

MySQLでプライマリキーをUUIDにする前に知っておいて欲しいこと
こんにちは、羽山です。
今回は MySQL のプライマリキーに UUID を採用する場合に起きるパフォーマンスの問題を仕組みから解説します。
MySQL(InnoDB) & UUID のパフォーマンスについては各所でさんざん議論・検証されていますが、論理的に解説した記事が少なかったり一部には誤解を招くようなものもあるため、しっかりと理由から理解するための情報として役立つことができればと思っています。
UUID と比較される古き良き昇順/降順のプライマリキーはというと、 MySQL の InnoDB において良いパフォーマンスを出すために縁の下の力持ちのような働きをしてくれているケースが実は少なくありません。
しかし、なぜ昇順だと有利なケースがあるのか?という理論が分かっていないと、「このシーンにおいてどのプライマリキーを選ぶのが正解か?」という問いに答えることはできません。
UUID の採用には数々のメリットがあります。個別ノードが自律的にキーを発行できるため、冪等性(べきとうせい)を担保する作りにしやすかったり、シャーディングで水平分割をする場合にキーを事前に決定できればロジックが簡潔になったり、キーに対する意味づけを自然に排除できることもメリットです。利用者が次のキーを予測しにくい特性も自然とセキュリティを上昇してくれるなど、主に設計面で有利な点が数多くあります。
しかし一方で UUID にはパフォーマンス面でいくつか弱点があります。
そこで本稿では UUID を利用する上での注意点や落とし穴を昇順/降順との比較で解説して、そしてその回避方法も後半で紹介します。
UUID は昇順/降順のプライマリキーの上位互換ではないのでメリットデメリットがあります。盲目的に採用するのではなく弱点も理解した上で適切に利用するのが望ましいと言えます。
例えば UUID を採用したテーブルのパフォーマンスが悪いからリードレプリカを導入したけど、こんどはリードレプリカのパフォーマンスが劣化してきたからもう一台追加導入することになった。みたいな状況がなぜ発生するのか。本稿を読めばそれを論理的に理解できるようになるはずです。
今回取り扱う UUID は主にバージョン1を想定していますが、バージョン4などでも同様か、もしくはさらに顕著な問題が発生します。
InnoDB のテーブルはクラスタインデックス構造
InnoDB のテーブルは主キーによるインデックスのツリー構造(B+Tree)で、リーフページにテーブルの値を持つクラスタインデックス構造です。
クラスタインデックス構造
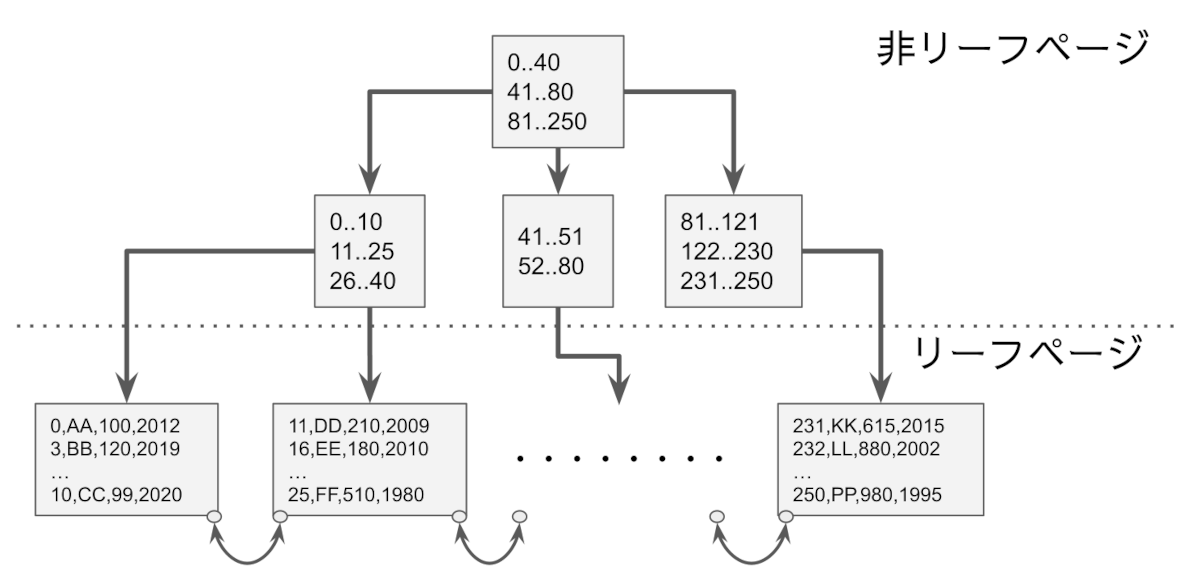
- プライマリキーのツリー構造でデータはリーフページに保持される
- ページサイズのデフォルトは16KB(※innodb_page_sizeで変更可能)
- 将来の更新に備えて1/16を残し、15/16を利用する
構造的にプライマリキーの昇順もしくは降順に INSERT する場合の効率が最も高くリーフページが両端に順次追加されていきます。途中にデータが挿入されない場合の各リーフページの使用状況は常に15/16となります。
次はプライマリキーがランダム値の場合はどうなるかというと少し話は複雑になります。
上図の通りインデックスはデータがソートされた状態になっています。その構造にランダム値を登録するためには、すでにあるレコードの間にデータを挿入する必要があります。
レコードを登録したいリーフページに空きがあればそのまま保存することができますが、空きがなければ1つのリーフページを分割して2つに分けることになります。
リーフページの分割
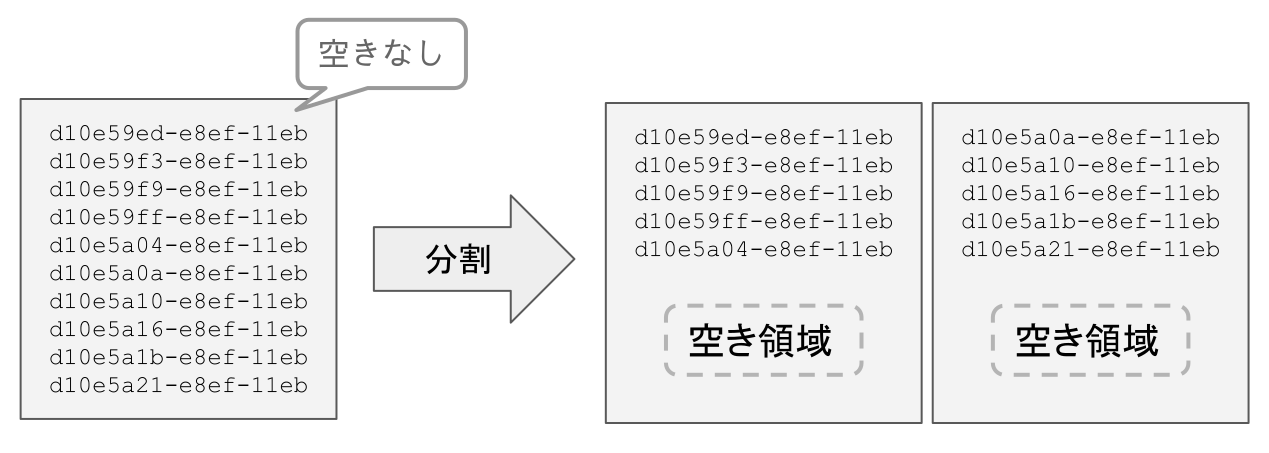
例えば1つのリーフページに10レコードが入るとして新たなレコードをINSERTするとおおよそ以下のような動きをします。
- リーフページ内のレコード数
- 10レコード → 2へ
- 10未満 → 3へ
- リーフページを5レコードずつの2つのリーフページに分割
- リーフページにレコードを登録する
- → 1に戻る
結果として各リーフページには5~10レコードがまばらに保存されている状態になり、およそ5回の INSERT につき1回程度の割合でリーフページの分割が発生します。
昇順/降順のプライマリキーではリーフページの分割が発生しないため1つのリーフページに10レコード保持できるのに比べて、ランダム値の場合は平均7.5レコードとなって格納効率は25%落ちます。
UUID のプライマリキーで INSERT が遅くなる理由
InnoDB でランダム値をプライマリキーとした場合の INSERT のパフォーマンスについては様々な検証記事があります。
シーケンシャルなプライマリキーとの比較では、概ねどの結果でもレコード数が少ない間は同等のパフォーマンスですがレコードが増えるとランダム値のパフォーマンスが劣化して最終的には10~20倍以上の差となることが多いようです。
(※参考 MySQL InnoDB Primary Key Choice: GUID/UUID vs Integer Insert Performance)
その一方で UUID を利用すれば複数セッションからの更新が1つのリーフページに集中することなく分散できるのでラッチ競合が起きずにパフォーマンスが良いという趣旨の記事も稀に見かけます。
その主張自体はロックの側面だけを考えると誤りではないものの現実の検証結果とは明らかに異なっています。
ランダム値のパフォーマンスが劣化する原因としてすぐに思い付く理由は前述の定期的なページ分割とそれに伴う格納効率の悪さですが、これは残念ながら問題の本質ではありません。
ページ分割の発生頻度はページサイズと1レコードのサイズに依存していて、たしかにパフォーマンス悪化の要因にはなるものの、たいていの環境では10%も差はないでしょう。
格納効率についてもストレージとバッファプールを余分に消費する要因にはなりますが、それがパフォーマンスに直接大きな影響をおよぼすかというとそうでもありません。
さらにリーフページの分割と格納効率はどちらもレコード数の増加で徐々に性能劣化することはなく、常に一定のマイナス効果です。
ストレージへの格納効率は直接パフォーマンスへ影響しませんが、結果としてバッファプールを無駄に消費するため間接的にはI/Oの増加などでパフォーマンス劣化を導きます。
では徐々に性能劣化する10~20倍にも及ぶ差はなにが原因かというと、大規模テーブル(クラスタインデックス)からランダムなリーフページを読み込むストレージのI/Oです。
前述の通り InnoDB のテーブルはクラスタインデックス構造なので、プライマリキーが近接しているデータが物理的にも隣同士になります。そこに昇順で INSERT する場合は常に右端のリーフページが読み込まれていれば良いのでその読み込み負荷は考慮が必要のないレベルです。
一方でランダムな UUIDを INSERT するためにはその UUID が入るべき場所のリーフページをまずは読み込む必要があります。これは1レコード INSERT のたびにテーブル全体のランダム位置に対する読み込みが必要ということで、そのリーフページがバッファプールでヒットすればいいのですが、もしヒットしなければストレージに対するI/Oが発生します。
クラスタインデックス全体へのI/Oが常時発生する
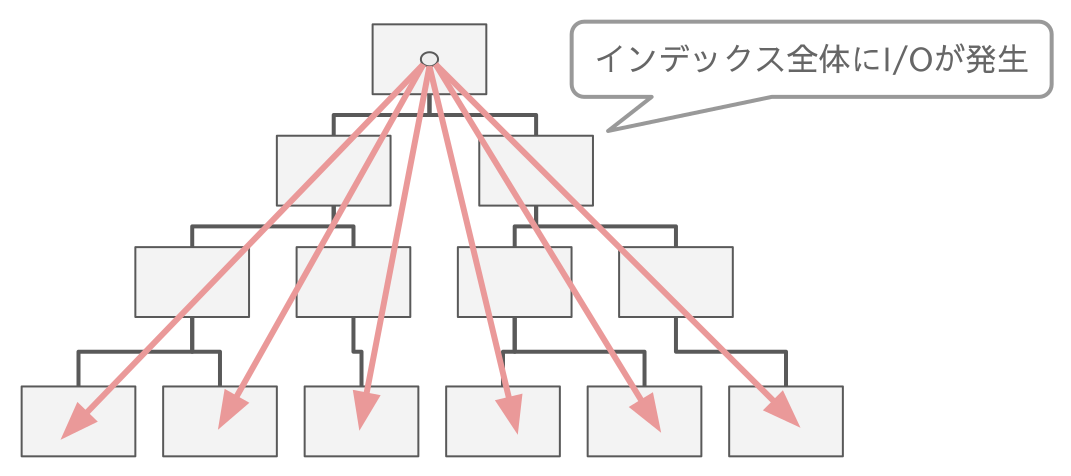
つまりパフォーマンス劣化の原因は INSERT するレコードが入るべきリーフページがどれくらいの確率でバッファプールにキャッシュされているかにあります。挿入位置がランダムである以上、適切なキャッシュ戦略がないので純粋にテーブル全体に対するキャッシュ率の勝負になります。この点が常に追加する位置が固定されている昇順/降順のインデックスとの違いです。
様々ある検証記事では多種多様なバッファプールサイズやストレージ速度、テーブルのレコードサイズとなっていますが、結局パフォーマンスに大きく影響しているのはテーブルのサイズがバッファプールのサイズを超えていて、どれくらいのキャッシュヒット率になっているかという点だけなのです。
例えばなにかの検証結果を信じて100万レコードまでなら大丈夫だろうと思っても、カラム数が多いなどで1レコードのサイズが大きいテーブルならもっと早期に性能劣化しますし、本番環境で他のテーブルがバッファプールを消費したらその分使えるバッファプールの割り当ては少なくなるので性能劣化は早くなります。
このように UUID を利用した大規模テーブルを運用しようと思ったら、構造的に必ず性能劣化するので対処するには札束で戦わざるをえない状況になります。
シーケンシャルなプライマリキーが速い理由
次は昇順のプライマリキーを考えると以下の図のように読み込むリーフページを一部に集中させることができます。
テーブル全体としてはほとんどバッファプールにキャッシュされていない状況でも、昇順のプライマリキーならば INSERT するリーフページが高い確率でキャッシュにヒットします。
読み込みが必要なのは局所的
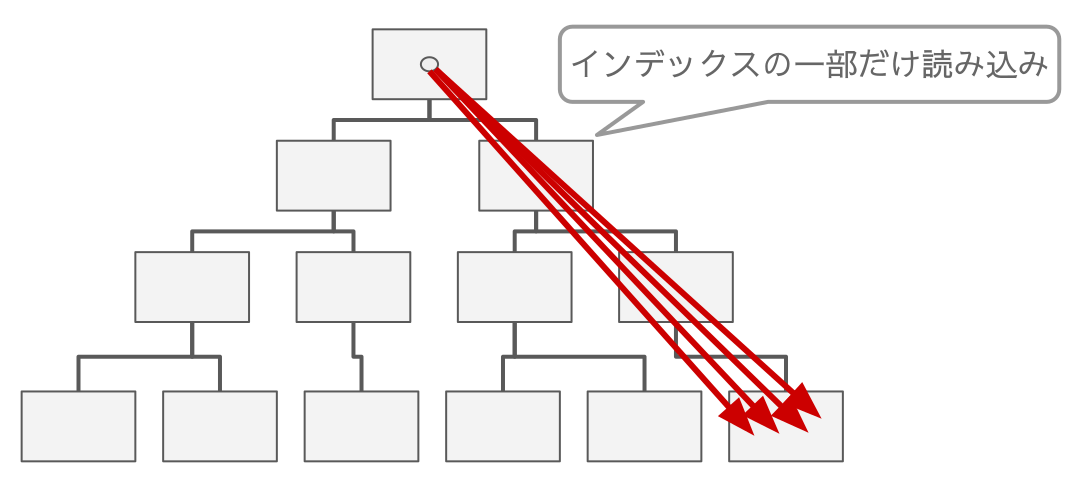
クラスタインデックス構造全体のサイズに影響する要素がほとんどないので、レコードが増えても INSERT のパフォーマンスは常に一定を維持できます。
読み込みパフォーマンスの比較
UUID を利用したプライマリキー(以下、UUID PKと記載)と昇順のプライマリキー(以下、昇順PKと記載)で読み込みパフォーマンスの差をいろいろなケースで考えてみます。
前述の通りバッファプール上にクラスタインデックス全体がキャッシュされている状態だとどんなパターンでもパフォーマンスが出るので 20GB の巨大なテーブルでバッファプールには20%程度(≒4GB)キャッシュされている状況を想定します。
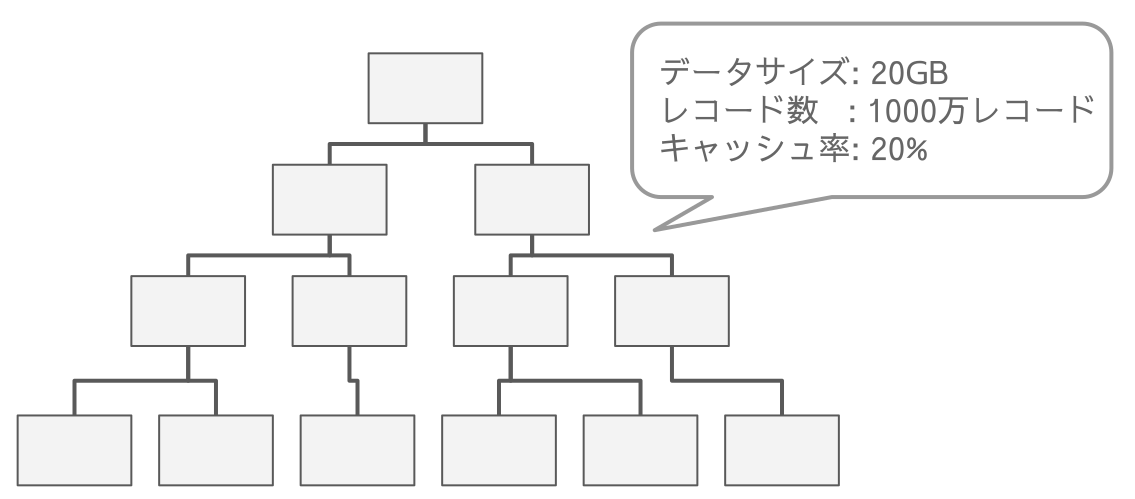
1レコードだけ取得
完全にランダムな1レコードを取得する場合、UUID PK と昇順PKでパフォーマンスに差はありません。
しかしこれを実世界のシステムに落とし込んでみると多くのケースで昇順PKの方がパフォーマンスは高くなります。
これはなぜかというと、多くのテーブルにおいてレコードの利用状況は生成時期と多少の相関があるからです。
例えばメモシステムの場合、新しいメモほど頻繁に使われて古いメモほど利用状況はまばらになります。
注文レコードの場合も新しい注文ほどより参照頻度が高く、古い注文はめったに参照されません。
昇順PKテーブルのデータ分布と利用頻度
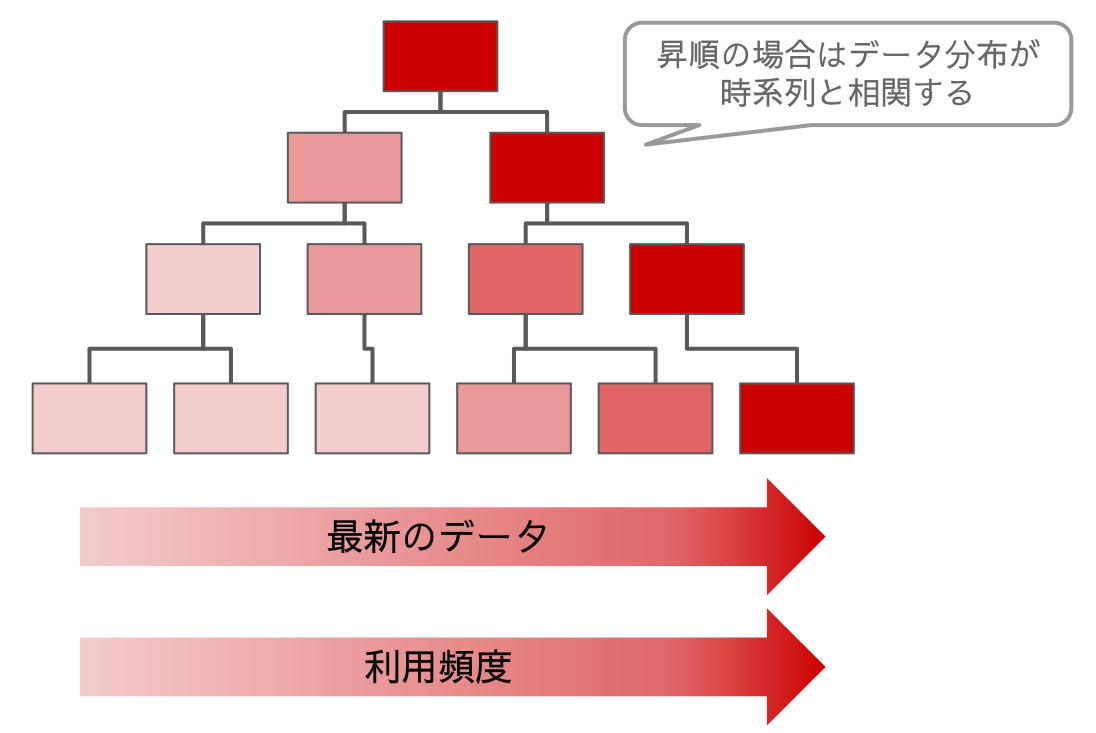
昇順PKの場合は左から右への時系列でレコードが格納されます。上図の通り新しいデータの参照頻度が高い傾向があるなら右側のリーフページほど参照頻度が高くキャッシュ率も高くなります。
その結果として全体のキャッシュ率は20%ですが、キャッシュヒット率はそれよりも高くなります。
UUID PKテーブルのデータ分布と利用頻度
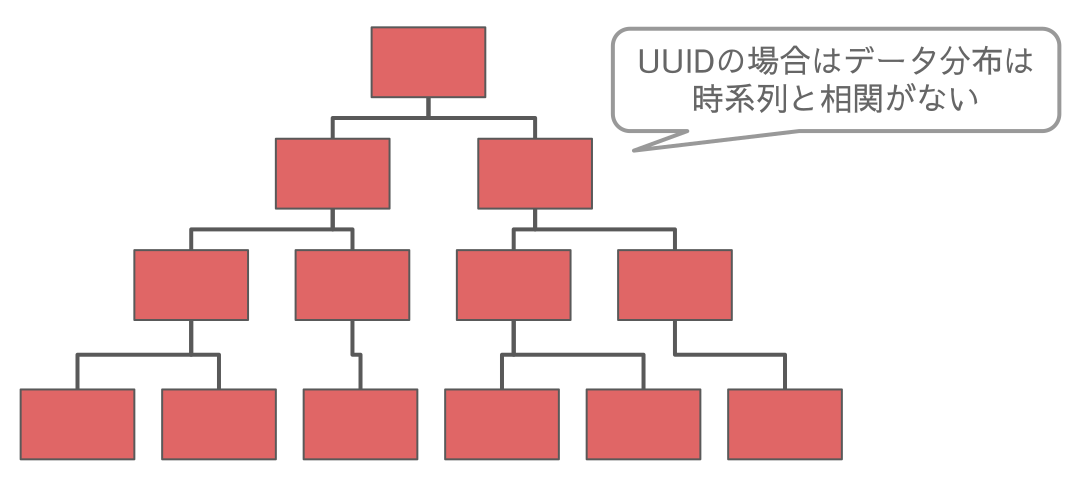
一方で UUID PK の場合はデータ分布と時系列の相関がなくなるのでキャッシュ率が20%ならばキャッシュヒット率も変わらず20%です。
昇順PKが知らず知らずのうちに受けていた時系列に関係するパフォーマンスの恩恵を UUID PK では受けることができません。
複数レコードをバルクで取得
バルクで取得するレコードに全く関連性がないならば、UUID PK と昇順PKでパフォーマンス差はありません。
しかしバルクで取得するケースも取得するレコードが生成時期と少なからず相関があるケースが比較的多いと言えます。
例えば以下のケースを考えてみます。
- 20年間運用している20GBの注文テーブル、2000万レコードある
- 年間の注文数は変化なくほぼ均等
- 最近1年間分の100万レコードを取得する
- バッファプールには全体の20%がキャッシュされている
- 最近1年分のレコードは頻繁にアクセスされているのでキャッシュされやすい状況
- 1つのリーフページにはおおよそ100レコードほど登録されている
昇順PKのテーブルから過去1年間のレコードを取得
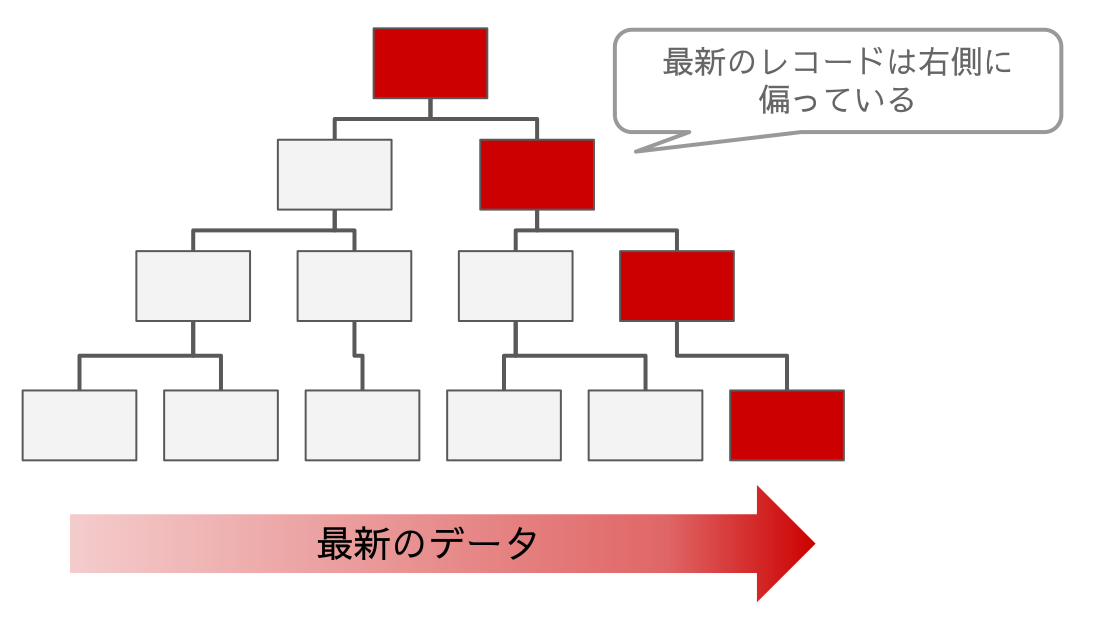
昇順PKの場合は注文日時とプライマリキーに相関があるので最近1年間のレコードはクラスタインデックス構造の右側に集中しています。
1つのリーフページに約100レコード登録されているという条件ですが、昇順PKの場合はリーフページ内のレコードは時系列順に並ぶためそのほぼ全てが取得対象のレコードである可能性が高くなります。つまり1つのリーフページを取得したら100レコードを取得できます。
さらに全体の20%がキャッシュされていて最近1年間分のレコードは頻繁にアクセスされているという条件なので、キャッシュヒット率はほぼ100%に近いと期待できます。
結果としてストレージへのI/Oはほぼゼロで処理が可能です。
UUID PKのテーブルから過去1年間のレコードを取得
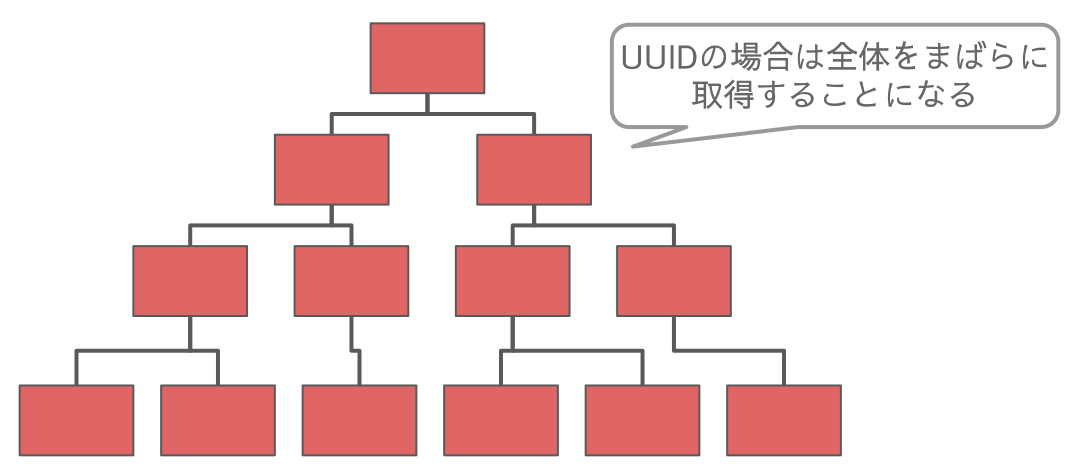
次に UUID PK の場合は1年間のレコードがクラスタインデックス全体に散らばるので、キャッシュヒット率の期待値はキャッシュ率と同じく20%となります。
さらにリーフページ単位で考えると、1つのリーフページには20年分のランダムな時系列のレコードが散らばっているので、1つのリーフページに含まれる最近1年のレコード数の期待値は 100レコード ÷ 20年 = 5レコード となります。
仮にレコードが完全なるランダムで均等に分布しているとすると 20GB すべてのリーフページを読み込んで各リーフページから5レコードずつ拾うことになります。20GB のうち 20% がキャッシュヒットするので、 20GB × 80% = 16GB の読み込みが発生します。
ただしこれはワーストケースで、UUID といえどもバージョン1ならば短期間で生成したレコード同士にはわずかな偏りあるので実際の読み込みはもう少し減ることを期待できますが、それでも良くて3割減ほどだと思われます。結果として 16GB × 70% = 11.2GB くらいの読み込みは少なくとも覚悟する必要があります。
率直にDBチューニングとしてはこの状態は悪夢と言えます。
冒頭で UUID を採用したテーブルのパフォーマンス改善に対してリードレプリカは効果的でないという例を出しました。構造自体の問題なのでリードレプリカを利用しても効率の悪いアクセスパスのままでバッファプールのサイズとストレージの速度分の貢献しかできないことが分かります。もちろん性能分の効果はあるものの根本的な解決にはならず、すでに肥大化しているテーブルに対しては焼け石に水となりかねません。本稿では詳しく解説しませんが、UUID に対して相性が良いのは水平分割のようにデータ自体を分離する手法です。
UUID の構造
次は UUID バージョン1の構造を簡単におさらいしてみます。
TTTTTTTT-TTTT-1TTT-sSSS-AAAAAAAAAAAA という構造で、前半が時刻で後半がMACアドレスを元に生成されています。
今回パフォーマンスに問題を引き起こす原因になっているのは前半の時刻を元に生成される 60bit にあります。
時刻を元に生成するならば時系列順になっているように思えますが実際はそうなっていません。というのも生成した時刻の整数を元に下位ビットを UUID の前半に、上位ビットを後半に配置する仕様のため、ごく短時間の時間経過でも UUID として生成されるほとんど全範囲に分布してしまいます。
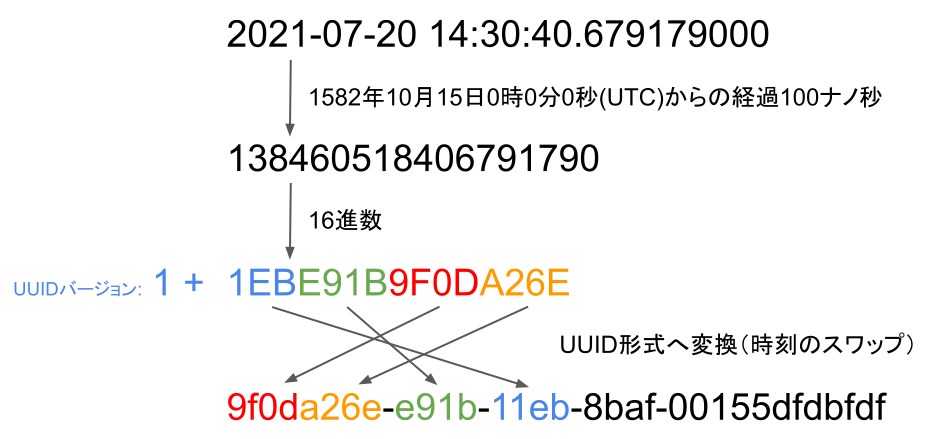
具体的な生成ルールはというと 1582/10/15 00:00:00 UTC からの経過時間を100ナノ秒単位で取得し、それを16進数表現にした上で 12bit, 16bit, 32bit に分割して前後を入れ替えます。
UUIDバージョン1の生成ルール
図だけでは分かりづらいので bash 環境で実際に生成してみます。(※コマンド実行中に時間が経過しているため生成する時刻やUUIDには差があります)
まずは以下を実行して1970年1月1日0時0分0秒(UTC)から現在(UTC)までの100ナノ秒単位の経過時間を取得します。
$ echo $(( $(date +%s%N) / 100 ))
16267587183434267
次に1582年10月15日0時0分0秒(UTC)から1970年1月1日0時0分0秒(UTC)の100ナノ秒単位の経過時間を以下のコマンドで得ます。
$ echo $(( $(date -d'1582-10-15T00:00:00+00:00' +%s) * -10000000 ))
122192928000000000
両者を足し合わせた結果が1582年10月15日0時0分0秒(UTC)から現在(UTC)までの100ナノ秒単位の経過時間となります。
それを16進数表現に変換すると以下のような60bit(=16進数表現で15桁)を得られます。
$ printf '%x\n' $(( $(date +%s%N) / 100 + $(date -d'1582-10-15T00:00:00+00:00' +%s) * -10000000 ))
1ebe91af1251613
次が重要ですが、UUID バージョン1ではこの 60bit(=15桁)を先頭から 12bit(=3桁), 16bit(=4桁), 32bit(=8桁) に分割して前後を入れ替えます。
この入れ替え作業によって経過時間の下位ビットが上位に配置されます。また 12bit で切り出した3桁には UUID のバージョンである 1 を先頭に追加して4桁にします。
これをコマンドで実行すると以下のようになります。
$ timestamp=$(printf '%x' $(( $(date +%s%N) / 100 + $(date -d'1582-10-15T00:00:00+00:00' +%s) * -10000000 )))
$ echo $timestamp
1ebe91afece851c
$ echo ${timestamp:7}-${timestamp:3:4}-1${timestamp:0:3}
fece851c-e91a-11eb
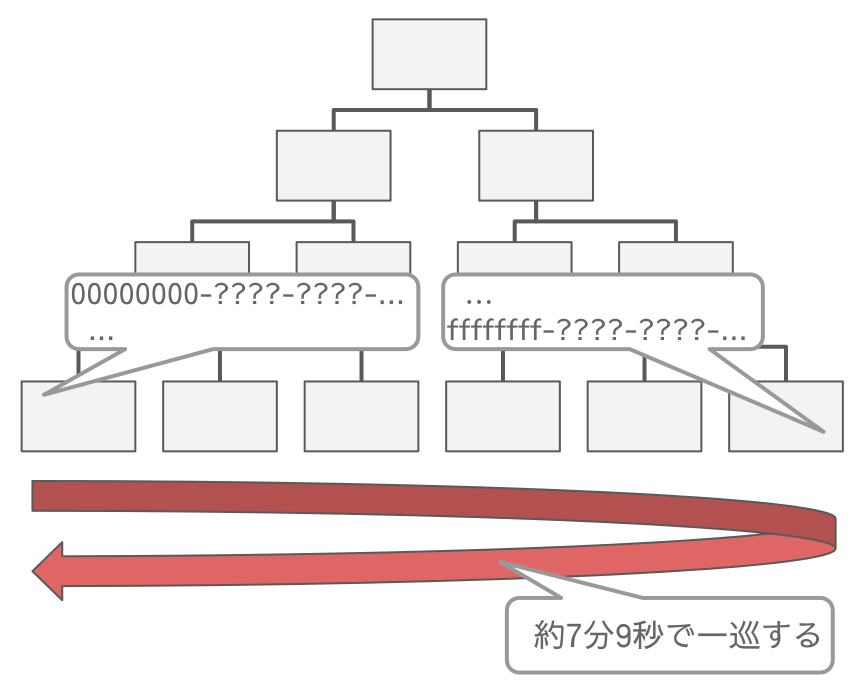
UUID の先頭8桁が一巡する時間
UUID バージョン1において先頭の 32bit は経過時間の下位ビットから生成されることが分かりましたが、ではその下位 32bit はどれくらいの時間経過で一巡するのかを計算してみます。
16進数の 100000000 で一巡なので10進数に変換すると 4294967296 100ナノ秒で、≒ 429496729 マイクロ秒 ≒ 429496 ミリ秒 ≒ 429 秒 ≒ 7分9秒となります。
先頭の 32bit は 00000000 ~ ffffffff の範囲を約7分9秒の時間経過で一巡して、クラスタインデックス構造の全体に散らばります。
UUIDの先頭8桁は約7分9秒で一巡する
では次に手動で生成した UUID の時刻由来の値が uuidgen --time と比べて正しい結果となっているのかを確認します。
(
date
timestamp=$(printf '%x' $(( $(date +%s%N) / 100 + $(date -d'1582-10-15T00:00:00+00:00' +%s) * -10000000 )))
echo ${timestamp:7}-${timestamp:3:4}-1${timestamp:0:3}
uuidgen --time
)
Tue Jul 20 14:30:40 JST 2021
9f0cf9af-e91b-11eb
9f0da26e-e91b-11eb-8baf-00155dfdbfdf
結果は上記のようになりました。先頭の 32bit はコマンド実行の時間経過でわずかに変化していますが、期待通りの値を生成できていることを確認できました。
ちなみに後半のMACアドレスから生成する部分はDBのパフォーマンスと関係しないので解説は省略します。
UUID の仕組みを理解するとデータがクラスタインデックス構造のなかでどれほどバラバラに散らばることになるかイメージできたのではないでしょうか?このような基礎的な仕組みを理解しておくことはDB内の状況とパフォーマンスを予測・分析するために必要なことです。
例えば先頭の要素が、7秒、7分、7時間でそれぞれ一巡する UUID ライクなキーがあったとするとそれぞれどのようなパフォーマンス特性になるでしょう。
あるサイトの利用者が10商品注文した状況を考えてみます。システム的には注文テーブルに10レコード INSERT されます。
注文テーブルの利用シーンは1回の注文に紐づくレコードを同時に取得することが多いことも想像できます。
7秒で一巡する UUID ライクのキーの場合
- ごく短時間で生成したキーでもランダムで分布する、UUIDバージョン4に近い状態
- ランダム位置に分布しているため、10レコードをまとめて取得する為には10箇所のリーフページを読み込む必要がある
7分で一巡する UUID ライクのキーの場合
- ごく短時間で生成したキーは隣り合う可能性がある
- 10レコードのうちいくつかは同じリーフページ内に保持される可能性がある
- UUID 生成に間隔があいているとバラバラになりやすい
7時間で一巡する UUID ライクのキーの場合
- 短時間で生成したキーは隣り合う可能性が高い
- 1つのリーフページで10レコードまとまっていることを期待できる
さらに1つ問題です。上記と同じ10レコードを INSERT する場合、以下のどの方法がよりリーフページ内で隣り合った UUID を発行しやすいでしょうか?
insert into … values ( uuid(), ... );のようにDBサーバ側で UUID を発行して1レコードずつ INSERT するinsert into … values ( uuid(), ...), ( uuid(), ...), ... );のようにDBサーバ側で UUID を発行しながら10レコードまとめて INSERT する- アプリ側で10レコードまとめて UUID を発行してから INSERT する
これはすぐに答えが分かると思いますが、UUID の発行を短時間かつ連続で行うほうがより近い UUID を得ることができます。
この選択肢ではアプリ側の処理内容にもよりますが、2 と 3 が同率一位でしょうか。1 は INSERT 処理実行の往復分だけ発行タイミングがずれるため他の2つよりも離れた UUID になります。
UUID のパフォーマンス問題を解決する
次は UUID のパフォーマンス問題を解決する方法を2つ紹介します。
MySQL8 の uuid_to_bin でスワップ機能を利用する
MySQL8 には uuid_to_bin() という関数が用意されていて、UUID を16進数表現からバイナリに変換することで 32byte(ハイフン省略)から 16byte に変換して保持できます。
本稿では触れませんでしたが保持に 32byte 必要なのも地味にパフォーマンスへは悪影響がありましたが、まずはその点を解消できます。
uuid_to_bin() にはもう一つ重要な機能があって二つ目の引数に1を渡すと、UUID を生成する際に入れ替えた経過時間の上位ビットと下位ビットを再度入れ替えた上でバイナリ変換をしてくれます。
これによって UUID の経過時間の置き換えが打ち消されるので、経過時間がそのままのビット表現で保持されることになりほぼシーケンシャルとなります。
UUIDのスワップ
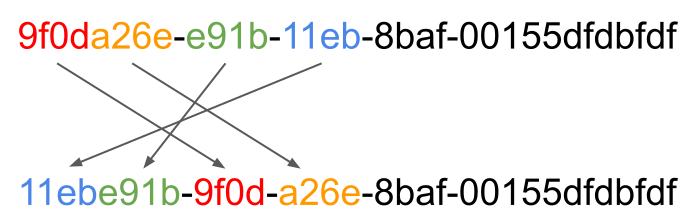
では実際にMySQL上で動かして動作を確認してみます。
mysql> set @uuid = '9f0da26e-e91b-11eb-8baf-00155dfdbfdf';
Query OK, 0 rows affected (0.00 sec)
mysql> select bin_to_uuid(uuid_to_bin(@uuid));
+--------------------------------------+
| bin_to_uuid(uuid_to_bin(@uuid)) |
+--------------------------------------+
| 9f0da26e-e91b-11eb-8baf-00155dfdbfdf |
+--------------------------------------+
1 row in set (0.00 sec)
mysql> select uuid_to_bin(@uuid, 1);
+----------------------------------------------+
| uuid_to_bin(@uuid, 1) |
+----------------------------------------------+
| 0x11EBE91B9F0DA26E8BAF00155DFDBFDF |
+----------------------------------------------+
1 row in set (0.00 sec)
mysql> select bin_to_uuid(uuid_to_bin(@uuid, 1), 1);
+---------------------------------------+
| bin_to_uuid(uuid_to_bin(@uuid, 1), 1) |
+---------------------------------------+
| 9f0da26e-e91b-11eb-8baf-00155dfdbfdf |
+---------------------------------------+
1 row in set (0.00 sec)
mysql> select bin_to_uuid(uuid_to_bin(@uuid, 1));
+--------------------------------------+
| bin_to_uuid(uuid_to_bin(@uuid, 1)) |
+--------------------------------------+
| 11ebe91b-9f0d-a26e-8baf-00155dfdbfdf |
+--------------------------------------+
1 row in set (0.00 sec)
bin_to_uuid(uuid_to_bin(@uuid)) でバイナリ値へ変換した後にそのまま文字列へ変換すると元の UUID に戻っています。
uuid_to_bin(@uuid, 1) はスワップしつつバイナリ値のまま取得した状態で、バイト列の配置が入れ替わっていることを確認できます。
bin_to_uuid(uuid_to_bin(@uuid, 1), 1) でスワップしつつ、さらにスワップして戻すと、この場合も元の UUID となります。これが想定される利用方法です。
最後に bin_to_uuid(uuid_to_bin(@uuid, 1)) でバイナリ値への変換時点でスワップさせて、その後スワップせずに戻すと入れ替わった結果になることを確認できます。
次は実際のテーブルに登録してみます。
mysql> create table t (id varbinary(16) primary key);
Query OK, 0 rows affected (0.03 sec)
mysql> set @uuid = '9f0da26e-e91b-11eb-8baf-00155dfdbfdf';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t (id) values (uuid_to_bin(@uuid, 1));
Query OK, 1 row affected (0.01 sec)
mysql> select id from t;
+------------------------------------+
| id |
+------------------------------------+
| 0x11EBE91B9F0DA26E8BAF00155DFDBFDF |
+------------------------------------+
1 row in set (0.00 sec)
mysql> select bin_to_uuid(id, 1) from t;
+--------------------------------------+
| bin_to_uuid(id, 1) |
+--------------------------------------+
| 9f0da26e-e91b-11eb-8baf-00155dfdbfdf |
+--------------------------------------+
1 row in set (0.00 sec)
uuid_to_bin() に 1 を渡してスワップした状態で UUID のバイナリ値を登録します。
次にそのまま SELECT するとHEX表現で表示されていますが、下位と上位が入れ替わっていることを確認できます。
続いて bin_to_uuid() を同じくスワップありとすると、元の UUID を取得できます。
発行方法によっては完全なシーケンシャルとはならないですが、uuid_to_bin のスワップ機能を利用すれば UUID のもつ問題の多くは十分解消します。
UUID の代わりに ULID を利用する
UUID の問題点を解消した採番方法はいろいろと提案されていますが、その中から ULID を紹介します。
ミリ秒単位の経過時間を元に生成されるので、完全なシーケンシャルとは言いがたいですが UUID のパフォーマンス課題を解決する手段としてはこれくらいで十分です。
ULID の Monotonicity 機能について
ULID には経過時間の後ろに配置されるランダム値を細工して同一ミリ秒内で再度発行された場合は生成するランダム値を1つインクリメントする仕様も用意されていますが、これは絵に描いた餅でしょう。
複数あるアプリケーションサーバのタイムスタンプはそもそも微妙に異なりますし、1つのアプリケーションサーバ上でもマルチプロセスモデルでサービスを起動している場合は1プロセス内で担保されるだけです。完全に担保するためには ULID 発行サーバを用意する必要がありますが、それでは SPoF が増えるだけだし、そもそもの UUID のもっていた利点を失っています。
まとめ
今回は改めて UUID および昇順/降順のプライマリキーを話題にしてみました。
実は UUID にまつわるパフォーマンス特性にはもう少し書きたかったことがありますが、それはまたの機会とさせていただきます。
UUID に限らずデータベースやパフォーマンスの領域では結果だけを見るのではなく、その結果の意味や仕組みを理解することが不可欠です。
そうでないと問題に対する本質的な対処が難しくなってしまいます。本稿はその「仕組み」に焦点をあてた記事になっているので、この情報が少しでもみなさんの役に立てていればと思っています。
データベースのチューニングに関しては以下の記事も参考にしていただけたらと思います。
- 理屈で考える、データベースのチューニング
- そのまま使える、Oracleインデックスのキー圧縮ガイドラインとインデックス設計の話
- Oracleチューニングの裏技!標準機能だけでパーティションテーブルを作る方法
またインフラエンジニアとしての基礎体力であるシェルに関する記事もいくつか書いています。
さて、ラクーングループは一緒に働く仲間を絶賛大募集中です!
データベースのパフォーマンスに興味ある方でも、業務でデータベースを使っているけどこれからだなって方でも、もし少しでも興味を持っていただけたら是非こちらからエントリーお待ちしています!




![[GA4] Google Analytics 4 でサイト速度を計測する方法](https://techblog.raccoon.ne.jp/wp-content/uploads/2022/04/00.ga4_sitespeed-500x500.jpg)