

ラクーンのCI/CDへの取組みの現状とこれから(1)
こんにちは。技術戦略部で今度から部門長をやることになったたむらです。
「お前も技術部なんだからブログの一本や二本は書け!」との鬼編集長からのプレッシャー(?)があり、頑張ってブログを書いてみます。よろしくお願いします!
今回は「ラクーンのCI/CDへの取組みの現状とこれから」と題して2回に分けて書いてみたいと思います。
アジャイル開発の界隈で良く取り上げられ、昨今メジャーな話題となっているCI(継続的インテグレーション)とCD(継続的デリバリ)という用語ですが、これらで謳われている方法論はラクーンでも採り入れるべき多くのメリットを持っています。
ただ、ラクーンのメインビジネスとなっている「スーパーデリバリー」は10年以上続いている大きなシステムであり、既存のシステムにCI/CDのポリシーを適用していくのは大きなコストと時間が掛かります。そんな意味で、今回のテーマである取組みの実際の内容の他に、ラクーンがどの様にシステムに対して改善のアプローチを図っているかという一例が紹介できればいいなと考えています。
ただ、ラクーンのメインビジネスとなっている「スーパーデリバリー」は10年以上続いている大きなシステムであり、既存のシステムにCI/CDのポリシーを適用していくのは大きなコストと時間が掛かります。そんな意味で、今回のテーマである取組みの実際の内容の他に、ラクーンがどの様にシステムに対して改善のアプローチを図っているかという一例が紹介できればいいなと考えています。
ということで、第1回は Capistrano によるデプロイの効率向上のお話です。
デプロイって面倒くさい ~「Capistrano」登場~
まず、弊社のサービスである「スーパーデリバリー」や「Paid」は以下の様なシステム構成となっています。
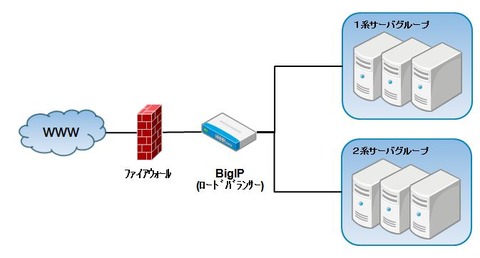
1系サーバグループと2系サーバグループはそれぞれ複数台のサーバから構成されていて、すべてのサーバは同じ構成になっています。そして、1系と2系のグループが正副の関係となっていて、リリース毎に稼動系サーバが切り替わるという様な運用を行なっています。
さて、この様な構成のサーバ群に対してリリースする際、1年半程前迄はリリース手順書を用意してそれに沿って手動でデプロイを行なっていました。リリースの手順は以下の様なものです。
(リリースの手順の概要)
1. リリース物の準備/バックアップ
2. ロードバランサーの振分け状況チェック(ここで1系/2系どちらが稼動系かを確認する)
3. 稼動系サーバ群でのファイル同期チェックジョブの停止
4. ファイル共有サーバへのリリース物のアップロード
5. 待機系Webサーバ群でのリリースファイルの同期
6. 待機系Webサーバ群でのプロセスの再起動
7. 待機系Webサーバそれぞれのログ確認とプロセス稼働確認
8. ロードバランサーの切替(待機系を稼働系に)
9. 旧稼動系サーバ群でのファイル同期チェックジョブの再開
1. リリース物の準備/バックアップ
2. ロードバランサーの振分け状況チェック(ここで1系/2系どちらが稼動系かを確認する)
3. 稼動系サーバ群でのファイル同期チェックジョブの停止
4. ファイル共有サーバへのリリース物のアップロード
5. 待機系Webサーバ群でのリリースファイルの同期
6. 待機系Webサーバ群でのプロセスの再起動
7. 待機系Webサーバそれぞれのログ確認とプロセス稼働確認
8. ロードバランサーの切替(待機系を稼働系に)
9. 旧稼動系サーバ群でのファイル同期チェックジョブの再開
当然、これらのオペレーションのすべてをマニュアルで行っているとミスが発生することもあり、本番サービスがダウンすることも過去に何度か発生していました。
またデプロイには以下の様な問題が絡んで、オペレーションは属人化する傾向にありました。
(デプロイに関する問題)
a. 操作対象サーバが多く作業負荷が高い
b. プロセスの再起動等のオペレーションにより、リリースユーザ権限がほぼ管理者権限になってしまう
c. ロードバランサーの操作が別物になっており、作業負荷・リスクが高い
d. リリース手順自体が複雑
a. 操作対象サーバが多く作業負荷が高い
b. プロセスの再起動等のオペレーションにより、リリースユーザ権限がほぼ管理者権限になってしまう
c. ロードバランサーの操作が別物になっており、作業負荷・リスクが高い
d. リリース手順自体が複雑
そこで採用したのがCapistranoです。Capistrano はオープンソースのソフトウェアデプロイメントツールで、デプロイツールの中では非常にメジャーなものです。複数サーバへの作業の効率化・自動化が簡単に行えます。デフォルトで一通りのデプロイタスクのひな形が用意されているのですが、ラクーンでは上記のリリース手順に沿ったものにする必要があったため独自のタスクを用意して実装することにしました。
では上記で挙げたデプロイに関する問題に対してそれぞれどんなアプローチをしたのかを説明していきましょう。
まず、「a. 操作対象サーバが多く作業負荷が高い」についてです。
これはCapistrano の基本的な機能を使えばそれだけで解決できます。
これはCapistrano の基本的な機能を使えばそれだけで解決できます。
独自タスクはrakeタスクを書く要領で簡単に実装できます。例えばこんな感じです。
(rubyやrakeタスクについての説明はここでは省略します)
(rubyやrakeタスクについての説明はここでは省略します)
■tomcatプロセスの再起動の例(上記「手順6」の一部)■
~ deploy.rb の抜粋 ~
set :application, "deploy"
set :user, "deployuser"
if togroup == "group1"
# 1系統のサーバーグループを定義
role :web, "XXX.XXX.XXX.XX1"
role :web, "XXX.XXX.XXX.XX2"
role :web, "XXX.XXX.XXX.XX3"
elsif togroup == "group2"
# 2系統のサーバーグループを定義
role :web, "YYY.YYY.YYY.YY1"
role :web, "YYY.YYY.YYY.YY2"
role :web, "YYY.YYY.YYY.YY3"
end
desc "cap -f deploy.rb tomcat_action -S togroup=[group1|group2] -s repos=[serviceA|serviceB]"
task :tomcat_action, :roles => [:web] do
# パラメタで指定されたサービスの停止
run "sudo \/etc\/init.d\/#{repos} stop"
run "sleep 10"
# プロセス停止を確認後・・・
run "test `ps -ef | grep \"#{repos}\" | grep -v \"grep\" | wc -l` -eq 0"
# 起動
run "sudo \/etc\/init.d\/#{repos} start"
run "sleep 15"
# 起動ログを出力し確認
run "tail -n 10 \/var\/log\/#{repos}.log"
# プロセス状況を出力し確認
run "ps -ef | grep \"#{repos}\" | grep -v \"grep\""
end
Capistrano では、リモートサーバにsshで接続しコマンドを実行します。その為、事前に Capistrano を実行するマシンとリモート実行する対象のサーバではsshで接続できる設定をしておく必要があります。
上記で定義したtomcatプロセス再起動タスク(tomcat_action)を実行する際は以下の様にコマンドラインから実行します。
$ cap -f deploy.rb tomcat_action -S togroup=group1 -s repos=serviceA
パラメタは"-S"または"-s"の後にname=valueの形で指定します。オプションの"-S"と"-s"の違いは、前者は初期化時から使用したい場合、後者はタスク内でのみ使用する場合に利用します。その為、サーバーグループの選択を行う"togroup"は"-S"、タスク内のみの"repos"は"-s"と使い分けています。
この様にCapistrano ではパラメタにより複数サーバグループを切替えつつ、同一の操作を実行することが簡単に実装できます。
次に、「b. プロセスの再起動等のオペレーションにより、リリースユーザ権限がほぼ管理者権限になってしまう」についてです。
これは、Capistrano 経由でデプロイのコマンドを発行するユーザを新規に作成し、そのユーザに対してsudoers のコマンドエイリアスを定義することで解消させました。
■/etc/sudoersの記載例■
Cmnd_Alias PROCCMD=/etc/init.d/serviceA,/etc/init.d/serviceB
deployuser ALL=NOPASSWD:PROCCMD
この様にすることで、管理者権限が必要な特定のコマンドのみをリリース用アカウントにノーパスワードにて実行させることができます。
直接的には Capistrano とは関わりませんが、Capistrano 実行環境の構築に合わせて環境周りも整備した結果選択できた対処となります。
続いて「c. ロードバランサーの操作が別物になっており、作業負荷・リスクが高い」についてです。
これは、利用しているロードバランサーのプロダクト「BigIP」がI/Fとして提供している bigpipe shell をCapistranoから実行することにより作業を一本化&タスク化することができました。
BigIPはGUIとCUIそれぞれI/Fを持っているのですが、CUIである bigpipe shell はその名の通りLinuxのシェルと変わらない作りの為、問題なく Capistrano から実行することができます。
BigIPはGUIとCUIそれぞれI/Fを持っているのですが、CUIである bigpipe shell はその名の通りLinuxのシェルと変わらない作りの為、問題なく Capistrano から実行することができます。
■ロードバランサーの切替タスクの例(上記「手順8」の一部)■
set :application, "deploy"
set :user, "deployuser"
role :lb, "ZZZ.ZZZ.ZZZ.ZZZ"
desc "cap -f deploy_lb.rb exchange_balancing -S togroup=[group1|group2]"
task :exchange_balancing, :roles => [:lb] do
grp = togroup == "group1" ? 1 : 2
# 指定したプール(1系/2系に分けたサーバグループ)に本番アクセスを切替
run "bigpipe profile httpclass httpclass_serviceA pool pool_serviceA_#{grp}"
# 切替えられたプールを表示
run "bigpipe profile httpclass_serviceA list | grep pool"
# ロードバランサの待機系に設定変更を反映
run "bigpipe config sync all"
end
尚、BigIPはv10.0.0からCUIとして bigpipe shell の他に tmsh というCisco風なシェルがサポートされています。当初ラクーンではBigIPのデフォルトシェルを tmsh にしていたのですが、Capistrano はデフォルトだと tmsh 形式のコマンド実行ができません。そこでBigIP側のデフォルトシェルを bigpipe shell に切り替えて対応することにしました。これにより、「c.」の問題も解消させることができました。
最後に、「d. リリース手順自体が複雑」についてです。
そもそも、何故リリース手順が複雑になるかというと、スーパーデリバリーではコンテンツの更新などで開発案件以外でもサイト更新が頻繁に行われている為、その運用を壊さずにリリースする必要がある事が1つの大きな理由となっています。
手順自体の簡略化はプログラム化することで概ね解消します。しかし、別のマニュアルリリース作業が一部残存してしまうことから、上で挙げたリリース手順「7」の最終的なサイト確認などは現時点では自動化するより目視により行う方が適切だという判断に至りました。
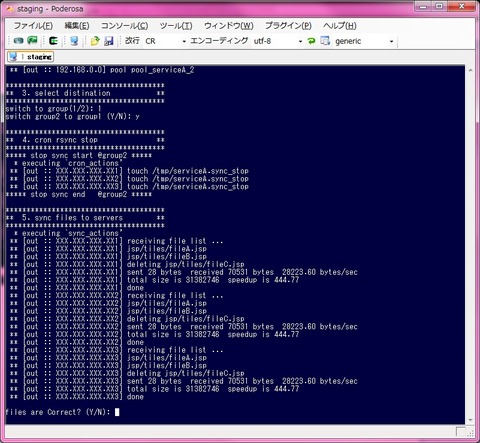
そこで、最終的にはCapistrano のタスクをシェルでラップしてCUIの対話形式ツールとし、適宜確認を行えるところ迄を一つの到達点としました。
そもそも、何故リリース手順が複雑になるかというと、スーパーデリバリーではコンテンツの更新などで開発案件以外でもサイト更新が頻繁に行われている為、その運用を壊さずにリリースする必要がある事が1つの大きな理由となっています。
手順自体の簡略化はプログラム化することで概ね解消します。しかし、別のマニュアルリリース作業が一部残存してしまうことから、上で挙げたリリース手順「7」の最終的なサイト確認などは現時点では自動化するより目視により行う方が適切だという判断に至りました。
そこで、最終的にはCapistrano のタスクをシェルでラップしてCUIの対話形式ツールとし、適宜確認を行えるところ迄を一つの到達点としました。
■シェルでラップしたデプロイツールのイメージ■
以上の様にラクーンの持っていたデプロイの問題に対して、Capistrano という強力なツールを軸にデプロイの改善を進めたのでした。
色々と不完全な部分もあり完全自動化迄は至っていませんが、これによりオペレーションミスの抑制や作業の省力化はかなり進めることができました。
今回はここ迄になります。
次回は Selenium を用いた自動テストと Capistrano や Selenium 等のツールを統合してくれる Jenkins の話題に続きます。




![[GA4] Google Analytics 4 でサイト速度を計測する方法](https://techblog.raccoon.ne.jp/wp-content/uploads/2022/04/00.ga4_sitespeed-500x500.jpg)
