【Python×機械学習】iALS行列分解で爆速BtoBレコメンド!ECサイトに企業推薦機能を導入して10日間で3.5万回使われた話
どうも、二年目の小田です!
スーパーデリバリーというBtoBのECサイト上に企業(メーカー)レコメンド機能を実装しリリースしましたので、その内容についてお話しします。
この記事を読むとわかること
- ラクーンホールディングスでの開発環境が分かる
- レコメンドの仕組みが分かる
目次
- 現状の課題と仮説
- プロジェクトの流れ
- 成果内容
- 企業レコメンドの仕組みについて
- 今後の展望
- まとめ
現状の課題と仮説
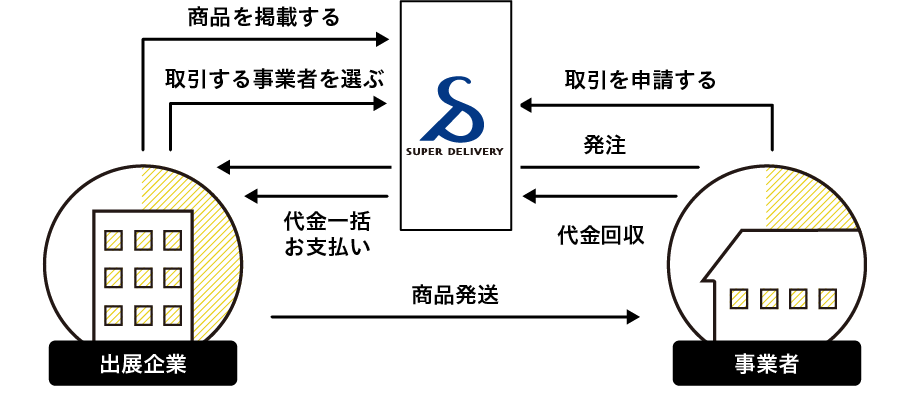
スーパーデリバリーは、事業者と出展企業を繋ぐBtoBのECサイトです。
小売店(事業者)が商品を探そうとすると、出展企業(メーカー)から取り寄せる必要が有ると思います。
今でこそ普通ですが、ECサイトなどがない時代に小売店が自分達に合った出展企業を探し出すのが難しいという課題が小売店にはありました。
そこで、小売店と出展企業を繋ぐBtoBのECサイトを提供することで、小売店の探す手間を省くことができると考えたのが、サービスの経緯となります。
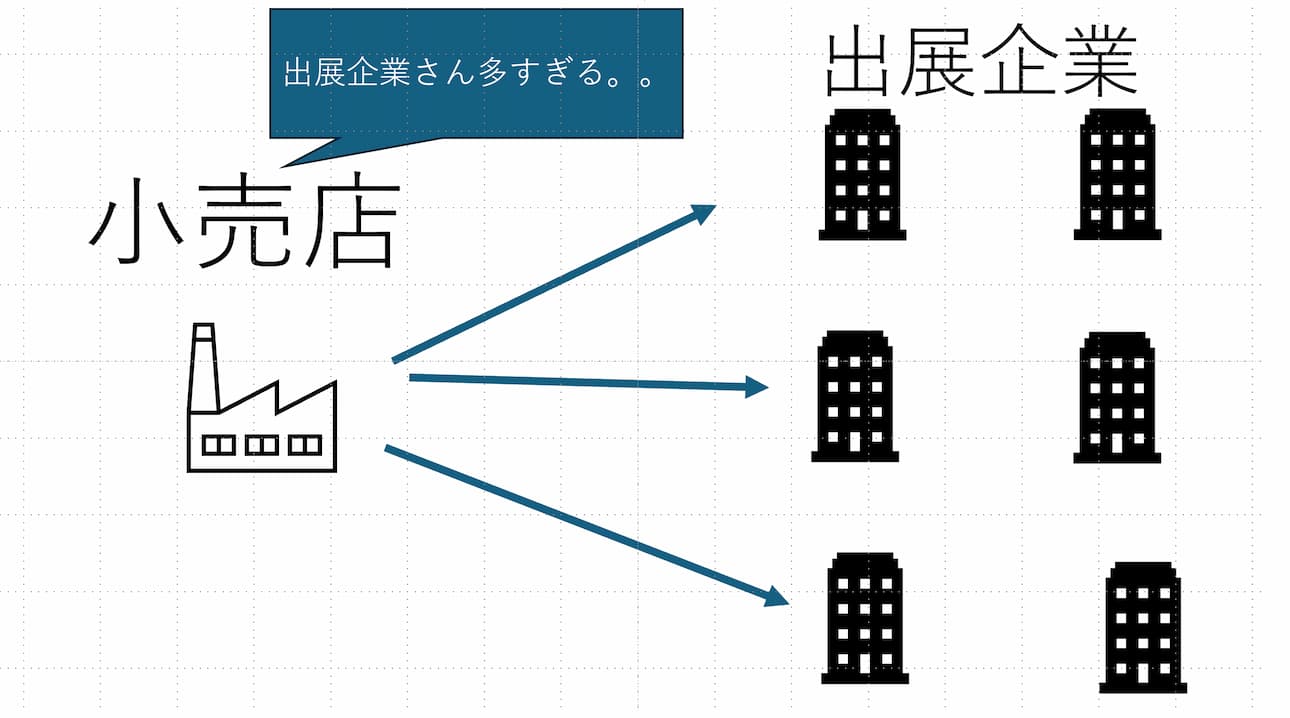
そんなスーパーデリバリーですが、ある問題がありました。
それは小売店が自分に合った出展企業を探すのが難しいということです。
ありがたいことに出展企業の数が3000社以上に増え、出展企業の数が多すぎてどの出展企業が良いかを探すのが難しいということからです。
小売店から3000社の中から自分に合っている出展企業を探すことはそもそも難しいです。
たとえ見つけたとしても、それに類似した出展企業を探すのは難しく自分に合った企業を探すのは至難の技となります。
既にあるものとして、商品単位のレコメンドはありますが、仕入れ先の出展企業がバラバラになってしまうため、送料負担などがかかってしまいます。
そこで小売店会員向けに企業レコメンド機能を実装することで、出展企業(メーカー)を探す手間を省くことができるのではないかと仮説を立てたのが始まりです。
プロジェクトの流れ
開発合宿でのPOC作成
2024年の夏に開発合宿でのPOCが起因となります。
ハッカソン形式のイベントで、3日間で何らかの成果物を作るというものでした。
ここでPOCを作成することができたおかげでプロジェクトが開始されました。
個人的な話ですがラクーンに入る前までに数回ハッカソンに参加しましたがいつも何も作れず失敗に終わっていました。
理由は技術力が不足していたからです。アイデアを実行に移せないもどかしさを感じていました。
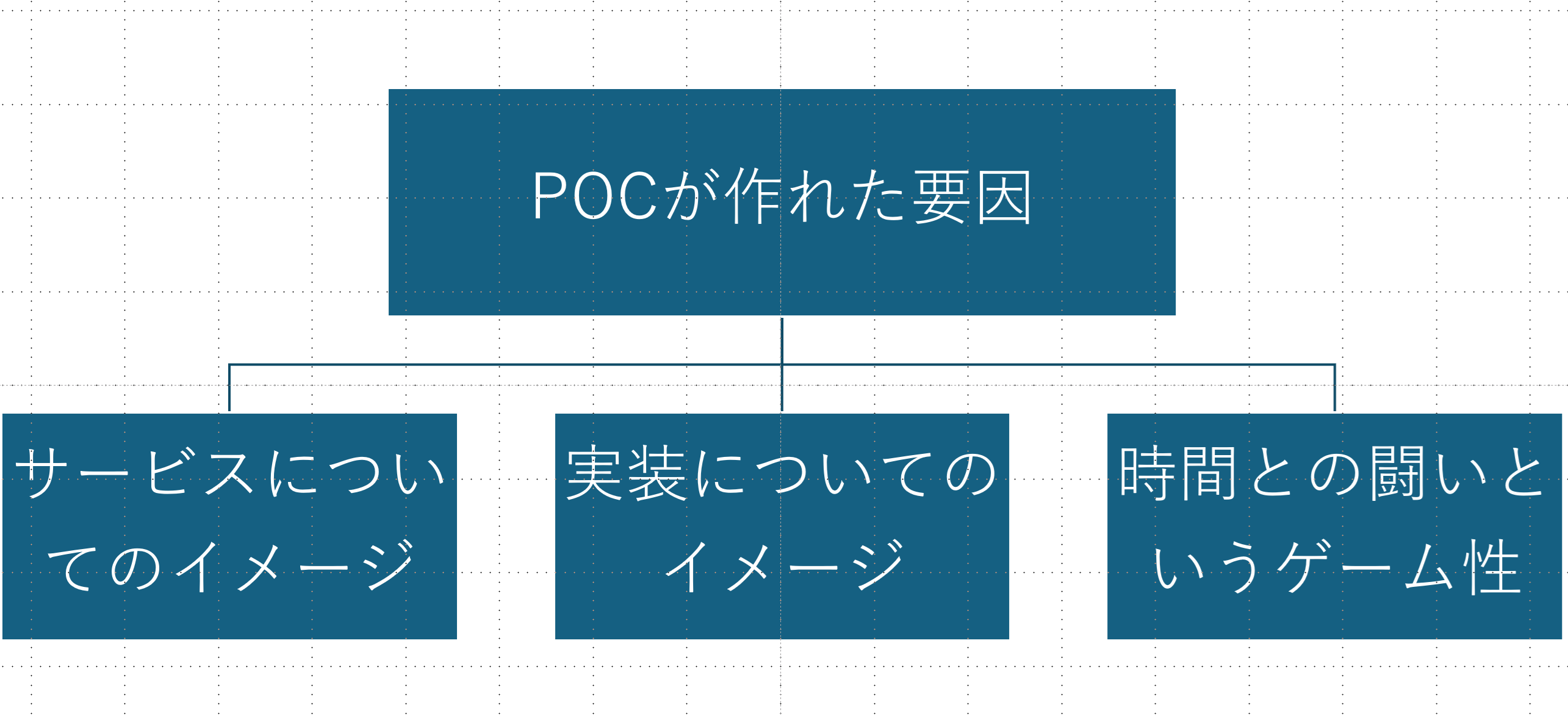
今回の開発合宿ではサービスの提案から一緒に事業部の方と考えていくことができ、企業レコメンドやることに決まったらレコメンドに関してできる限り細かく調べていました。サービスと実装についての両方である程度イメージができており、3日以内に成果物を作るというゲーム性がPOCの作成につながったと思います。
事業部との連携とフィードバック
POCを作成した後は、事業部の方に見てもらいフィードバックをもらいました。
事業部の方からは「この機能はお客さんに価値を届けられると思う」と言ってもらえました。
また、なぜ提案されなかったか聞くと、技術的に可能かどうかを判定する事ができないためという意見が多かったです。
このことから、リアルタイムでのフィードバックは非常に重要だと感じましたし、開発効率が非常に良いなと感じました。
この経験を活かしてなるべく対面でのフィードバックを貰うようにしています。
実装とリリース
そこから実際に実装に入り 2025年3月25日にリリースしました。
インフラの知識がなかったので色々と躓きながら実装を進めていきました。
分からないことがあれば即座に先輩に聞いて、ドキュメントを読みながら実装を進めていきました。
意識した箇所としては分からないことが多かったため、30分調べても解決しない場合は質問するようにしていました。
ルールベースにすることで遠慮なく質問できるようになりました。
至らない点も多かったのですが、本当に先輩方には感謝しています。
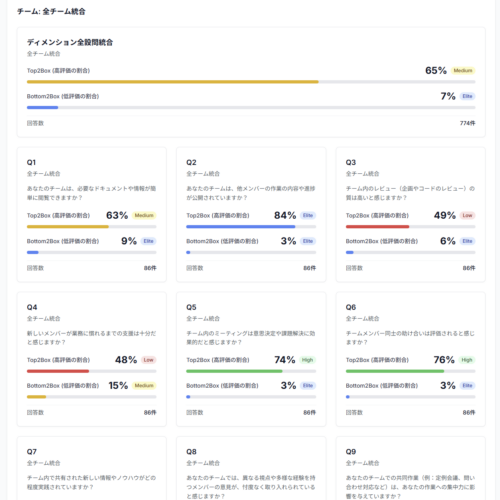
成果内容
成果物は大きく二つあります。
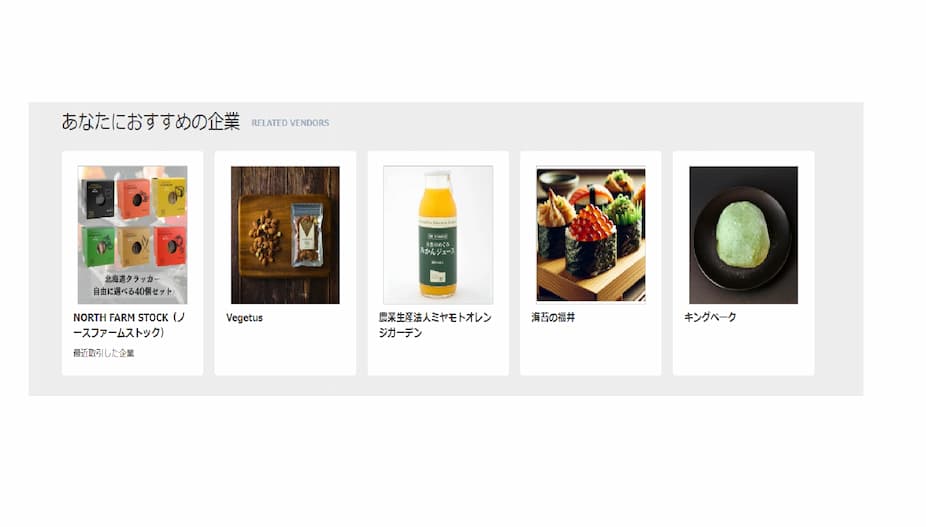
ページ
トップページの企業レコメンドの部分
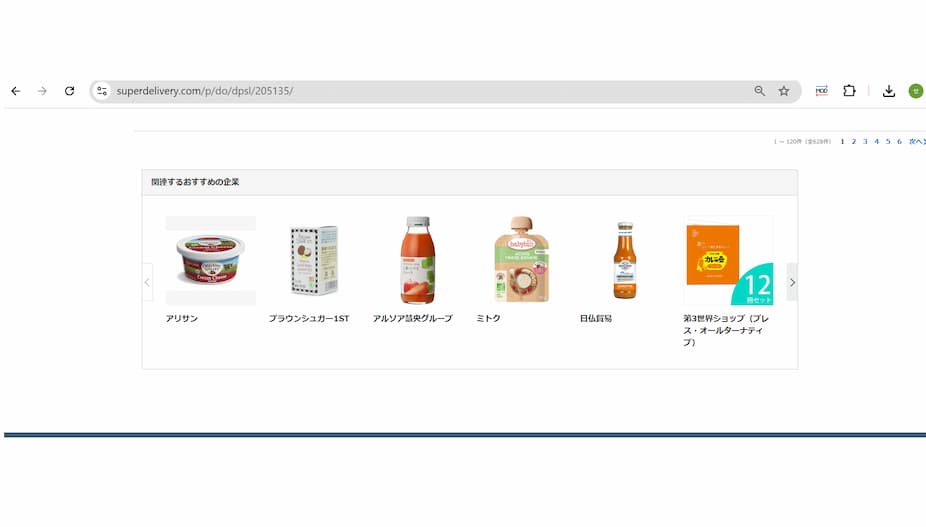
企業の商品一覧のフッターの部分
仮説の検証
2025年の3月25日にリリースしてから10日間でSDトップと企業商品一覧のフッターの合計で3万5千回以上使わることが確認できました!
個人的には大満足です。こうやって、課題に対して仮説を立てて検証していくのは今後も続けていきたいと思います。
企業レコメンドの仕組みについて
ここからは企業レコメンドの仕組みについてお話しします。
まず大きな流れとして学習データと学習モデルの作成について話をします。その後に詳細に説明していきます。
概要
使った技術
- Python
- FastAPI
- AWS S3
- iALSライブラリ
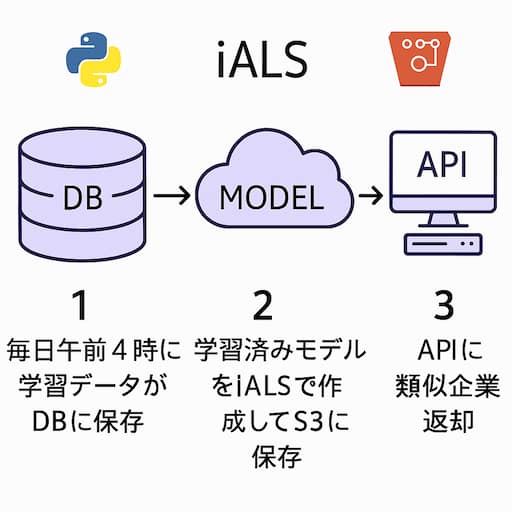
流れ
- 毎日午前4時に学習データがDBに保存
- 学習データを元にiALSアルゴリズムを使って学習済みモデルを作成してs3に保存
- apiに企業番号を入力して叩くと、学習済みモデルを元に類似企業が返却
学習データの作成
レコメンドをするためには、学習データが必要です。レコメンド学習データには大きく分けて2種類があります。
| データタイプ | 説明 | 例 | メリット | デメリット |
|---|---|---|---|---|
| 明示的データ | ユーザーが直接評価したデータ | 「この商品は好きですか?」への回答、星評価 | 評価精度が高い | ユーザー負担が大きくコンバージョン率低下の可能性 |
| 暗黙的データ | ユーザーの行動から間接的に得られるデータ | 購入履歴、検討中リスト追加、閲覧履歴 | ユーザー負担がなくデータ収集が容易 | 行動しなかった=評価しなかったと解釈されるため精度課題あり |
今回は暗黙的データを採用し、具体的には以下を学習データとしました
- 小売店が出展企業から商品を購入した合計回数
- 商品を検討中リストに入れた回数
このデータはDBのテーブルに保存され、毎日午前4時に差分更新されます。コンバージョン率への影響を最小限に抑えつつ、実際の行動データを基にレコメンドを生成できる利点があります。
学習済みのモデルの作成
レコメンドをするためには、学習済みのモデルというものが必要です。
モデルとは何か入力があったとき、その入力の内容に何らかの評価をして出力値として出すものです。
学習済みモデルとは何かというと、先ほどの学習データを元にモデルを作成することです。
こちらは iALSというライブラリがあるので簡単に作成することができます。
モデルの保存先はAWSのs3に保存しています。
学習済みモデルを作る上で使ったアルゴリズム
iALS(交互最小二乗法)というアルゴリズムを使いました。
implicit Alternating Least Squaresは、行列分解を用いたレコメンド手法の一つで、特に大規模なデータセットに対して効率的に動作します。
iALSは、ユーザーとアイテムの特徴ベクトルを学習するために、交互最小二乗法を使用します。
これにより、ユーザーとアイテムの関係を低次元の潜在因子空間にマッピングし、レコメンド精度を向上させることができます。
詳細
概要について理解した後は詳細に理解していきます。
前提知識
ユーザーは小売店、アイテムは出展企業とします。
ユーザーに対してアイテムをレコメンドするという流れになります。
流れ
- 小売店と出展企業の相互作用を表す数値(インタラクション) = 商品の注文のやり取り回数+検討中リストへの追加数
- 小売店と出展企業のスパース行列を座標形式から圧縮形式に変換
- ユーザーとアイテムを低次元の潜在因子空間に変換
- 以下の手順を繰り返すことでユーザーの特徴ベクトルとアイテムを最適化
a. ユーザー側を固定してアイテムの特徴ベクトルを最適化
b. アイテムの特徴ベクトルを固定してユーザー側の特徴を最適化
c. 潜在因子空間にユーザーとアイテムをマッピング - 潜在因子空間上で出展企業Aに近い出展企業を見つけてそれをcos類似度として出力
- 類似度が高い順に返却
※ iALSアルゴリズム内で3から5の処理を行っています。
小売店と出展企業の相互作用を表す数値(インタラクション) = 商品の注文のやり取り回数+検討中リストへの追加数
インタラクションとは何かというと、ユーザーとアイテムの相互作用を表す数値のことです。
今回は学習データとしてDBに保存した小売店と出展企業の相互作用を表す数値(インタラクション)を商品の注文のやり取り回数と検討中リストへの追加数を合計したものにします。
小売店と出展企業のスパース行列を座標形式から圧縮形式に変換
今回で言うと、座標形式とは、ユーザーとアイテムを座標として表現したものです。
| 企業A | 企業B | 企業C | 企業D | 企業E | ...(数千社) | |
|---|---|---|---|---|---|---|
| 小売店1 | 3 | 0 | 2 | 0 | 0 | ... |
| 小売店2 | 0 | 1 | 0 | 0 | 5 | ... |
| 小売店3 | 0 | 0 | 0 | 4 | 0 | ... |
| ...(数万店) | ... | ... | ... | ... | ... | ... |
これだと、小売店と出展企業の関係性としてほとんどの値が0になってしまいます。
これをスカスカのデータとしてスパース行列と呼びます。このスパース行列のままでは計算が膨大になってしまうので、圧縮形式に変換しています。
圧縮形式とは、スパース行列の中で0以外の値だけを取り出して、行列を圧縮したものです。
例えば、上記のスパース行列を圧縮すると下記のようになります。
データ値: [3, 2, 1, 5, 4]
行番号: [0, 0, 1, 1, 2]
列番号: [0, 2, 1, 4, 3]
こうすることで、スパース行列の中で0以外の値だけを取り出して、行列を圧縮することができます。
座標形式よりもさらにメモリ使用量が少なく、特定の行の要素に即座にアクセスできます。
また、iALSのような反復計算では、行単位の演算が頻繁に行われるため圧縮形式の方が高速となるわけです。
潜在因子空間に変換するとは
想像しやすいように、1000本の映画を公開している映画サービスを考えてみます。ユーザーも1000人とします。
この時、映画がアイテム、ユーザーがユーザーとなります。映画サービスの目的はこの人にピッタリの映画をおすすめすることとなります。
しかし、映画の本数が多すぎたり、誰がどの映画が好きなのか一部しかわからないという課題があります。
潜在因子空間の概念では映画サービスを見る人をいくつかの特徴に分解します。
例えば、以下のように映画の特徴を因子として表すことができます
| 対象 | アクション | ロマンス | コメディ | ミステリー |
|---|---|---|---|---|
| Aさん (ユーザーの特徴量) | 0.8 | 0.2 | 0.6 | 0.4 |
| 映画A (アイテムの特徴) | 0.9 | 0.1 | 0.5 | 0.3 |
この特徴が潜在因子であり、これを座標軸としたときの空間が潜在因子空間となります。ユーザーとアイテムが同じ空間上に表現されることで類似度を計算できます。
具体的にはユーザーも映画もこの空間にマッピングされる。似た特徴のユーザーと映画は近くに配置されます。
つまり、この潜在因子空間の適切な空間にマッピングされるようにするために、iALSという交互最小二乗法が使われているのです。
なぜ潜在因子空間になると低次元化するのか
生のデータの場合は一ユーザにつき1000映画の評価をするので次元数が1000となります。
しかし、いくつかの特徴に分解した(今回だとジャンル)ので4次元で済みます。
これは次元削除と呼ばれてデータ量を少なくすることができるという特徴があります。
ここの特徴量は人間が考えたものではなく、機械学習のアルゴリズムが自動的に学習してくれます。
例えば、企業レコメンドで50の特徴量を持つとき、人間が50の特徴量を考えるのではなく勝手に小売店と出展企業との相互作用を表す数値(インタラクション)を元に機械学習のアルゴリズムが50の特徴量を考えてくれます。
次元削除の比較表
| 項目 | 生データ空間 | 潜在因子空間 |
|---|---|---|
| 次元数 | 非常に高い(例:1000次元) | 低い(例:4や50次元) |
| データ表現 | スパース(疎)な行列 | 密な特徴ベクトル |
| メモリ使用量 | 大きい | 小さい |
| 計算コスト | 高い | 低い |
| 情報の表現 | 直接的(評価値そのまま) | 抽象的(特徴量として) |
| 欠損値の扱い | 扱いが困難 | 予測可能 |
次元削減の具体例
| 次元の種類 | 映画の例(1000本) | 企業レコメンドの例(3000社) |
|---|---|---|
| 元の次元 | 各ユーザーが1000本の映画すべてに評価 | 各小売店が3000社すべての企業と取引関係を持つ可能性 |
| 削減後の次元 | 4つの潜在因子(例:ジャンル特性) | 50の潜在因子(取引パターンの特性) |
| 次元削減率 | 99.6%削減 | 98.3%削減 |
| 特徴抽出者 | 機械学習アルゴリズム | 機械学習アルゴリズム |
出展企業Aと他のすべての出展企業とのコサイン類似度又は内積を計算
出展企業Aと他の出展企業の類似度合いはcos類似度で行っています。
cos類似度は向きの一致度を数値にしたもので、-1から1の間の値を取ります。
1に近いほど類似度が高いことを示します。
コサイン類似度による企業間の類似性計算
コサイン類似度は、ベクトル間の角度のコサインを計算することで、2つのベクトルがどれだけ似ているかを-1から1の間の値で表します。1に近いほど類似度が高いことを示します。
具体例
例えば、映画ジャンルの好み度を数値化した以下のような例で考えてみましょう
| ユーザー | アクション | ロマンス | コメディ | ホラー |
|---|---|---|---|---|
| A | 5 | 1 | 2 | 0 |
| B | 10 | 2 | 4 | 0 |
コサイン類似度は以下の式で計算されます
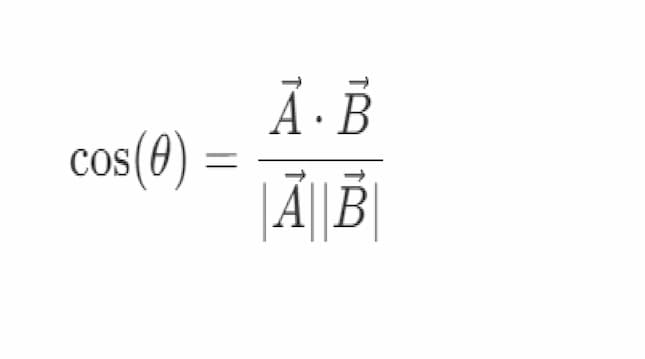
上記の例でユーザーAとBのコサイン類似度を計算すると
- ユーザーAのベクトル: [5, 1, 2, 0]
- ユーザーBのベクトル: [10, 2, 4, 0]
内積: 5×10 + 1×2 + 2×4 + 0×0 = 50 + 2 + 8 = 60
ベクトルAの大きさ: √(5² + 1² + 2² + 0²) = √30 ≈ 5.48
ベクトルBの大きさ: √(10² + 2² + 4² + 0²) = √120 ≈ 10.95
コサイン類似度 = 60 / (5.48 × 10.95) ≈ 1.0
完全一致していることが分かります。
後はコサイン類似度合いでソートして出せば完了です。
今後の展望
まだまだ改善の余地があると考えています。
以下の点を改善していく予定です。
- 精度の向上
現在は注文と検討中リストのデータを同じ重みで扱っていますが、将来的には行動の重要度に応じた重み付けを検討しています。
例えば、注文の方が検討中リストよりも重要な行動とみなすことができるため、重みを調整することで精度を向上させることができるかもしれません。 -
モデルの複雑化
より高度なアルゴリズムや、複数モデルのアンサンブルなども検討中です -
リアルタイム性の向上
現在は1時間ごとのモデル更新ですが、より頻繁な更新や、重要なイベント(大量注文など)に基づく即時更新も検討しています。 -
A/Bテスト基盤の構築
異なるアルゴリズムやパラメータ設定を比較検証するためのA/Bテスト基盤も整備していく予定です。
まとめ
文系卒の2年目エンジニアとして、短期間で実用的なレコメンドシステムを構築・運用できたことは、非常に貴重な経験でした。数学的な概念や機械学習の知識も必要でしたが、分からないことは先輩に相談したり、ドキュメントを読んだりして一つずつ解決していきました。
最終的にユーザーに価値を提供できるシステムを構築でき、実際に3万5千回以上も使われているのを見ると、エンジニアとしてのやりがいを強く感じます。
これからも新しい技術に挑戦し、より良いサービスを提供していきたいと思います。
新しいことに挑戦できる文化があるラクーンホールディングスで、これからも成長していきたいと思います。
長々とお付き合いいただき、ありがとうございました!
ラクーンホールディングスでの開発環境やレコメンドシステムの仕組みについて、少しでも興味を持っていただけたら嬉しいです。