自動化やスクレイピングに使えるやつ XPath
開発チームの下田です。
XMLの特定の部分を指定するためのXML Path Language(以下、XPathと表記します)という言語があります。
HTMLを解析して自動テストの作成やスクレイピング、XML設定ファイルの書き換えに使います。簡単な割に、覚えておくと地味に便利なやつです。
とりあえず書いてみる
何はともあれ、覚えるためには書いてみます。
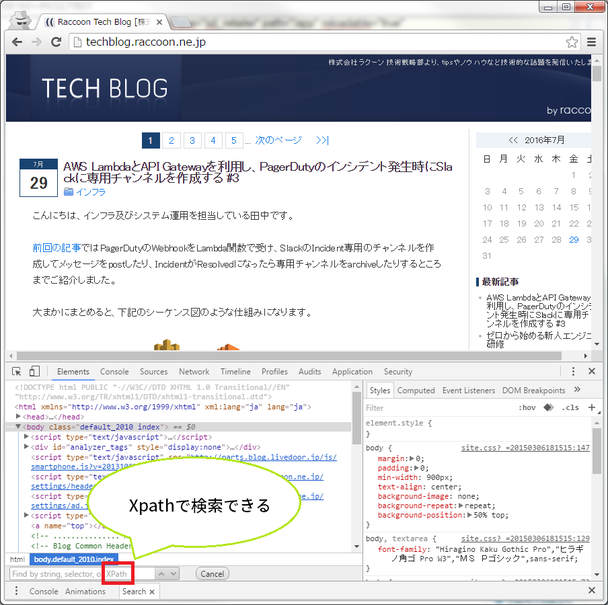
ブラウザが一番手軽なXPathの実行環境だと思います。FirefoxとChromeはXPathが実装されています。コンソールで次のコードを実行してみてください。コンソールはF12を押せば開きます。
document.evaluate('//html/head/title', document, null, XPathResult.STRING_TYPE, null).stringValue正常に実行できれば、開いているページのタイトルが表示されます。
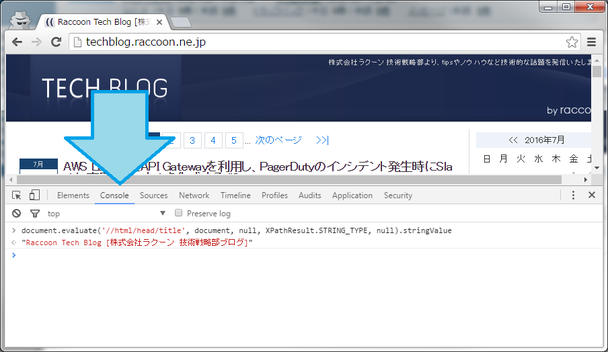
evaluateの1つめの引数にとっている'//html/head/title'がXPathでの表記です。今回はXPathの説明のため、他の引数は割愛します。
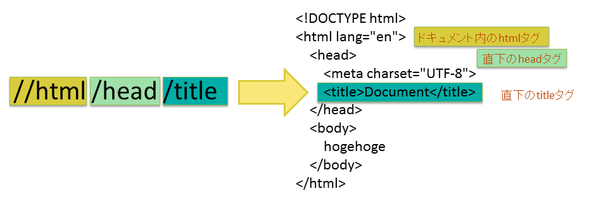
なんとなく察しがつくと思いますが、ドキュメント内のhtmlタグ直下のheadタグ直下のtitleタグを表しています。
cssセレクタでいうと'html > head > title'と同じ要素を示します。
他にも、次のような書き方でtitleタグを表せます。
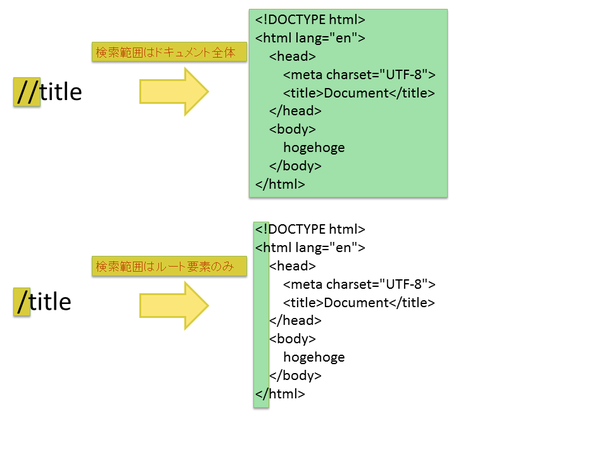
//titletitleタグはhtml内は必ず一つです。つまり、ドキュメント内のいずれかのtitleタグを指定するだけで指定できます。
/html/head/title先頭の/が1つだけです。1つ(/)の場合、直下の要素のみを示します。2つ(//)の場合、子や孫など配下全てを示します。この場合、一番上になるルート要素の中からhtmlタグを選び、その直下のheadの直下のtitleタグを示します。
先ほどの'//title'はドキュメント内のtitleタグを指定したので取得できますが、'/title'とするとルート要素にtitleタグは無いため取得できません。
検索
要素やテキストに一致するものを検索することもできます。
要素は「@要素名」と表します。[]で囲んだ内側に条件式を書くことができ、=は完全一致です。
次の例は、descriptionのタグを表しています。
//meta[@name="description"]テキストを検索する場合は、次のように書きます。テキストが「次のページ」となっているリンクを表しています。
//a[.="次のページ"]ちょっとわかりづらい構文ですが、.は自身(タグの内容)を表しており、.と比較することでテキストを検索しています。
また、前方一致や中間一致には用意されている関数を使用します。
//a[starts-with(., "2016年")]
//a[contains(., "8月")]かなり複雑な検索も行えます。
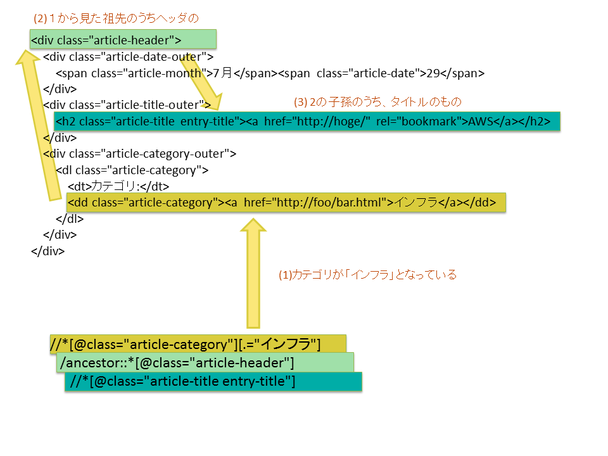
次の例は、当ブログ内でカテゴリが「インフラ」になっている記事のタイトルを表しています。
//*[@class="article-category"][.="インフラ"]/ancestor::*[@class="article-header"]
//*[@class="article-title entry-title"]子から親方向に検索する書き方があります。「ancestor::*」が祖先方向に検索することを表しています。
このような書き方で、EXCELのVLOOKUP関数のような使い方ができます。
他にも、一つ上や下の階層(親や子)、同じ階層の次や前(兄弟)方向に検索したり、多彩な関数が用意されているので、必要に応じてリファレンス等で調べてみると良いでしょう。
設定ファイルの書き換え
ここまではHTMLを例にしていましたが、本来はXML用の言語です。XMLはtomcat等の設定ファイルに使われています。設定ファイルの変更は何度も同じことをする場合もありますが、スクリプトを書いておくと後が楽です。
rubyの標準添付ライブラリのXML パーサ「rexml」を使用し、tomcatの設定ファイルserver.xmlを編集し、HTTPのポートを18080に変更する例を紹介します。
require 'rexml/document'
# tomcatのserver.xml
xml = <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<Server port="8045" shutdown="SHUTDOWN">
<Listener SSLEngine="on" className="org.apache.catalina.core.AprLifecycleListener"/>
<Listener className="org.apache.catalina.core.JasperListener"/>
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener"/>
<Listener className="org.apache.catalina.mbeans.ServerLifecycleListener"/>
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener"/>
<GlobalNamingResources>
<Resource auth="Container" description="desc"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory" name="UserDatabase"
pathname="conf/tomcat-users.xml" type="org.apache.catalina.UserDatabase" >
</Resource>
</GlobalNamingResources>
<Service name="Catalina">
<Connector connectionTimeout="20000" port="8080"
protocol="HTTP/1.1" redirectPort="8443" useBodyEncodingForURI="true"/>
<Connector port="8049"
protocol="AJP/1.3" redirectPort="8443" useBodyEncodingForURI="true"/>
<Engine defaultHost="localhost" name="Catalina">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm" resourceName="UserDatabase"/>
<Host appBase="webapps" autoDeploy="true" name="localhost" unpackWARs="true"
xmlNamespaceAware="false" xmlValidation="false">
<Context docBase="sd_retailer" path="/app" reloadable="true"
source="org.eclipse.jst.jee.server:hogehoge" />
</Host>
</Engine>
</Service>
</Server>
EOF
document = REXML::Document.new(xml)
# Connectorタグ(HTTP)を取得する
connectorHTTP = document.elements['//Connector[@protocol="HTTP/1.1"]']
# portを変更する
connectorHTTP.attributes['port'] = '18080'
# 出力して確認してみる
puts document.to_s
おわりに
XPathは簡単な割に柔軟な指定のできることを、つかんでいただけたでしょうか?
この記事でご紹介したようにプログラム内で使用するだけでなく、ChromeのデベロッパーツールのElementsタブの検索で使えたりと、利用シーンは意外と多いです。
XPathはちょっとした作業を簡略化できる、怠惰なプログラマにはもってこいのツールだと思います。