

GlusterFSの導入とGeo-Replication
こんにちは。管理チームのいとうです。
今回は分散ストレージのGlusterFSをご紹介します。
これまでNFSやiSCSI、ZFSなど様々なストレージ技術を扱ってきましたが、
まだ分散ストレージについては未経験でした。そこで今回はGlusterFSの導入をやってみることにしました。
GlusterFSについて
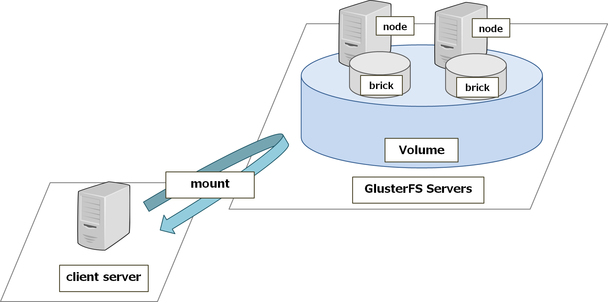
GlusterFSはRedhatにより開発されている、ファイルシステムです。
簡単に仕組みを説明すると、複数のサーバ上にある「ブリック」を統合することで論理的なボリュームを作り、ファイルシステムとして利用できる仕組みです。
ボリュームの構成方法もストライピングやミラーリング、冗長データを使った対障害性の向上、それらの組合せなど種類が多く、目的の用途に合わせて柔軟な構成を取ることが出来ます。
用語について
GlusterFSを利用する際に出てくる用語について解説します。
ノード
ノードとは、GlusterFSのデーモンが動作しているサーバを指します。
複数のノードがお互いに信頼関係を結び、ボリュームを構成します。
ブリック
ブリックはGlusterFSのボリュームを構成する基本単位で、
各サーバのローカルストレージ上のディレクトリを利用します。
このブリックを統合することで、論理的なボリュームを見せることになります。
ボリューム
ボリュームは実際にファイルシステムとして利用されるストレージ領域を指します。
先述のように、複数のブリックによって構成されます。
今回の検証内容
GlusterFSはよく洗練されており便利な機能もたくさんあるのですが、
今回は以下の内容を検証してみようと思います。
GlusterFSの導入
GlusterFSの導入と初期設定、そしてReplicatedボリュームの作成を行ってみます。
Geo-Replication
ディザスタリカバリ環境の構築を想定してローカルサイトとリモートサイトを用意し、
サイト間でボリュームのレプリケーションが行えるGeo-Replication機能の検証をしてみます。
検証環境について
今回は以下の環境を用意しました。
ストレージとなるサーバが2ノード×2系統で4台用意します。
そしてクライアントとして振る舞うサーバを1台用意します。
いずれもCentOS6.9(2GB RAM, 2Core CPU)で構築しています。
また、OS用領域とは別にGlusterFSのブリック用ディスクとして16GBのディスク(/dev/sdb)を追加しています。
事前準備
導入を始める前に、事前準備をいくつか行う必要があります。
ブリック用領域の作成
GlusterFSのブリック用領域として、/dev/sdb1を作成します。
作成手順は割愛しますが、今回はext4で作成しました。
これを/gluster/brick01にマウントしておきます。
名前解決
各ノードの名前解決が正常に行われるように、hostsファイルまたはDNSに各ノードのレコードを追加しておきましょう。
ノードの時刻を同期する
時刻同期が正しく行われていないと、ファイル同期の際に問題が発生します。
NTPで時刻同期を行っておきましょう。
GlusterFSの導入
パッケージのインストール(サーバ側)
ではインストールに入っていきます。
GlusterFSはCentOSが提供しているレポジトリから入手可能です。
いくつかのバージョンが提供されていますが、今回は最新のものを利用します。
local-sv01, local-sv02, remote-sv01, remote-sv02で以下のコマンドを実行します。
# yum -y install centos-release-gluster310-1.0-1.el6.centos.noarch
# yum -y install glusterfs-server glusterfs-geo-replication
インストールが完了したら、glusterdを起動しましょう。
# service glusterd start
Starting glusterd: [ OK ]
次に、自動起動の設定を確認します。
# chkconfig --list | grep gluster
以下のようにglusterdとglusterfsdが登録されているかと思います。
glusterd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
glusterfsd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
もしglusterdの自動起動が有効になっていない場合は、以下のコマンドで有効にしておきましょう。
# chkconfig glusterd on
パッケージのインストール(クライアント側)
GlusterFSのボリュームは、クライアント側ではFUSE(Filesystem in Userspace)機構を利用した、ユーザ空間で動作するファイルシステムとして振る舞います。
そのためglusterfs-fuseパッケージをインストールしておく必要があります。
# yum -y install centos-release-gluster310-1.0-1.el6.centos.noarch
# yum -y install glusterfs glusterfs-fuse
コマンドを実行して正しくインストールされていることを確認します。
# glusterfs --version
glusterfs 3.10.5
Repository revision: git://git.gluster.org/glusterfs.git
Copyright (c) 2006-2016 Red Hat, Inc.
GlusterFS comes with ABSOLUTELY NO WARRANTY.
It is licensed to you under your choice of the GNU Lesser
General Public License, version 3 or any later version (LGPLv3
or later), or the GNU General Public License, version 2 (GPLv2),
in all cases as published by the Free Software Foundation.
Trusted Storage Poolを構成する
GlusterFSではノード同士が信頼関係を結ぶことで、ストレージプールを構成します。
このプール(≒ブリックの集まり)からボリュームの切り出しを行います。
まず現在のlocal-sv01の接続ノード数を確認してみましょう。
以下のコマンドを実行します。
# gluster peer status
Number of Peers: 0
まだどのノードとも接続を行っていないので、ピア数は0と表示されます。
次に以下のコマンドを実行し、local-sv02と接続を確立してみましょう。
# gluster peer probe local-sv02
以下のようなメッセージが表示されれば、正常に接続が確立できています。
もしエラーが出る場合は、名前解決がきちんとできているかなど確認してみて下さい。
peer probe: success.
では、もう一度接続ノード数を確認してみましょう。
# gluster peer status
Number of Peers: 1
Hostname: local-sv02
Uuid: 5902b2da-37c2-4971-b451-2be49de95e99
State: Peer in Cluster (Connected)
"Number of Peers: 1"となっており、local-sv02が追加されていることが確認できました。
local-sv01自身がカウントされていませんが、自分自身は暗黙的に接続ノードになっているので問題ありません。
これでひとまずlocal-sv01, local-sv02の2台でストレージプールを構築できました。
ボリュームタイプ
これからボリュームを作成していきますが、その前にいくつかあるボリュームのタイプについて説明します。
Replicated Volume
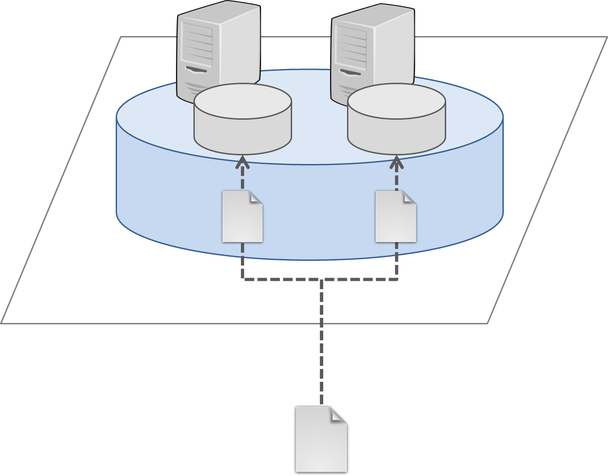
このタイプのボリュームはRAID1に相当します。ファイルの完全なコピーをボリュームを構成する各ブリックに保存するので、
いずれかのノードに障害が発生しても、データの喪失を防ぐことができます。
利用できる容量はボリューム内の最も小さいブリックのサイズになります。
Striped Volume
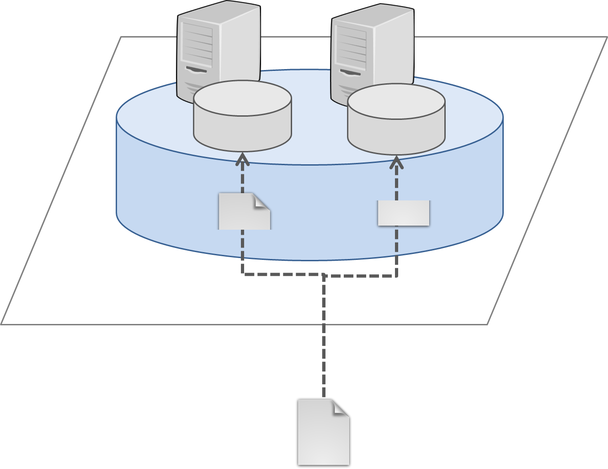
このタイプのボリュームはRAID0に相当します。データを決められたブロックサイズに分割し、各ブリックに分散して書き込みます。
書き込み処理は各ブリックに並列で行われるため大きなサイズのファイルを扱うのに適していますが、
いずれかのノードに障害が発生した場合、データの喪失が発生する可能性があります。
従い別途ノード側でRAID構成を取るなどして、対障害性を高める対策が必要になります。
利用できる容量は (ボリューム内の最も小さいブリックのサイズ) × (ブリック数) です。
Distirbuted Volume
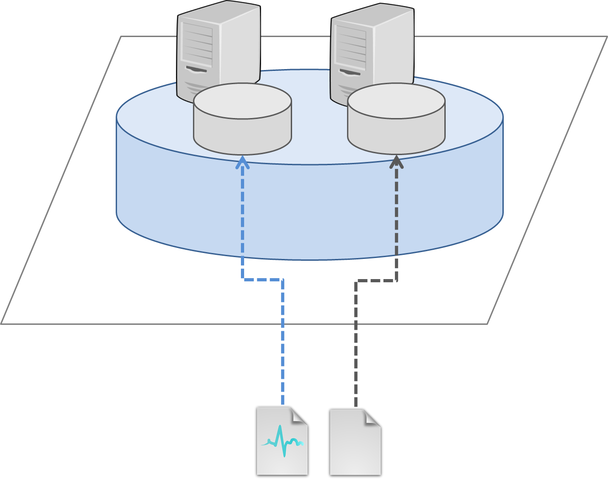
このタイプのボリュームは各ブリックへの書き込みがファイル単位で分散されます。
ディスクへの書き込みは並列化されず対障害性も高くはありませんが、ブリックの容量を有効に扱うことができるため、
大容量のボリュームを利用したい際に有効です。
利用できる容量はボリューム内のブリックサイズの総和です。
Dispersed Volume
このタイプのボリュームはStriped Volumeに似ていますが、イレイジャーコードを付加して書き込むという点で異なっています。
これによりブリックに障害が発生した場合でも、正常なブリックのデータに含まれたイレイジャーコードを利用してデータを復旧することが可能になります。
いくつのブリック障害まで耐えられるかの設定(≒冗長化レベル)はボリューム作成時に設定可能で、利用できる容量は (ブリック数 - 冗長化レベル) × (ブリックサイズ) となります。
その他
その他にも、上記のタイプを組合せたボリュームも作成することが可能です。
例えばReplicationとStripedの組合せや、ReplicationとDistributedの組合せなどが選択可能です。
ストレージに対する要件や掛けられるコストに応じて、適切なタイプはどれか?を検討しましょう。
ボリュームを作成する
では実際にボリュームを作成してみましょう。
GlusterFSの管理には主にglusterコマンドを通して行います。ボリュームを作成するので、gluster volume createコマンドセットを利用します。
2つのブリックでReplicated Volumeを作成する際の必要最低限のコマンドは以下のようになります。
# gluster volume create (ボリューム名) replica (ブリックの数) ノード名:(ブリック名) ノード名:(ブリック名)
local-sv01とlocal-sv02のブリックでReplicated Volumeを作成します。
# gluster volume create volume01 \
replica 2 \
local-sv01:/gluster/brick01/volume01 \
local-sv02:/gluster/brick01/volume01
正常にボリュームが作成されると、以下のように結果が表示されます。
volume create: volume01: success: please start the volume to access data
ボリュームは作成が完了した時点では利用可能になっていません。
startコマンドを実行して明示的に開始する必要があります。
# gluster volume start volume01
正常に開始されると以下のメッセージが表示されます。
volume start: volume01: success
ボリュームの情報を確認する場合は以下のコマンドを実行します。
# gluster volume info volume01
ボリュームを構成するブリックの数やオプション設定などを確認することができます。
Volume Name: volume01
Type: Replicate
Volume ID: 2cdf1cb5-e6c9-473e-a144-183528f5ef12
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: local-sv01:/gluster/brick01/volume01
Brick2: local-sv02:/gluster/brick01/volume01
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
それでは実際に作成したボリュームをマウントしてみましょう。
client-sv01でマウントを実行します。
# mount -t glusterfs local-sv01:/volume01 /mnt
ボリュームがクライアントから利用可能になったので、サイズを確認してみましょう。
# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
local-sv01:/volume01 16G 47M 15G 1% /mnt
Replicated Volumeなので、使用可能な容量はブリックと同じサイズで表示されていることがわかります。
試しにファイルを一つ作成して、レプリケーションが正常に行われることを確認してみましょう。
# echo "テストファイルを作成してみる" > /mnt/testfile
# ls -l /mnt/testfile
-rw-r--r-- 1 root root 43 9月 15 18:10 2017 /mnt/testfile
クライアント側からはファイルが作成されていることが確認できました。
では、それぞれのブリック上のファイルを参照します。
まずはlocal-sv01で
# ls -l /gluster/brick01/volume01/testfile
-rw-r--r-- 2 root root 43 9月 15 18:10 2017 /gluster/brick01/volume01/testfile
# cat /gluster/brick01/volume01/testfile
テストファイルを作成してみる
次にlocal-sv02で
# ls -l /gluster/brick01/volume01/testfile
-rw-r--r-- 2 root root 43 9月 15 18:10 2017 /gluster/brick01/volume01/testfile
# cat /gluster/brick01/volume01/testfile
テストファイルを作成してみる
どちらのブリックにも正しくファイルが作成されていることが確認できましたね。
では次に、local-sv01をシャットダウンしたら、クライアントからファイルがどう見えるのかを確認してみます。
# shutdown -h now
シャットダウン後、クライアントで先ほどのファイルを確認します。
# ls -l /mnt/testfile
-rw-r--r-- 1 root root 43 9月 15 18:10 2017 /mnt/testfile
# cat /mnt/testfile
テストファイルを作成してみる
local-sv01をマウント先に指定していましたが、接続は切れずに正常にファイルが表示されています。
これはクライアント側でファイルアクセスの振り分け処理を行っているため、
local-sv01がダウンしていても、正常に動作しているlocal-sv02に処理が振り分けられたためです。
このようにGlusterFSではクライアント側とサーバ側の双方で、様々な処理を行うモジュール(トランスレータ)が協調して動作することで、
分散ストレージとしての機能を実現しています。
Geo-Replicationを試す
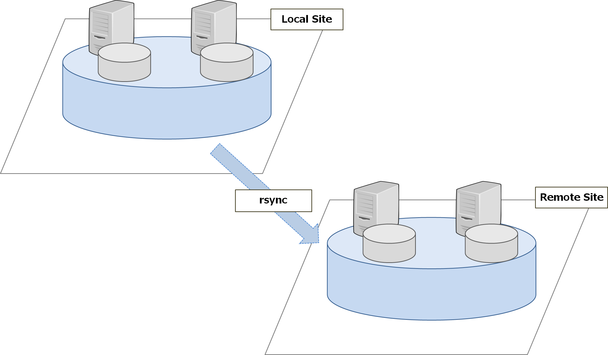
ここまでは基本的なボリュームの作成方法について見てきましたが、ここからはGeo-Replicationの検証を行っていきたいと思います。
Geo-Replicationとは、マスター-スレーブ形式で遠隔地のボリュームに対して非同期でボリュームの内容を複製する機能です。
今回は、新たにリモート側サーバ(remote-sv01, remote-sv02)でストレージプールを構成し、ボリュームを作成します。そして、ローカル側のボリューム(volume01)をマスターとし、リモート側のボリュームをスレーブとして同期を行う設定を検証してみたいと思います。
以後ローカル側をレプリケーションマスター、リモート側をレプリケーションスレーブとします。
Geo-Replicationの要件
Geo-Replicationを行うためには、いくつかの要件を満たす必要があります。
時刻の同期
レプリケーションマスター間で時刻が同期されていない場合、レプリケーションスレーブへのファイル同期に遅延が発生する可能性があります。
NTPなどを利用して確実に時刻を同期しておきましょう。
rsyncコマンド
Geo-Replicationではrsyncコマンドを利用します。
従い、レプリケーションマスター・レプリケーションスレーブ共にrsyncコマンドが利用可能である必要があります。
レプリケーションスレーブでストレージプールを構成する
レプリケーションマスターと同様に、gluster peerコマンドでストレージプールを構成します。
# gluster peer probe remote-sv02
peer probe: success.
接続が確立されたことを確認しましょう。
# gluster peer status
Number of Peers: 1
正常に接続ができたようです。
レプリケーションスレーブでボリューム作成
次にボリュームの作成を行います。
こちらもレプリケーションマスターと同じようにgluster volume createコマンドを利用します。
ボリューム名はvolume02とします。
# gluster volume create volume02 replica 2 remote-sv01:/gluster/brick01/volume02 remote-sv02:/gluster/brick01/volume02
volume create: volume02: success: please start the volume to access data
ボリュームの作成が完了したので、ボリュームを開始します。
# gluster volume start volume02
volume start: volume02: success
ではvolume02の情報を確認してみましょう。
# gluster volume info volume02
Volume Name: volume02
Type: Replicate
Volume ID: 3380d604-0c7b-476a-97fc-084fd0a878be
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: remote-sv01:/gluster/brick01/volume02
Brick2: remote-sv02:/gluster/brick01/volume02
Options Reconfigured:
nfs.disable: on
transport.address-family: inet
remote-sv01, remote-sv02のブリックでボリュームが構成されていることが確認できたかと思います。
Geo-Replication専用ユーザの作成
Geo-Replicationではボリューム間のファイルを同期するためにSSHを利用します。
rootユーザと非特権ユーザのどちらでもGeo-Replicationは可能ですが、
セキュリティの事を考えるとSSHでrootログイン可能にするのは避けたいところです。
従って、今回はレプリケーション専用のユーザを作成し、レプリケーションを行う方法を取りたいと思います。
以下、レプリケーションマスターからレプリケーションスレーブへ公開鍵認証を利用したログインができるよう、設定を行っていきます。
まず、レプリケーションスレーブにGeo-Replication専用のグループ(geogroup)とユーザ(geouser)を作成します。
併せてgeouserにパスワードを設定しておきましょう。
# groupadd geogroup
# useradd -g geogroup geouser
# passwd geouser
mountbrokerの設定
非特権ユーザでレプリケーションを行う場合、gluster-mountbrokerというサービスを介してレプリケーションが行われます。
レプリケーションスレーブにて、rootユーザでgluster-mountbrokerで利用するためのディレクトリを作成します。
# mkdir -p /var/mountbroker-root
# chmod 0711 /var/mountbroker-root
次にmountbrokerのセットアップを行い、非特権ユーザを特定のボリュームにアクセス可能にする設定を行います。
まずはgeogroupのmount rootを設定します。
# gluster-mountbroker setup /var/mountbroker-root geogroup
+-------------+-------------+--------------+
| NODE | NODE STATUS | SETUP STATUS |
+-------------+-------------+--------------+
| remote-sv02 | UP | OK |
| localhost | UP | OK |
+-------------+-------------+--------------+
次にgeouserのvolume02に対するアクセスを設定します。
# gluster-mountbroker add volume02 geouser
+-------------+-------------+------------+
| NODE | NODE STATUS | ADD STATUS |
+-------------+-------------+------------+
| remote-sv02 | UP | OK |
| localhost | UP | OK |
+-------------+-------------+------------+
設定が完了したのでmountbrokerの状態を確認してみます。
# gluster-mountbroker status
+-------------+-------------+-----------------------+--------------+--------------------+
| NODE | NODE STATUS | MOUNT ROOT | GROUP | USERS |
+-------------+-------------+-----------------------+--------------+--------------------+
| remote-sv02 | UP | /gluster/brick01/(OK) | geogroup(OK) | geouser(volume02) |
| localhost | UP | /gluster/brick01/(OK) | geogroup(OK) | geouser(volume02) |
+-------------+-------------+-----------------------+--------------+--------------------+
うまく設定できているようです。
設定を反映するため、一度glusterdを再起動します。
# service glusterd restart
SSHログイン用のための公開鍵の生成と配布
次にSSHの設定です。
レプリケーション時のログイン用にレプリケーションマスターの両方でSSH鍵を生成し、
レプリケーションスレーブ両方のgeouserに公開鍵を配布します。
なお、geouserにSSHログインした際の実行コマンドをgsyncdのみに制限するため、公開鍵に設定を追加しています。
ssh-copy-idコマンドではgeouserのパスワードを尋ねられるので、先ほど設定したパスワードを入力しましょう。
# gluster-georep-sshkey generate
# cd /var/lib/glusterd/geo-replication
# perl -pe 's@^@command="/usr/libexec/glusterfs/gsyncd" @g' -i secret.pem.pub
# [local-sv01およびlocal-sv02でそれぞれ実行]
# ssh-copy-id -i secret.pem.pub geouser@remote-sv01
# ssh-copy-id -i secret.pem.pub geouser@remote-sv02
Geo-Replicationの設定
mountbrokerおよびSSHログインの設定が完了したので、本題のGeo-Replicationの設定に移ります。
Geo-Replicationセッションを作成する
Geo-Replicationのセッションを作成します。
レプリケーションマスターのプライマリノード(local-sv01)で以下のコマンドを実行します。
# gluster volume geo-replication volume01 geouser@remote-sv01::volume02 create no-verify
Creating geo-replication session between volume01 & geouser@remote-sv01::volume02 has been successful
# gluster volume geo-replication volume01 geouser@remote-sv01::volume02 config remote-gsyncd /usr/libexec/glusterfs/gsyncd
geo-replication config updated successfully
Geo-Replicationセッションを開始する
Geo-Replicationの準備が完了したので、セッションを開始します。
レプリケーションマスターのプライマリノードで以下のコマンドを実行します。
# gluster volume geo-replication volume01 geouser@remote-sv01::volume02 start
Starting geo-replication session between volume01 & geouser@remote-sv01::volume02 has been successful
"Starting ... successful"と出力されたので、セッションの開始に成功したようです。
Geo-Replicationセッションの状況を確認する
念のためセッションの状況を確認しておきましょう。
レプリケーションマスターのプライマリノードで以下のコマンドを実行します。
# gluster volume geo-replication volume01 geouser@remote-sv01::volume02 status
MASTER NODE MASTER VOL MASTER BRICK SLAVE USER SLAVE SLAVE NODE STATUS CRAWL STATUS LAST_SYNCED
-----------------------------------------------------------------------------------------------------------------------------------------------
local-sv01 volume01 /gluster/brick01/volume01 geouser geouser@remote-sv01::volume02 remote-sv02 Active Changelog Crawl 2017-09-19 18:58:12
local-sv02 volume01 /gluster/brick01/volume01 geouser geouser@remote-sv01::volume02 remote-sv01 Passiv N/A N/A
ここで注目すべきは"STATUS"の項目です。
正常にレプリケーションが行われていると、"Active"もしくは"Passive"になっているかと思います。
もし、何らかの原因でレプリケーションに失敗していると"Faulty"というステータスになるはずです。
その際は、/var/log/glusterfs/geo-replication/以下にあるログを確認して、原因を調査・修正して下さい。
クライアントからローカルのボリュームに接続し、ファイルを作ってみる
無事にレプリケーションが動作したようなので、実際にクライアントからファイルに書き込みを行って、
レプリケーションが行われるか確認したいと思います。
client-sv01でlocal-sv01のvolume01をマウントして、何かファイルを書き込んでみて下さい。
# mount -t glusterfs local-sv01:/volume01 /mnt
# echo "レプリケーションテスト" > /mnt/reptest
書き込んだら、まずレプリケーションマスターのブリック内のファイルを参照してみます。
# cat /gluster/brick01/volume01/reptest
レプリケーションテスト
こちらは正常に書き込まれていますね。
次にレプリケーションスレーブのブリック内のファイルを参照してみます。
# cat /gluster/brick01/volume02/reptest
レプリケーションテスト
こちらにも正常に書き込まれています。
正しくレプリケーションが行われていることが確認できたと思います。
ファイルを削除してみる
今度は作ったファイルを削除してみます。
クライアントで以下のコマンドを実行します。
# rm -f /mnt/reptest
削除したらレプリケーションマスターのブリック内のファイルを参照してみます。
# cat /gluster/brick01/volume01/reptest
cat: /gluster/brick01/volume01/reptest: そのようなファイルやディレクトリはありません
ファイルが削除されています。
次にレプリケーションスレーブのブリック内も消えていることを確認します。
# cat /gluster/brick01/volume02/reptest
cat: /gluster/brick01/volume02/reptest: そのようなファイルやディレクトリはありません
こちらも消えていますね。
これでファイルの作成・削除などのオペレーションがマスター-スレーブ間で正しく同期されていることが確認できました。
まとめ
今回はGlusterFSの導入と基本的な操作、そしてGeo-Replicationについて検証を行いました。
簡単なオペレーションを試すにとどまったので、ファイル数やファイルサイズが大きくなった時に、性能にどのような影響があるのかは気になるところです。
ただ、簡易な設定で導入ができるという点では、初めて分散ストレージを使いたい場合の選択肢として、良いのではないかと思います。
GlusterFSには今回紹介した機能の他にも、スナップショットやTierなど試してみたい機能がまだまだあります。
この機会に是非、触ってみてもらえればと思います。




