n+1問題の対応 あえてn+1にする場合もある!?
開発チームの下田です。
ラクーンホールディングス技術戦略部ではオフライン+オンラインのエンジニア向けイベントを開催しています。connpassで告知するので、ご覧ください。
Raccoon Tech Connect #2 パフォーマンス改善LTでn+1問題について話してきたので、そちらの記事化になります。
n+1問題とは
n+1問題とは、データ取得時に発生するパフォーマンス問題の一種です。RailsのActiveRecordなど、ORマッパーを使用したクエリでよく発生します。最初のSELECTクエリで取得したn行の一覧の1行1行に対して、子テーブルのSELECTを1回以上発行してしまい、クエリの発行回数がn+1回になってしまう問題です。
orders = Order.all.limit(100) # ここで1回SELECT
## 注文に紐づく出荷があるかarrayで返す
orders.map{|order| order.delivery.present?} # n回SELECTが走ってしまう
n+1になりそうなところ
こちらは弊社サービスの受注・発注システムCORECの受注一覧画面です。
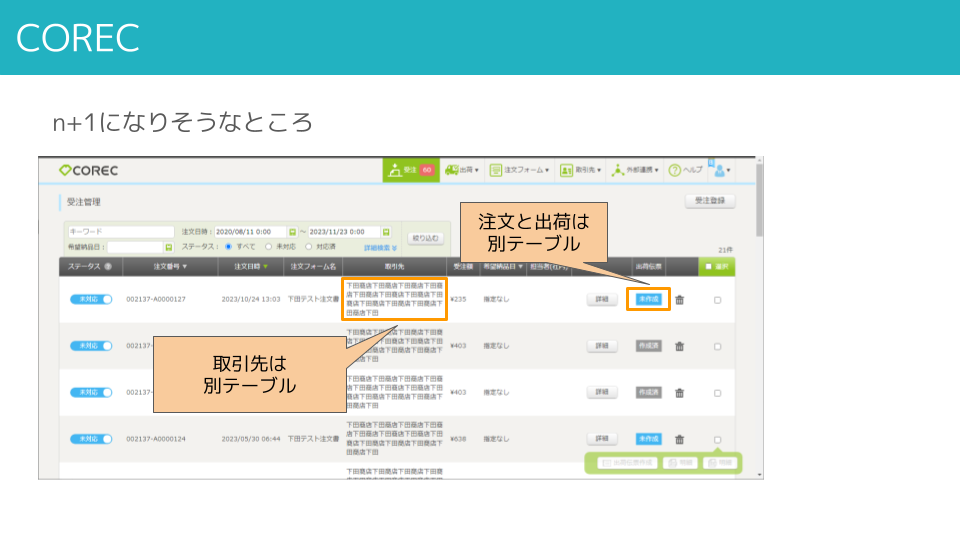
受注に対して出荷があるかどうかチェックしたり、取引先名を表示するところでn+1問題が潜んでいます。
簡単にE-R図
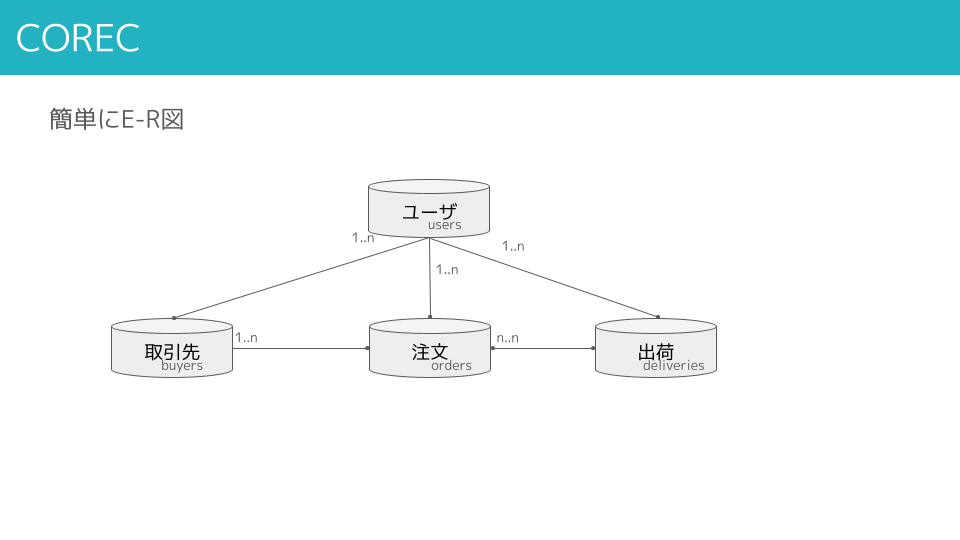
ユーザに対して取引先が複数、その取引先に対して注文が複数、注文に対して出荷は1つの出荷にまとめたり、複数の出荷に分割したりするのでn:nです。ということは、ユーザから見たときは注文も出荷も1:nです。
RDBMSは遅い
もちろん環境によりますが、基本的にRDBMSにSELECTで問い合わせると遅いです。だいたい10msはかかります。
1ページに100行 * 関連テーブルが2個があるとき、n+1問題が発生すると201回のクエリになります。
201クエリ * 10ms = 2秒 かかります。この程度でも、体感できる遅さです。
n+1問題を解消するフェッチ戦略
n+1問題を解消するには、データベースからまとめて取得すること、つまりフェッチ戦略を考えます。
代表的な方法
- JOINしてまとめて取得する(Railsでいうeager_load)
- テーブルごとに1回取得する(Railsでいうpreload)
eager_load
子テーブルを先にLEFT JOINしフェッチする戦略です。
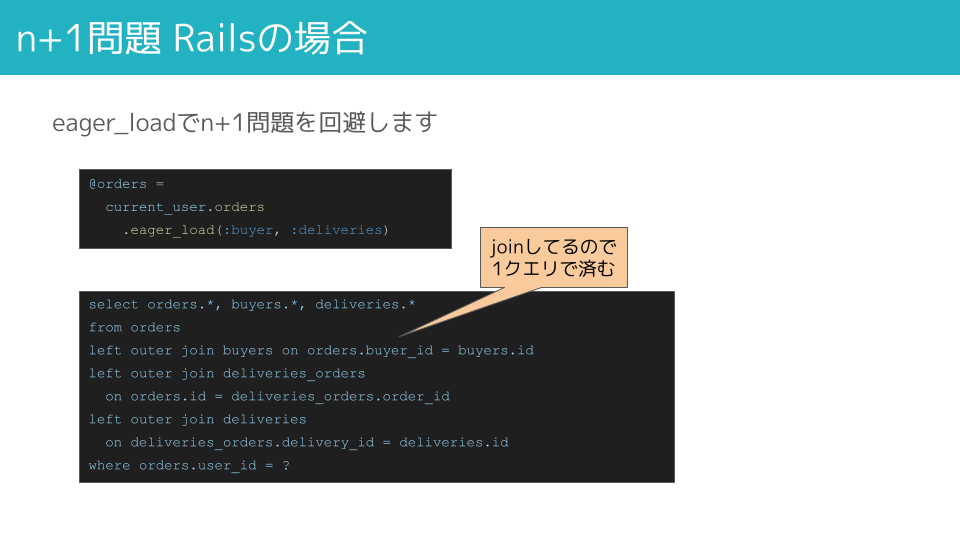
eager_loadで気をつけなければならないポイントは、JOINすると直積するということです。
子テーブル1に100行あり、子テーブル2に50行あるとき、同時にJOINすると転送する行数は5000行となります。
行数はもちろん、データ自体も増えます。

上の2つの表が元の表、下がSELECTした結果を表した表です。1行*2行で増えていないように思いますが、赤く塗っている部分が上のマスと全く同じデータになっていて、無駄に取得していることがわかります。行数が指数的に増える * 1行あたりのデータ量も増えるので、eager_loadする場合は転送量の見積が必須です。
preload
preloadはJOINせず、子テーブルを別々に1テーブルずつSELECTするフェッチ戦略です。
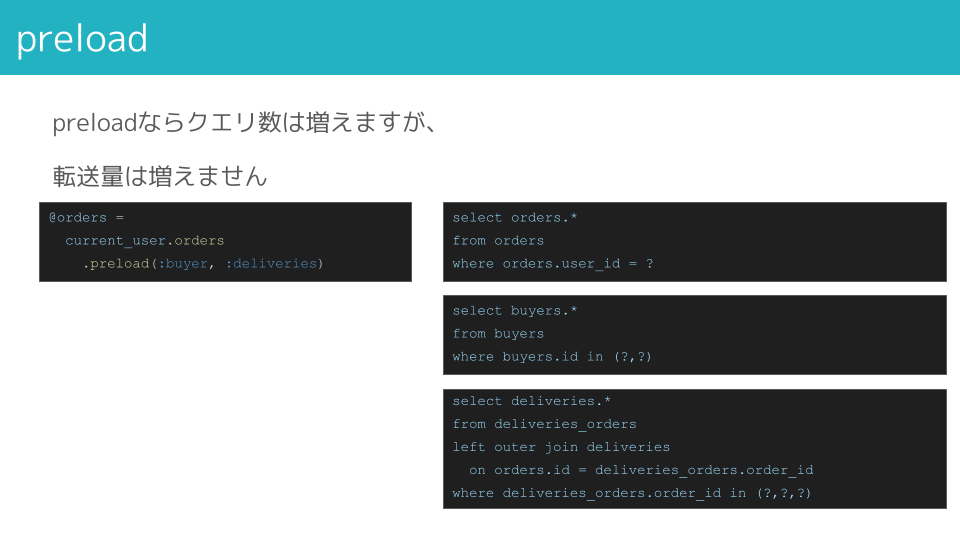
フェッチ戦略まとめ
- eager_loadは必ず1クエリで済む。ただし転送量が増える
- preloadはクエリ数がn+1よりは少ないものの数クエリは必要
どのフェッチ戦略も一長一短あり、トレードオフがあります。
どれにするか要検討です。
eager_loadにするか?
preloadにするか?
それともどちらも選ばずにn+1にするか?
あえてn+1にする場合も考えられます。
パフォーマンスチューニングでのポイント
改めて問題を整理すると・・
1ページ100行 * 子テーブルが2つ = 子テーブル取得が200クエリ
1クエリあたり10msかかると
1ページ表示するのに201クエリ * 10ms = 2010msかかる
2秒かかってしまうのが遅いので、チューニングしたいという問題です。
フェッチ戦略ではクエリ数を減らして、1クエリ * 10ms = 10msにするようなアプローチを取りました。
もう一つの方法は、1クエリあたりの時間を削減する方法です。1クエリあたり1msになれば200msになりますし、ほぼ0まで減らせれば、トータルもほぼ0秒になります。
1クエリあたり10msもかかってしまうのは、RDBMSが遅いからでした。つまりRDBMS以外の速い何かに代替できれば、このようにパフォーマンスチューニングできます。つまりキャッシュです。
キャッシュ
キャッシュはパフォーマンスチューニングに絶大な効果があるものの、油断するとデータ不整合を引き起こしてしまう特性があります。
不整合を防ぐには、なるべくシンプルな戦略が好ましいです。
データベースのプライマリーキーをキャッシュキーにする戦略はシンプルで、扱いやすいです。

子テーブルをキャッシュする方法が有効なパターン

一覧を取得した後、子テーブルをn回取得し、子テーブルをキャッシュしておきます。
まったく同じ条件で検索すると、当然全件キャッシュヒットするので高速です。

検索条件やソート順を変更した場合でも、キャッシュヒットする可能性が高いです。

preload的なクエリで丸ごとキャッシュしてしまうと、このパターンのときにキャッシュヒットさせるのは困難です。できないわけではないのですが、キャッシュの制御がかなり複雑になります。
- 同じデータを複数ユーザが参照するユースケースで有効
- 一覧機能でキャッシュしたデータを明細機能でも使い回せる
- キャッシュクリアが必要な場合、個別にクリアできる
- ただしキャッシュされていない場合は、普通にn+1回のクエリとなり遅い
といった特徴があります。限られていますが、よくあるユースケースだと思います。
まとめ
n+1問題の場合はn(行数)*1クエリにかかる時間がかかります。行数を減らしても、1クエリにかかる時間を減らしてもパフォマンスチューニングできます。
結局のところ、パフォーマンスチューニングは実際に何回、どんなデータの転送が行われるのか考えることが大事です。
ラクーンホールディングスでは1億レコードの取引データなど、それなりの分量のデータがあります。一緒にパフォーマンス・チューニングしてくれるエンジニア・大量のデータを使いやすくするデザイナー・HTMLコーダーを大募集中です!
興味を持っていただいた方は是非、お話ししましょう!