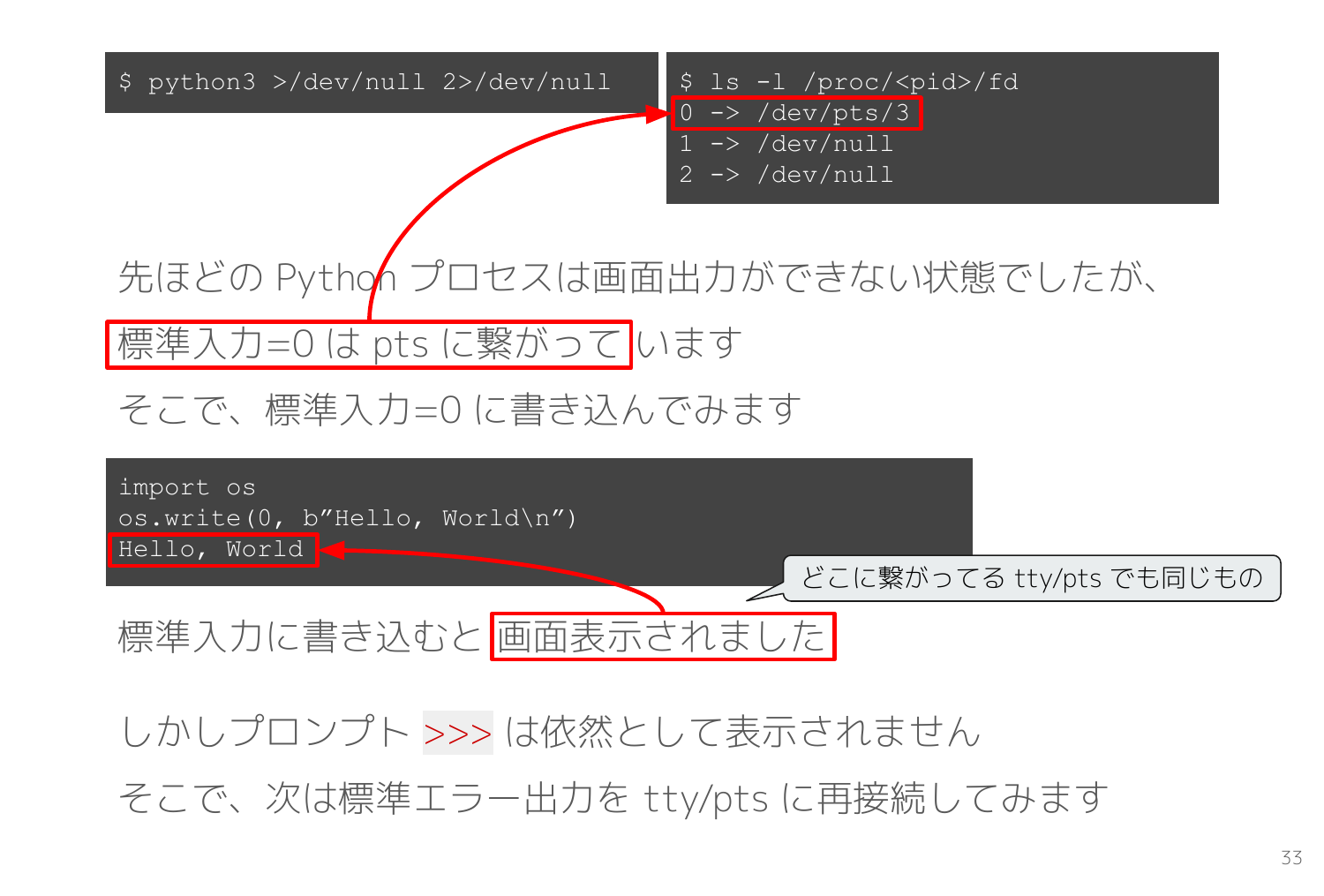
この Python REPL のプロセスはファイルディスクリプタ0 が tty/pts に接続されています。
実は標準ストリーム 0, 1, 2 に接続される tty/pts とはいずれも同一のものであり、いずれも読み書き可能です。
そこで標準入力0 に書き込むという暴挙を以下のコードで実行すると、なんと画面に Hello, World と表示されます。
import os
os.write(0, b"Hello, World\n")
Hello, World
次は >>> も表示できるようにしてみます。
dup2 システムコールはファイルディスクリプタの複製が可能です。幸いなことに Python には os.dup2 というラッパー関数が用意されているので tty/pts が繋がっている標準入力0 を標準エラー出力2 へ複製してみます。
os.dup2(0, 2)
>>>
すると REPL の >>> プロンプトが表示されるようになりました。REPL は入力された Python コードを実行するたびに write(2, ">>> ", 4) システムコールでプロンプトを出力しますが、ファイルディスクリプタ2 は /dev/null へ繋がっていたので画面に表示されることはなく捨てられます。しかし dup2 システムコールで tty/pts をファイルディスクリプタ2 へと複製したので tty/pts を通じて画面に >>> が表示されるようになりました。
ls -l /proc/<pid>/fd の結果でも 2 -> /dev/pts/<n> となり、標準エラー出力が tty/pts に接続されている様子を確認できます。

異なる tty/pts に接続
tty/pts への書き込みは利用者のターミナル(端末)にそのまま表示されます。これはごく単純な仕組みなので、権限の範囲内で他のセッションが利用している tty/pts に書き込むこともできます。
別のターミナルと接続されている tty/pts のデバイスファイルにそのまま書き込むだけです。
echo -e "\ntasuke..te..." >/dev/pts/<n>
書き込まれた側は、唐突に tasuke..te... と表示されて、ちょっとした心霊現象を楽しむことができます。

手順は若干複雑ですが、その逆で tty/pts の読み込みを乗っ取ることも可能です。
標準入力(tty/pts)からの読み込みは各プログラムが任意に行います。例えば Python REPL や bash などは tty/pts へ入力された内容をすぐに読み込むので複数プロセスが同一の tty/pts から読み込むと入力の奪い合いになり操作が困難になります。
そこでまずは乗っ取られる側のターミナル(端末)で sleep などの標準入力を読み込まない適当なコマンドを実行して待機します。次にもう片方のターミナルの Python REPL で以下のコードを実行します。(※ <n> <m> はそれぞれ適切な数値に置き換える)
import os
os.open("/dev/pts/<n>", os.O_RDONLY)
os.dup2(<m>, 0)
すると、乗っ取られた側のターミナル(sleep)に対してキーボード入力した内容が、乗っ取った側の端末(Python REPL)にそのまま表示されて、Enter を押すと REPL で実行されます。
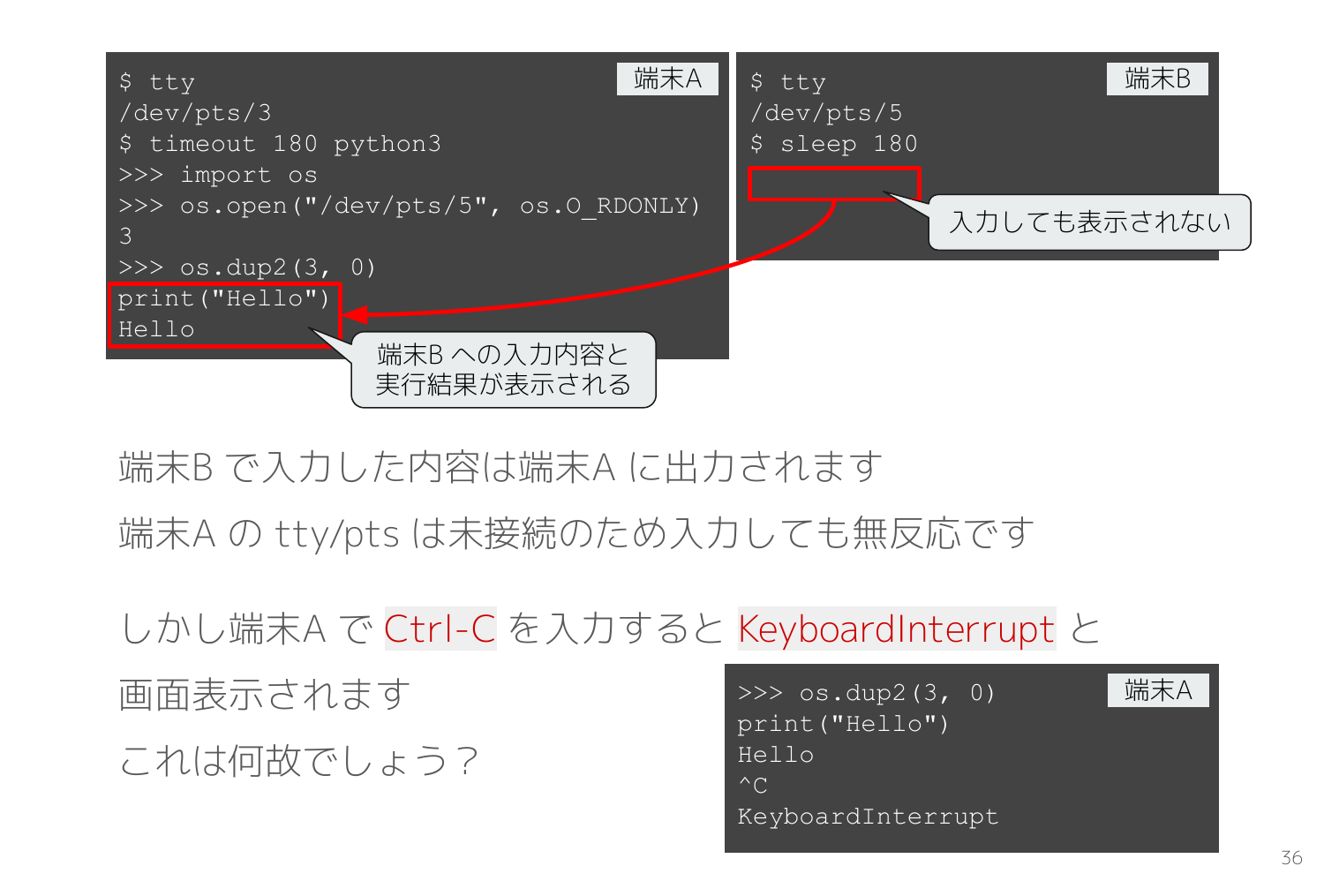
乗っ取った側のターミナル(Python REPL)では何を入力しても反応はありません。なぜならそのターミナルの tty/pts は Python REPL の標準入力に繋がっていないので、REPL が読み込むことはないからです。
しかし Ctrl-C だけは反応があり、通常の REPL と同様に KeyboardInterrupt が返ってきます。つまり正常に届いているようです。
次はこれが何故なのかを考えて見ます。
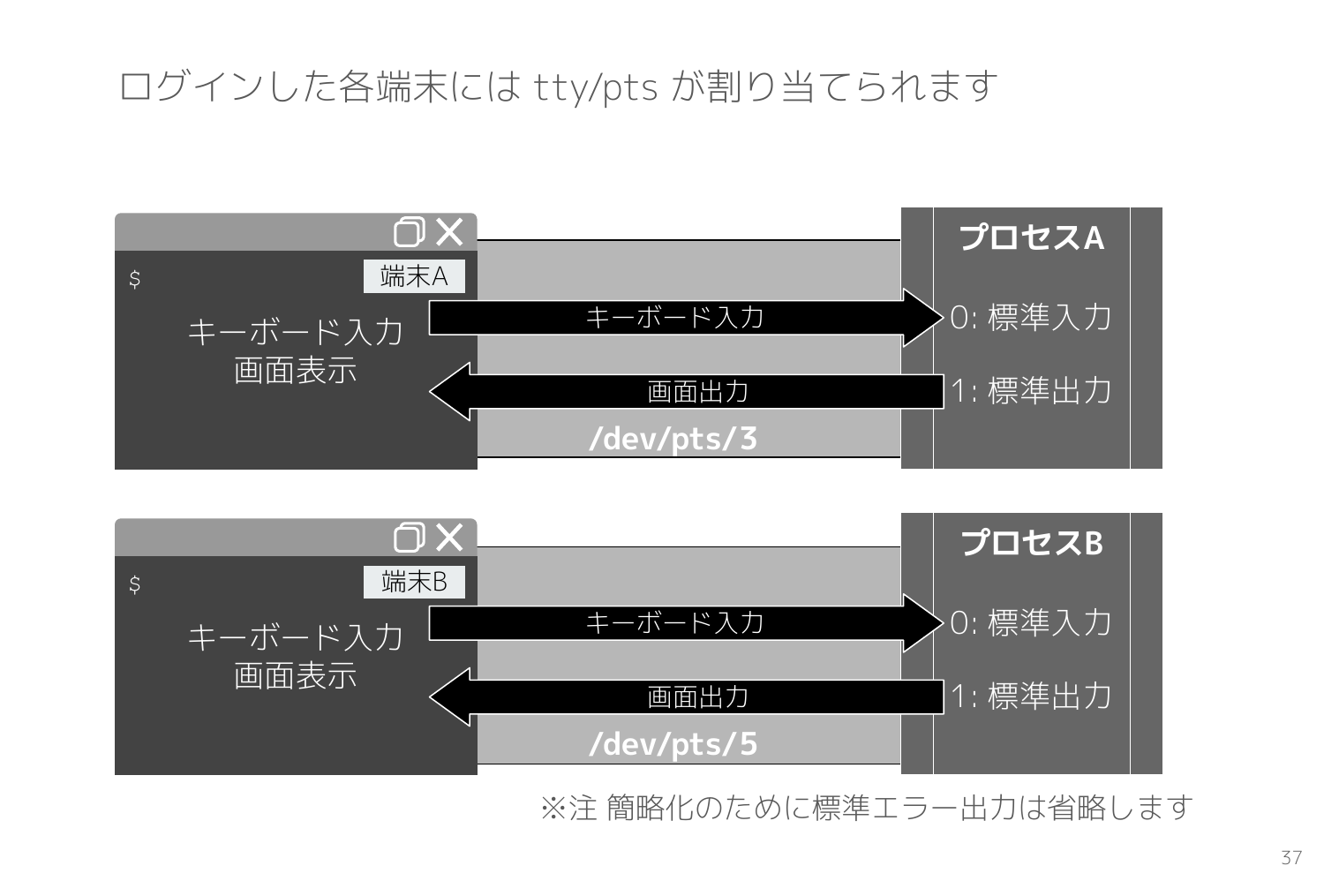
ターミナル(端末)とプロセスと tty/pts の関係性は以下のスライドの通りで、ssh 等でログインすると新しい tty/pts が割り当てられて、ターミナルとプロセス(bash)を繋ぐ役割を担います。ログインセッションごとに tty/pts は割り当てられます。
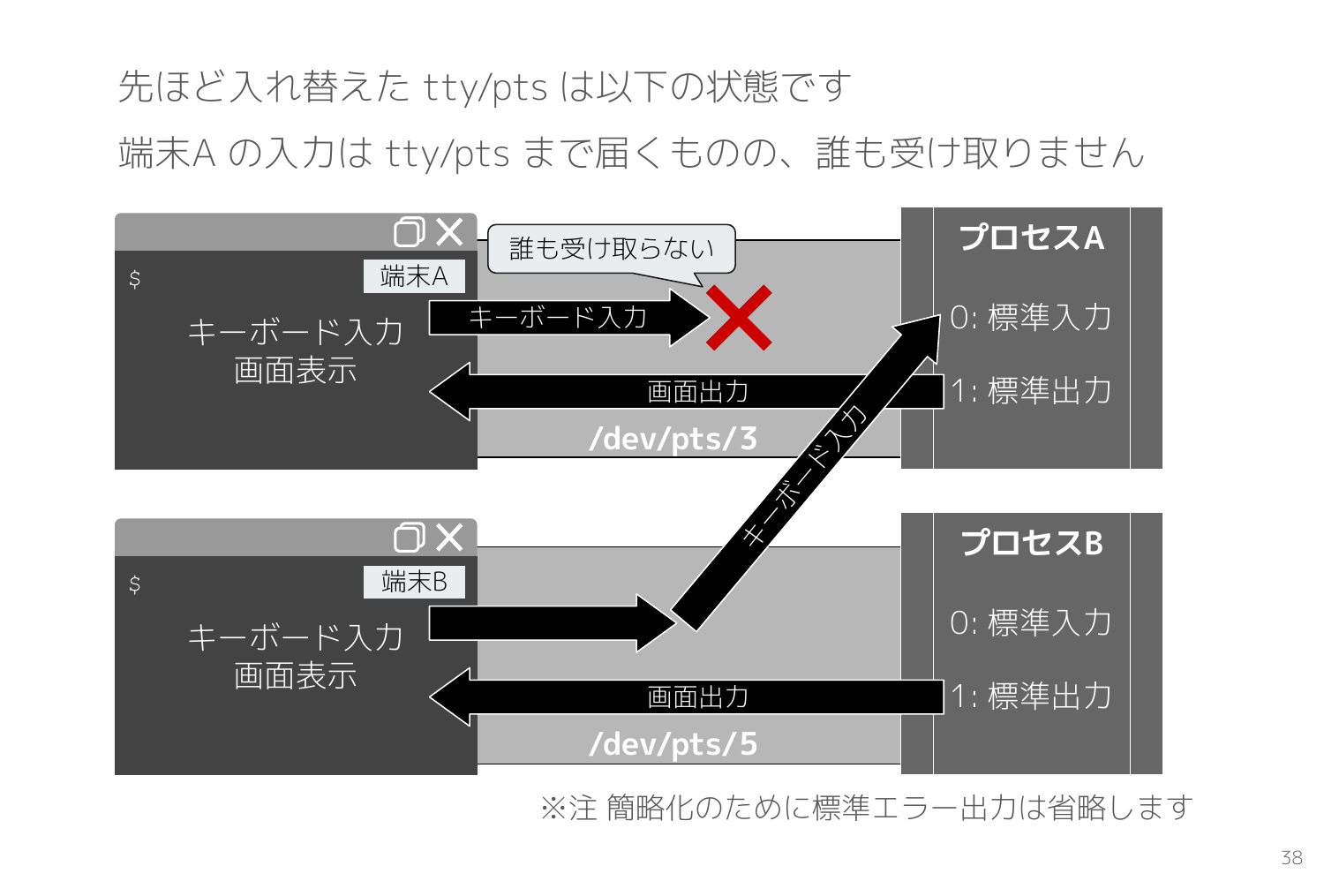
先ほど tty/pts を乗っ取った後は以下のスライドの状態になっていました。
Python REPL を実行している端末Aの tty/pts から読み込むプロセスは存在しないため、何を入力してもどのプロセスも読み込んでくれません。
sleep を実行している端末Bの tty/pts は端末A上の Python REPL プロセスの標準入力に接続されたため、端末Bの入力内容はそのまま REPL への入力として処理されます。
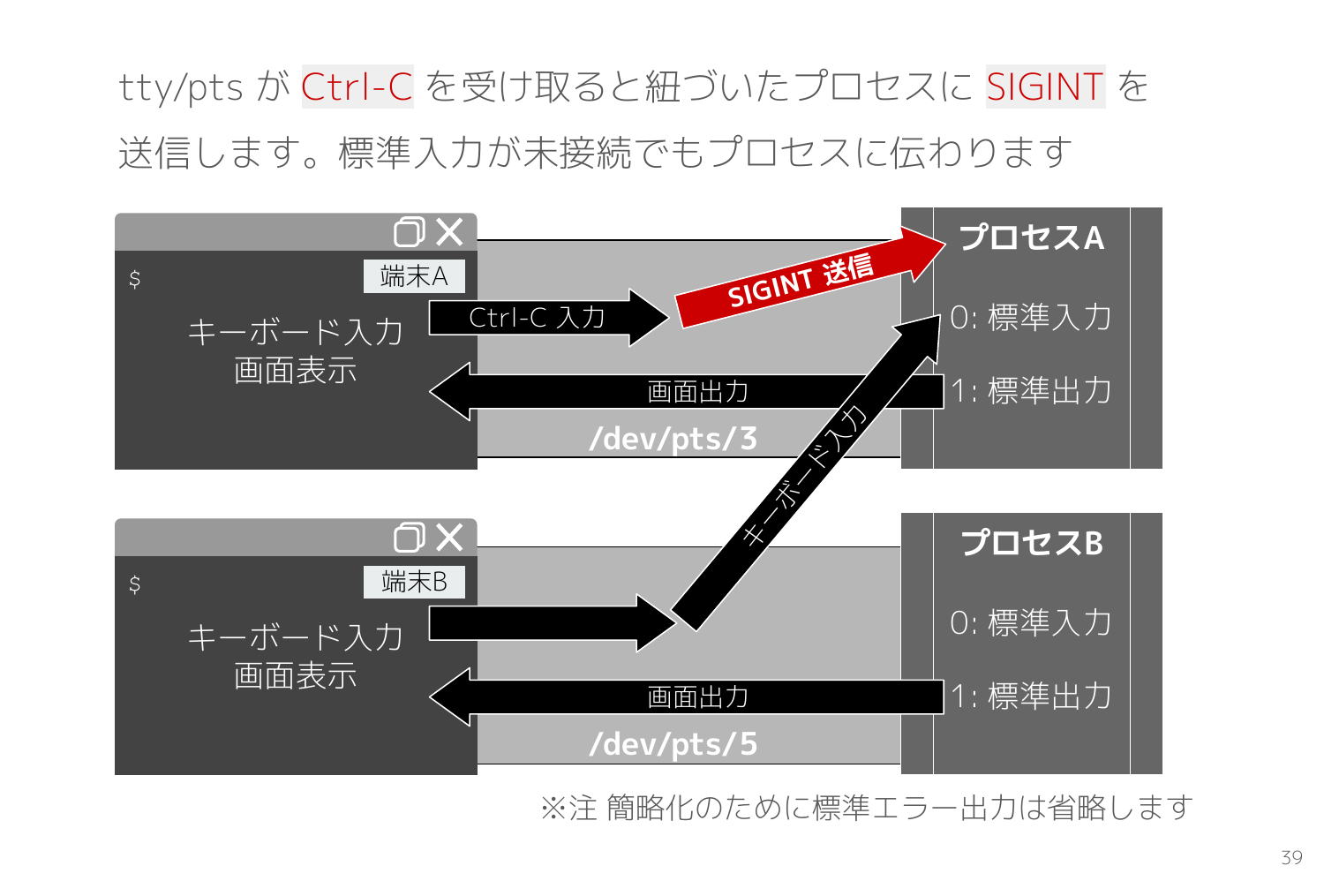
ではなぜ Ctrl-C だけは Python REPL プロセスへ届いたかというと、Ctrl-C はシグナルで送信されるからです。
通常のキーボード入力は各プロセスが標準入力から任意に読み込みますが、Ctrl-C が入力されると tty/pts は紐づくプロセスへ SIGINT を送信します。端末A の tty/pts が紐づくプロセスは Python REPL なので、SIGINT は Python REPL のプロセスへ届き、Python REPL が SIGINT に対応する処理(※KeyboardInterrupt と出力)をします。
TCP通信とシステムコール
TCP/UDP などの通信もシステムコールを通じてカーネルが処理します。
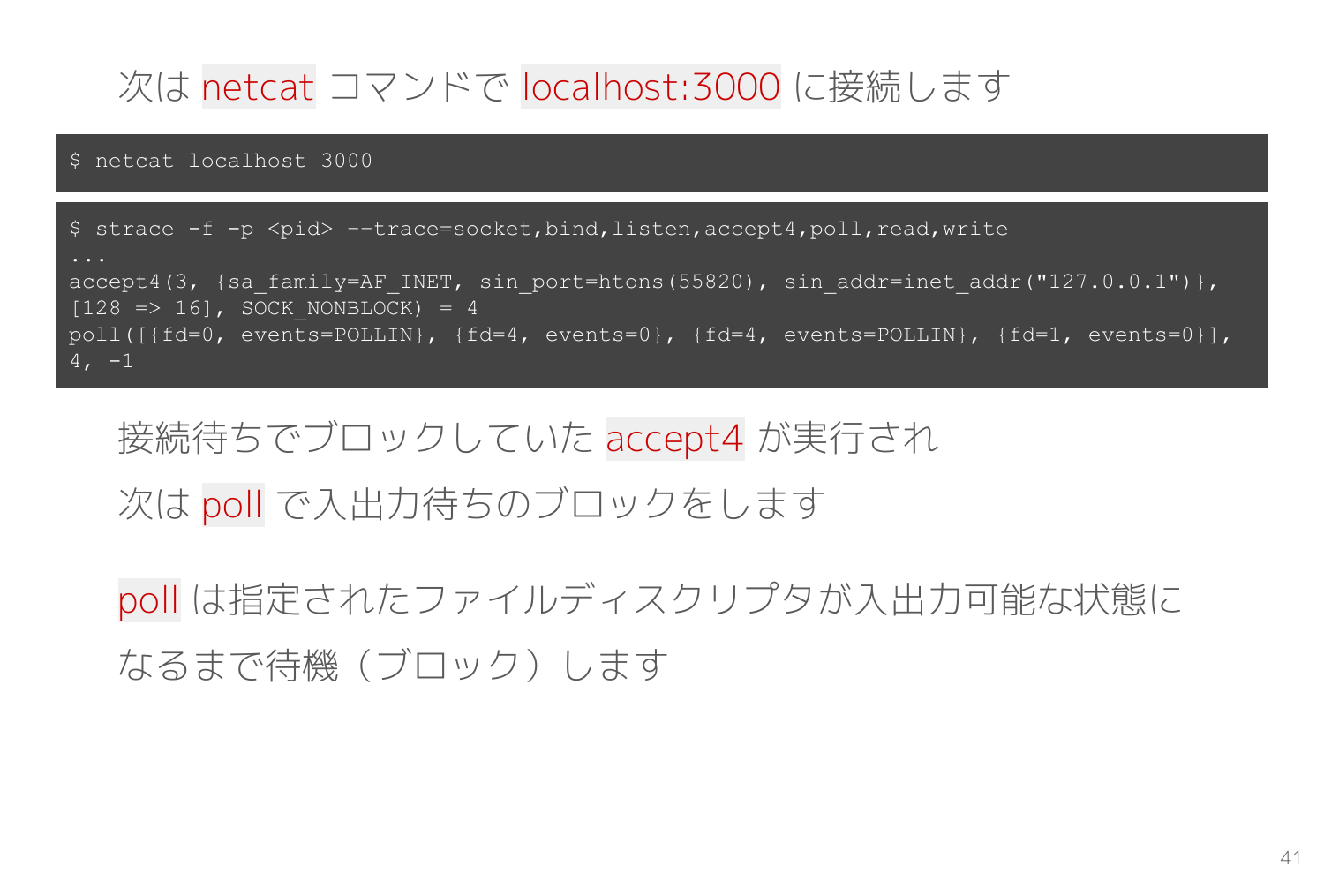
TCP での待ち受け(サーバ)と接続(クライアント)の両方の役割をこなせる netcat コマンドを strace で観測して TCP通信に利用するシステムコールを確認します。

netcat -k -l 3000 で 3000番ポートにて待ち受けすると、socket bind listen accept4 が順番に実行されました。
$ strace -f -p <pid> ––trace=socket,bind,listen,accept4,poll,read,write
...
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 3
bind(3, {sa_family=AF_INET, sin_port=htons(3000), sin_addr=inet_addr("0.0.0.0")}, 16) = 0
listen(3, 1) = 0
accept4(3,
bind システムコールの引数で待ち受けする IPアドレスとポートが設定されています。これで netcat のプロセスはカーネルに対して「0.0.0.0:3000 に接続が来たら私に教えてください」とお願いしています。
listen で接続待ち状態に移行して accept4 で接続が来るまでブロッキングします。
続いて別のターミナルから netcat localhost 3000 で先ほど待ち受けたポートに接続すると、待ち受けしていた側の netcat は以下のように accept4 の応答が返ってファイルディスクリプタを割り当てられ、poll でブロッキングして入力データを待ちます。
...
accept4(3, {sa_family=AF_INET, sin_port=htons(55820), sin_addr=inet_addr("127.0.0.1")}, [128 => 16], SOCK_NONBLOCK) = 4
poll([{fd=0, events=POLLIN}, {fd=4, events=0}, {fd=4, events=POLLIN}, {fd=1, events=0}], 4, -1
netcat はサーバとクライアントの双方向でデータを送信可能なので、poll では accept4 で得た TCP接続のファイルディスクリプタに加えて標準入力も待ち受けています。
では、接続した側の netcat から Hello, World! という文字列を送信してみます。
strace では受信側を観測しているので、ブロッキングしていた poll の応答で TCP接続のファイルディスクリプタが返却され、そのファイルディスクリプタから read して、標準出力へそのまま write して、再び poll で入力データを待つ一連の処理が出力されました。
poll([{fd=0, events=POLLIN}, {fd=4, events=0}, {fd=4, events=POLLIN}, {fd=1, events=0}], 4, -1) = 1 ([{fd=4, revents=POLLIN}])
read(4, "Hello, World!\n", 16384) = 14
poll([{fd=0, events=POLLIN}, {fd=4, events=0}, {fd=4, events=POLLIN}, {fd=1, events=POLLOUT}], 4, -1) = 1 ([{fd=1, revents=POLLOUT}])
write(1, "Hello, World!\n", 14) = 14
poll([{fd=0, events=POLLIN}, {fd=4, events=0}, {fd=4, events=POLLIN}, {fd=1, events=0}], 4, -1
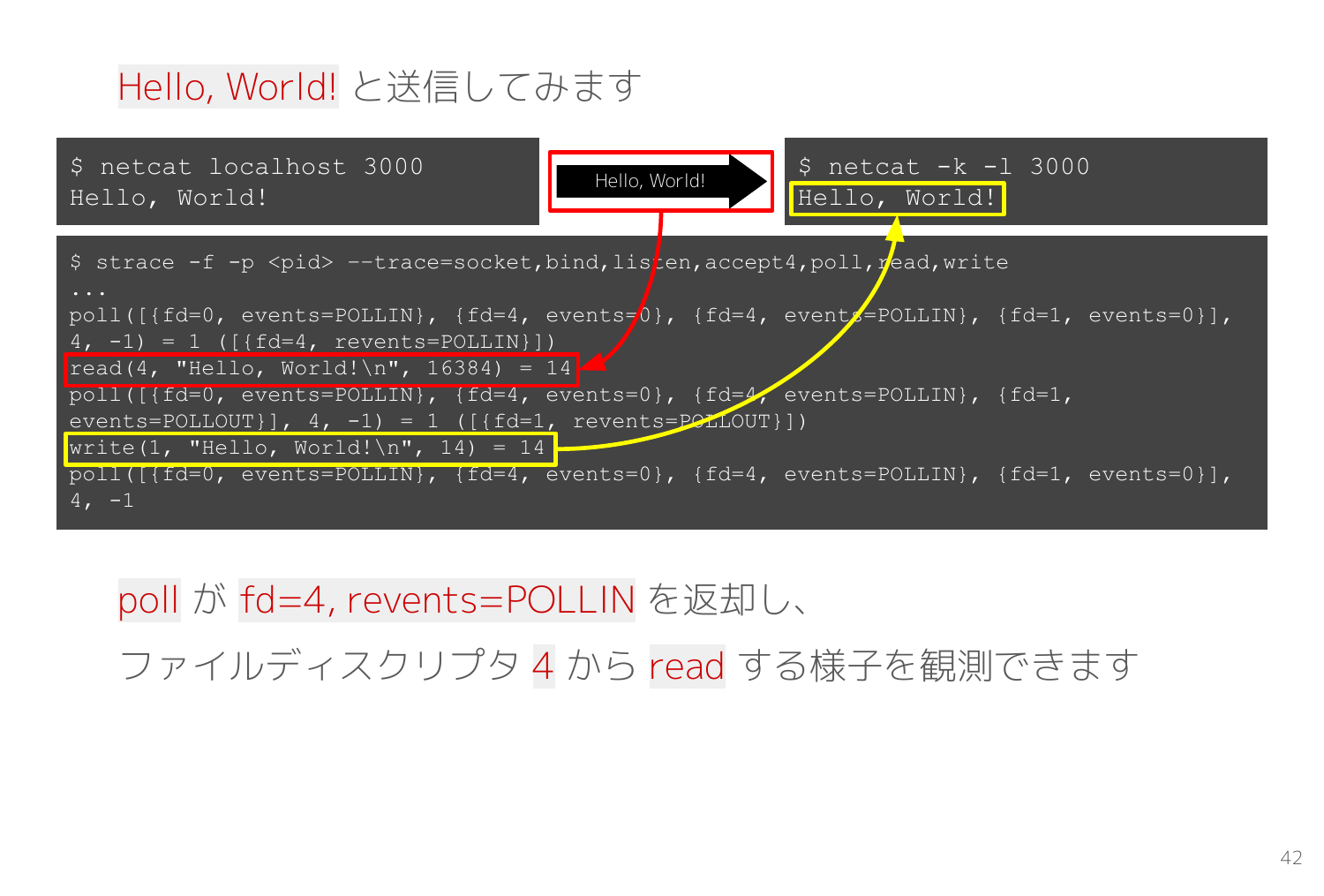
TCP通信は接続までが少し特殊なだけで、実際の送受信はファイルディスクリプタに対して read/write システムコールを実行するだけだと分かります。
Linuxカーネルとコンテナ
前半のスライドで Linuxカーネルは Webシステムにおけるバックエンドに類似しているという話をしました。
バックエンドは共通でも、フロントエンドを入れ替えることで、Webシステムやスマホアプリなど様々な異なる表現ができます。
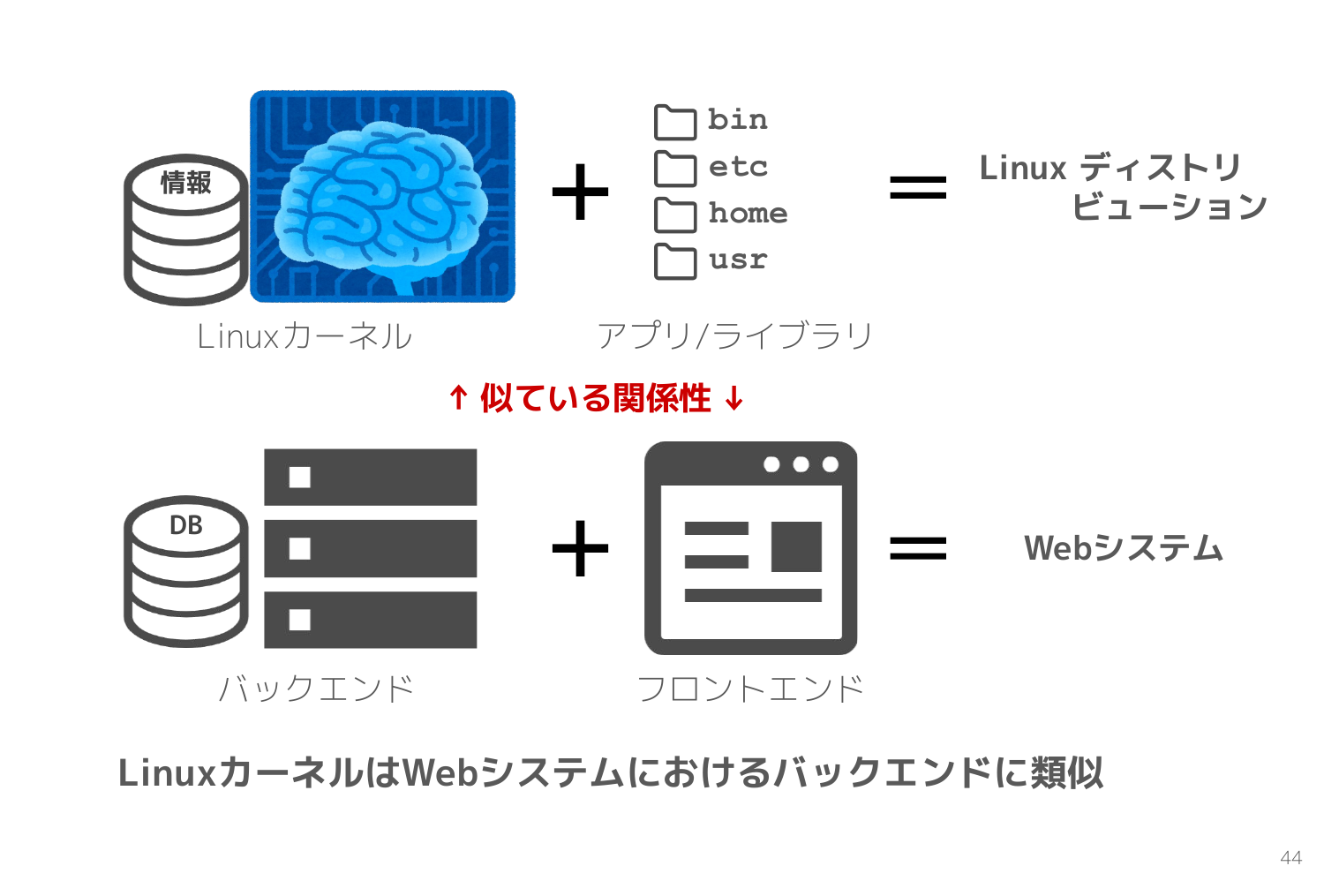
この考え方を利用したのがコンテナ技術です。
Linuxカーネルを共有しつつフィルシステム(=アプリ/ライブラリ)だけ切り替えれば仮想的に複数の Linux環境を作れそう、という発想です。
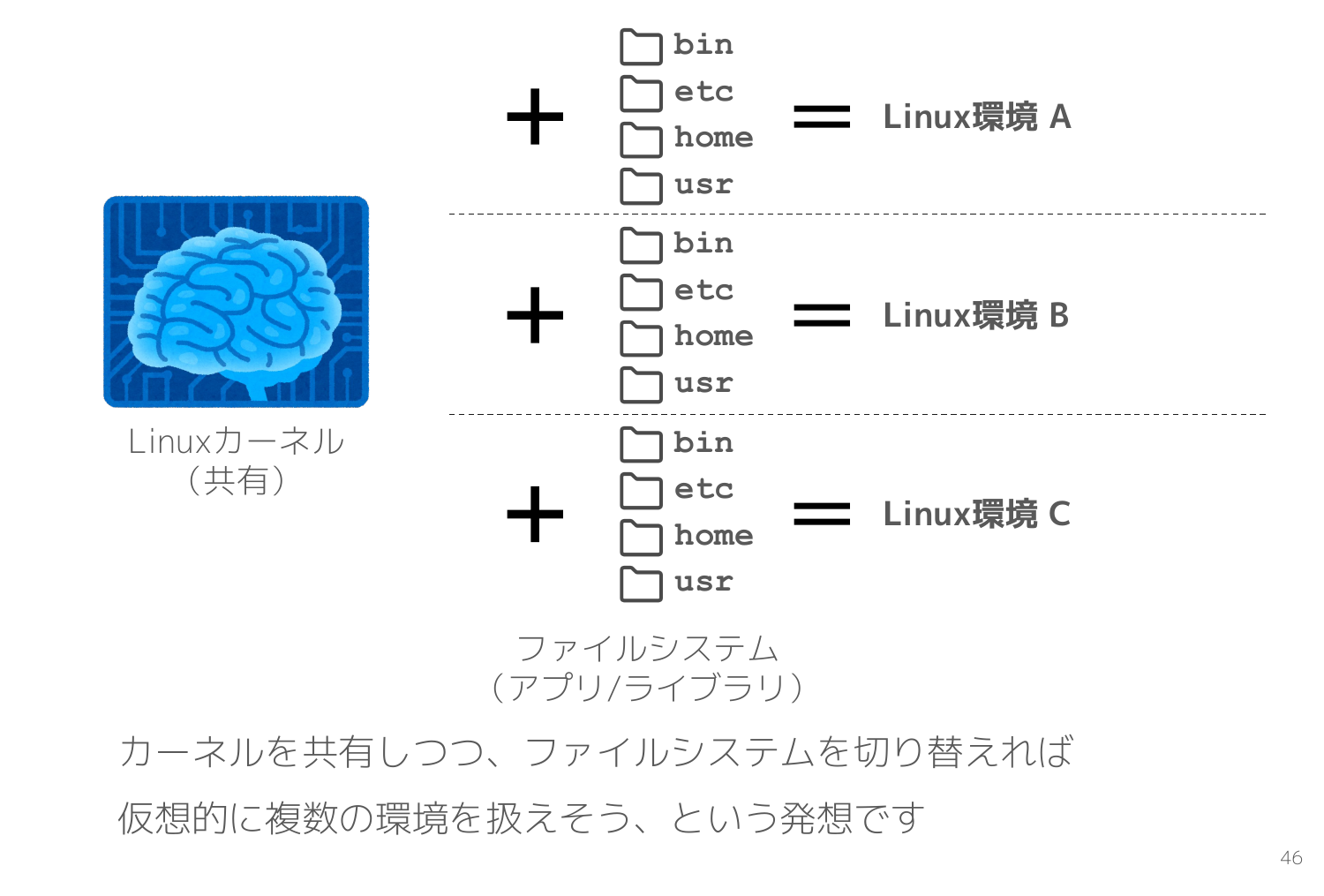
そこで Linuxカーネルは namespace という プロセスを隔離空間で実行する機能 を用意しています。様々な隔離機能が用意されていて、例えば Mount namespace は特定のプロセスにだけ異なるファイルシステムを見せることができます。それらの namespace 機能を Docker などのコンテナ管理ツールが利用しています。
一部の方には リッチな chroot と言えば伝わりやすいでしょうか。

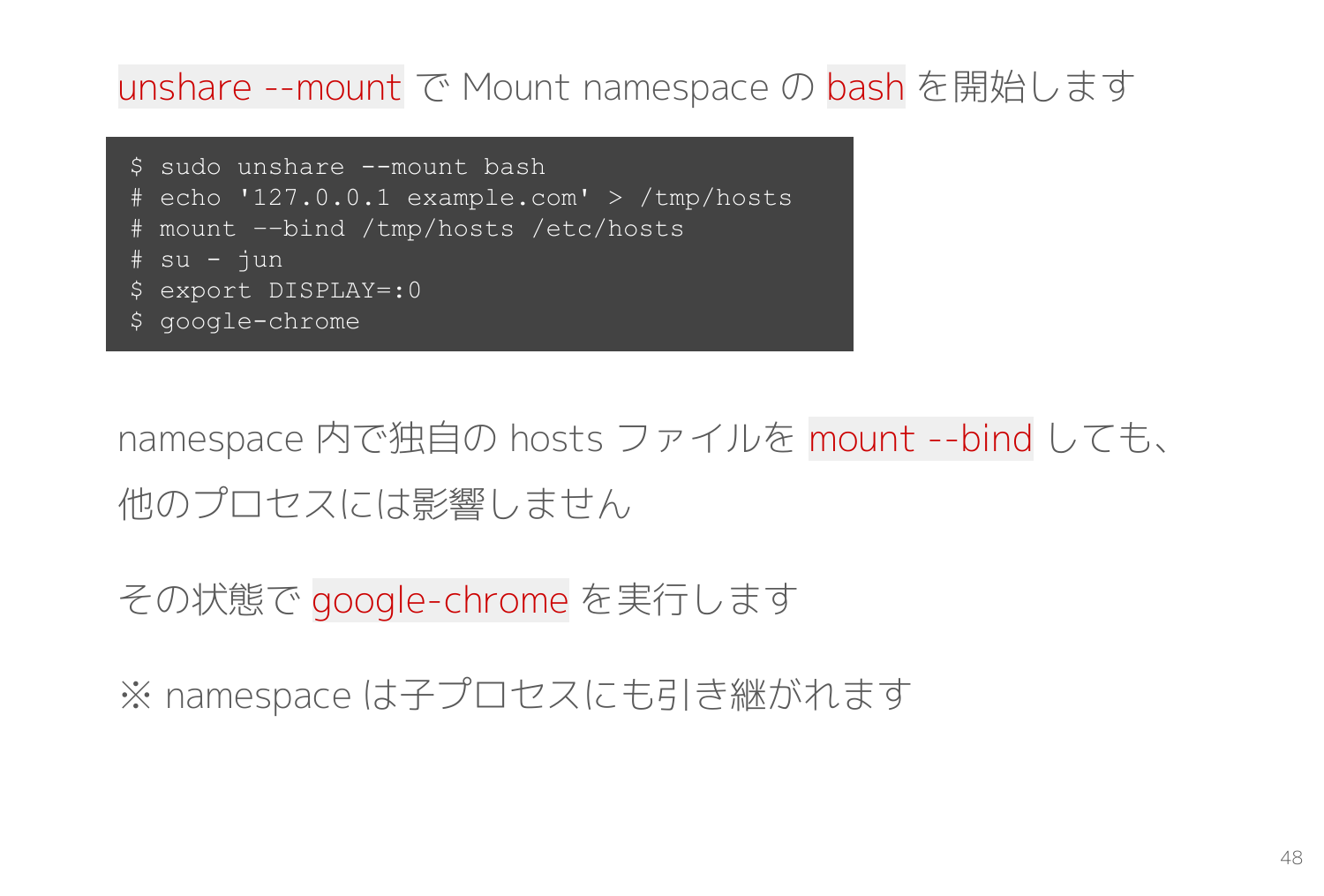
namespace 機能で隔離空間を作り出す unshare コマンドを利用して、実際に Mount namespace を動かしてみます。
$ sudo unshare --mount bash
# echo '127.0.0.1 example.com' > /tmp/hosts
# mount ––bind /tmp/hosts /etc/hosts
# su - jun
$ export DISPLAY=:0
$ google-chrome
unshare --mount bash で Mount namespace 内で bash プロセスを開始します。ここで起動する bash プロセスはマウントが隔離されているため、何をマウントしても自分とその子供以外のプロセスには影響しません。
次に 127.0.0.1 example.com というファイルを作って、それを /etc/hosts にバインドマウントします。
あとは su で非rootユーザーに戻ってから google-chrome を起動するだけです。
Mount namespace 内で起動した Chrome から接続する先となる Webサーバを用意するため、別のターミナルで適当な index.html を作成して nginx を起動します。
docker run --rm -p 3000:80 -v $(pwd):/usr/share/nginx/html nginx:latest を実行すると、カレントディレクトリをドキュメントルートとする nginx が3000番ポートで起動します。
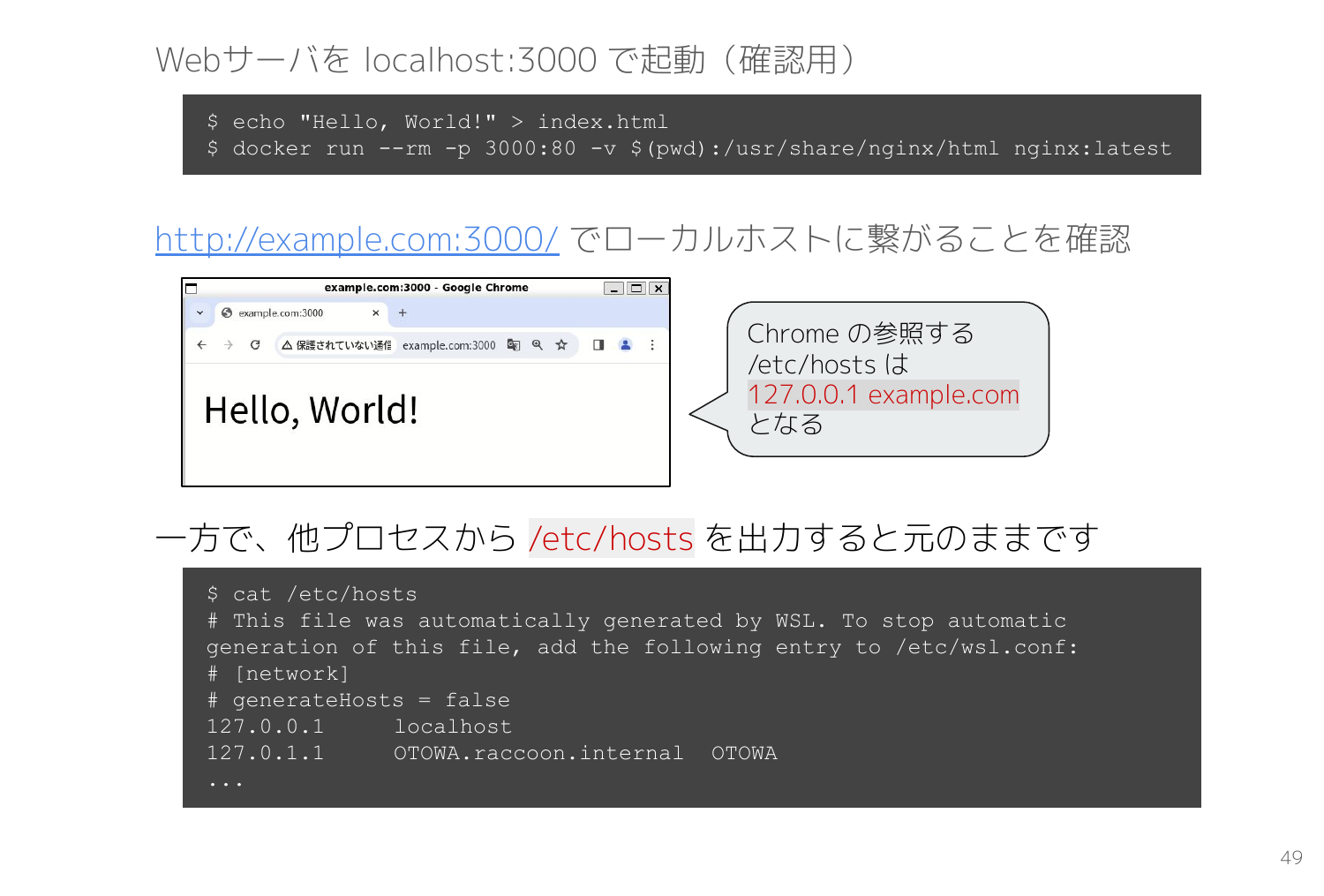
起動している Chrome で http://example.com:3000/ を開くと、ホストを example.com としているにもかかわらず localhost に繋がりました。
一応ほかのターミナルから /etc/hosts を確認しても example.com に関するレコードは見つからないので、想定通り google-chrome プロセスを Mount namespace 内で起動することができているようです。
Webサーバはなんでも良いので、netcat -k -l 3000 を利用しても面白いです。人力で HTTPリクエストを送信するデモはよく見かけますが、 人力で Webサーバ側を担当するデモ は見たことがありません。
netcat -k -l 3000 を起動してから Chrome で http://example.com:3000/ にアクセスすると HTTPリクエストが netcat のターミナルに表示されるので、以下のような応答を返してあげましょう。入力が終わったら Ctrl-C で netcat を終了すれば Chrome は切断を検出してレンダリングを開始してくれます。
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Hello, I'm Human!
Chrome の画面に Hello, I'm Human! と表示されたはずです。事前に DevTools のネットワークタブを開いておけば、自分で手入力した内容が HTTPレスポンスとして表示されるのでより立体的に理解できます。
コンテナとは namespace 機能で作られた隔離空間内で起動したプロセスというだけなので、そのプロセスを終了すればコンテナと呼ばれていたものは消えてなくなります。これがコンテナの正体であり、コンテナはただのプロセスと言われる背景です。
そして Docker はカーネルの持つ namespace 機能をうまく管理してくれるフロントエンドみたいな役割をするツールだと分かります。
コンテナの仕組みを深掘り
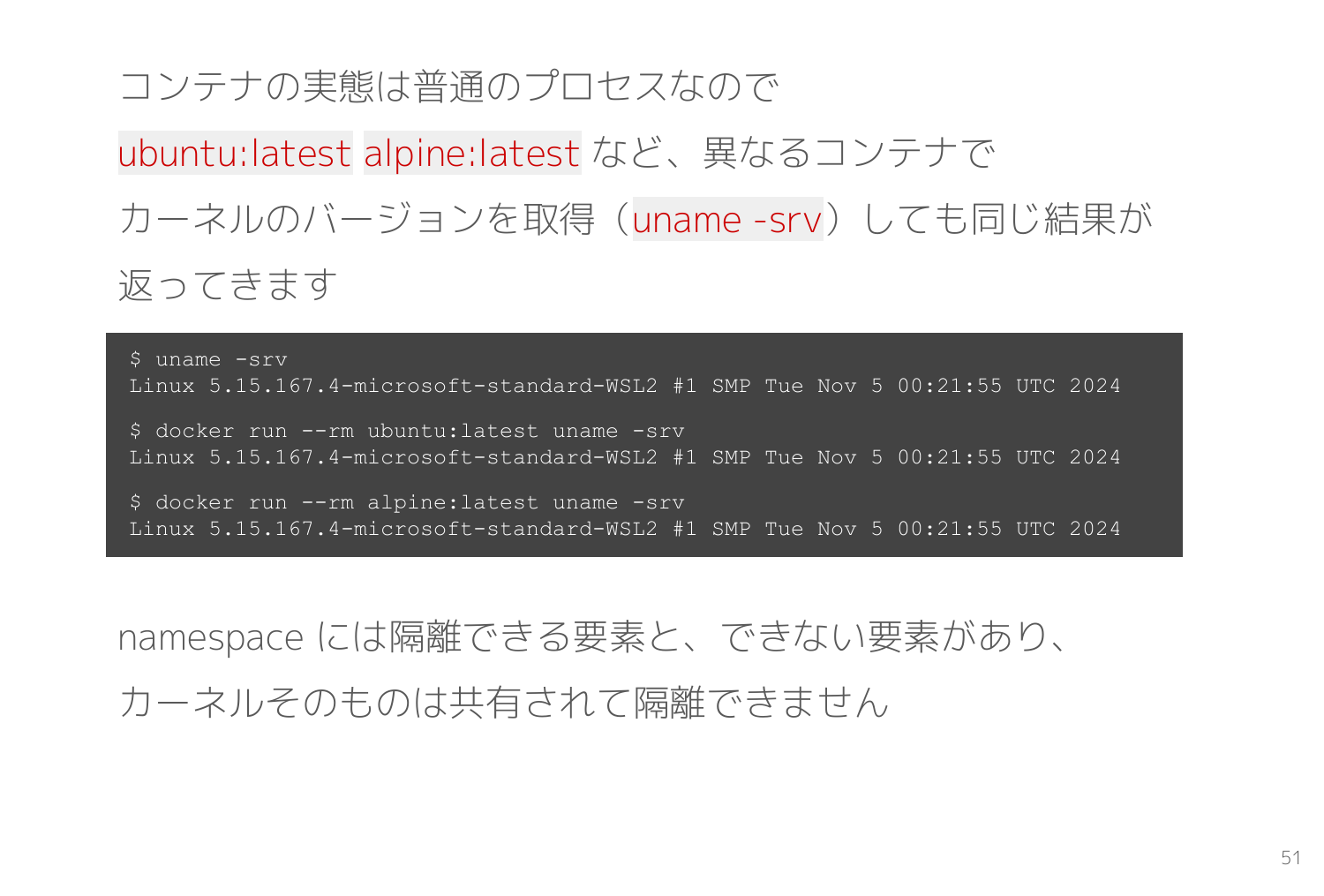
コンテナは普通のプロセスでありカーネルが共有されることを確認するために Docker Hub にある ubuntu:latest alpine:latest などのイメージでそれぞれ uname -srv を実行した結果を示します。
以下のスライドの通り、いずれの環境でも同一の応答が返ってきていて、カーネルを共有していることが分かります。
つまりコンテナイメージとして配布されている様々なディストリビューションは厳密に本物と同一とは言えません。アプリ・ライブラリの構成はさておき、カーネルにはバージョンや設定の差異があります。
ちなみにスライドは WSL2 環境のため、Linuxカーネルにパッチを当てた WSL2 専用カーネルが利用されています。
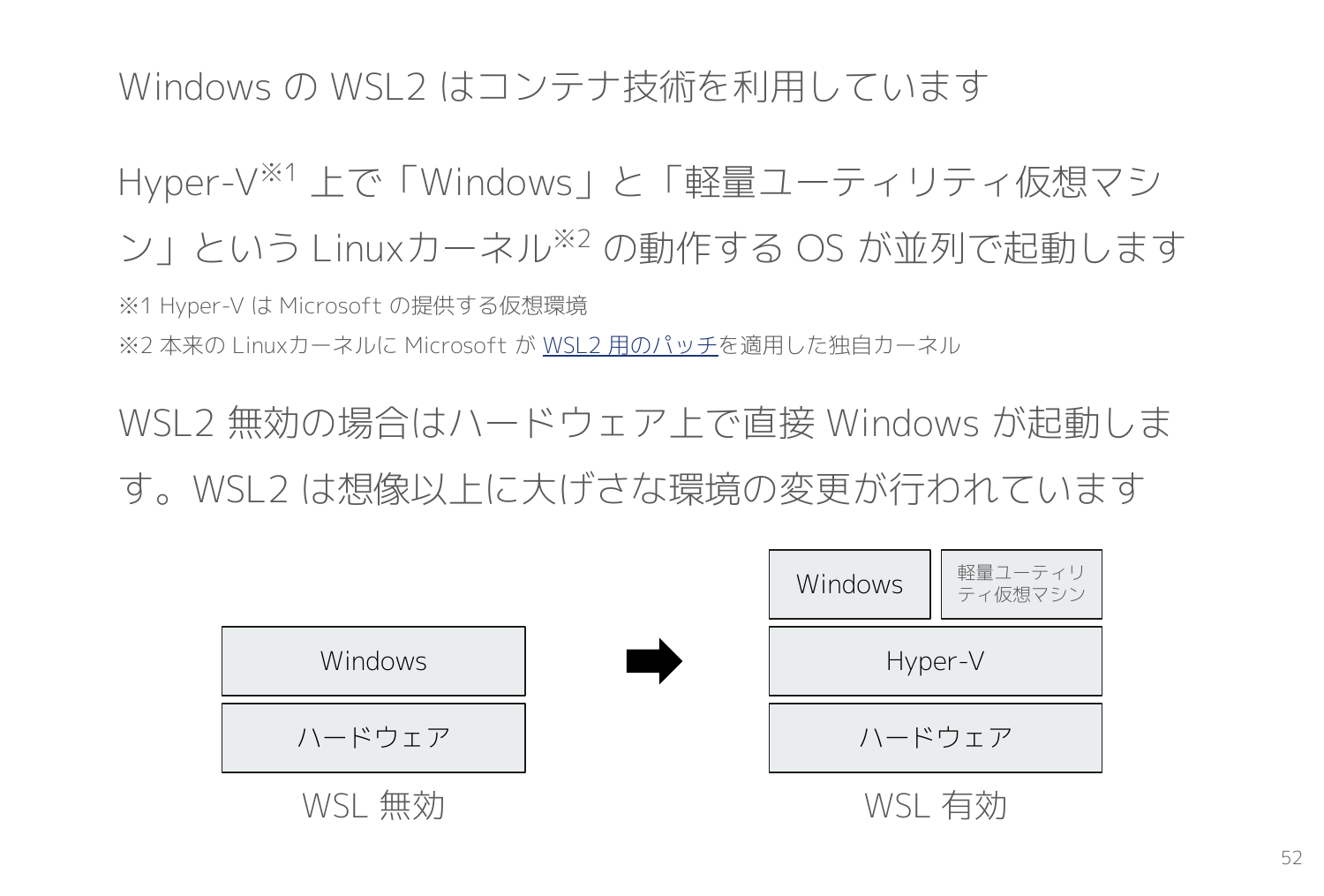
Windows の WSL2 はコンテナ技術が利用されています。
WSL2 が有効化されると Hyper-V というハイパーバイザー上で Windows に加えて、軽量ユーティリティ仮想マシンという Linuxカーネルの動作する OS が並列で動きます。WSL2 環境はその中でコンテナとして動作します。
WSL2 に複数のディストリビューションをインストールして、それぞれの環境で uname -srv を実行すると同一の結果が返ってきます。これは先ほどの軽量ユーティリティ仮想マシンで動作しているカーネルです。

最後に
システム開発にはエラーやトラブルがつきものです。そういった場合に役立つのが低レイヤであり、カーネルの動作原理を知るとトラブルシューティング時の解像度が格段に上昇します。
しかし低レイヤは駆け出しエンジニアの時期に学んでも挫折するだけでつらいですよね。そこでほどよい時期に学べる n年次研修という仕組みは理にかなっている仕組みです。
最初は無理せず、そして「分かるぞ!!」と思えたタイミングが低レイヤを始めるちょうど良いタイミングです。一度読んで分からなかったら、また来年にでもリトライしてみましょう。
ところで「Linux && Docker研修」は論理演算子から命名しています。Linux 知識が false だと、論理積の評価は終了して Docker 知識にたどり着けません。Linux 知識 == true が前提条件で Docker を知る、この2項目の関係性を表しています。研修の題名にもそういった想いを込めていました。
さて、ラクーンホールディングスではエンジニア・デザイナー・HTMLコーダーを大募集中です!
興味を持っていただいた方は是非、お話ししましょう!低レイヤの底から皆さんを歓迎します。






