R language
こんにちは、開発第2チームTabbyのイマガワです。
Paidの開発を担当しています。
前回はGo言語のWebサーバーフレームワークgojiを紹介しました。
こちらの記事になるので簡単なマイクロサービスを作りたくなったらご覧ください。
http://techblog.raccoon.ne.jp/archives/50313882.html
今回はR言語の紹介です。R言語は統計処理に特化している言語で非エンジニアにも扱いやすく人気です。
ぜひこの機会に試してみましょう!
インストール
下記のURLからインストールできるのでご使用している環境に合ったものをインストールしてください。
https://cran.r-project.org/
RStudio
RStudioはRの統合開発環境です。下記のURLからインストールできます。
https://www.rstudio.com/
RStudioはRconsoleがそのまま使え、Rscriptも実行可能です。
また代入した変数の一覧も見れ、描画したグラフの確認も可能なのでインストールすることをお勧めします。
インストール後の画面
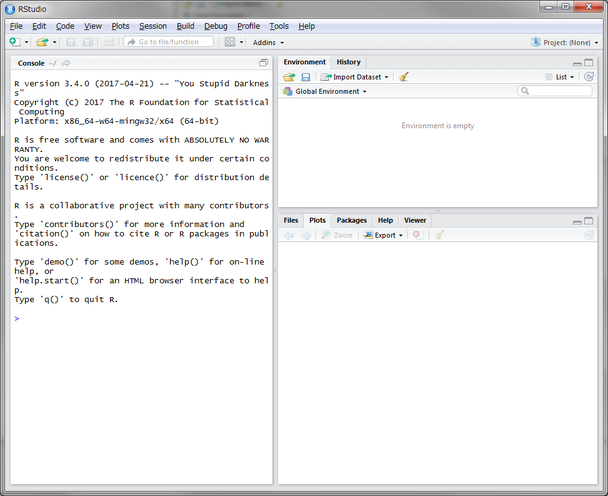
RConsoleにコマンドを入力する
RConsoleに入力した変数xが画面右側で確認できます。
また、EnvironmentタブではRConsoleで実行したコマンドが確認できます。
下記のコマンドを入力します。
x <- 1
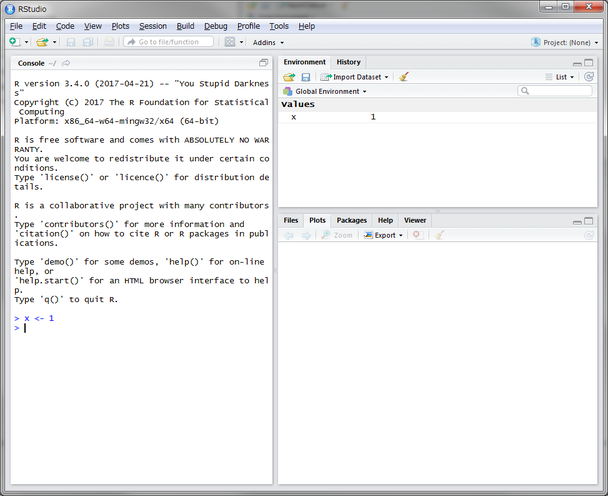
Rscriptの実行
File > New File > R Script で空のスクリプトを開き、Runボタンを押下して実行します。
Ctrl-Enterで選択した行を実行します。
下記のコマンドを入力します。
print("raccoon")
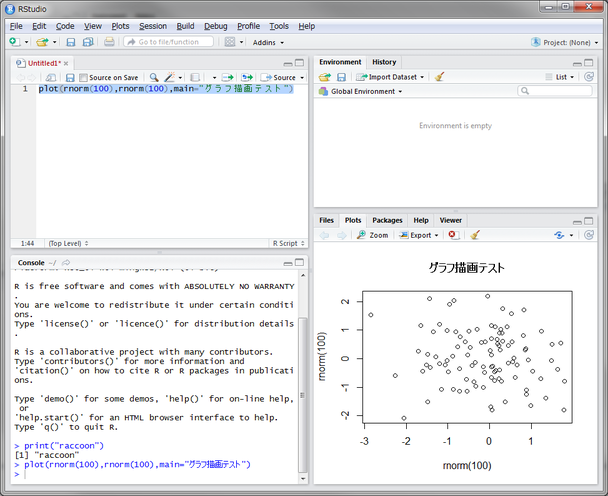
グラフの表示
画面右下に描画されたグラフが確認できます。
下記のコマンドを入力します。
plot(rnorm(100),rnorm(100),main="グラフ描画テスト")
基礎
Rで入力データからグラフの描画までを行うために簡単にR言語の基礎を確認します。
以降では実行コードと実行結果が混ざっているとわかりにくいので実行コードと実行結果を分けて表示しています。
変数
変数の代入は「変数名」 <- 「値や関数」というように「<-」を使用して代入を行います。
num <- 50
str <- "raccoon"
関数
関数も変数の代入と同様に「<-」を使用して作成します。
hello <- function(){
return("hello raccoon")
}
hello()
実行結果
[1] "hello raccoon"
コメント
「#」の後に文字列を書けばコメントとして扱われます。
#コメント
str <- "raccoon" #この後はコメントとして扱われます。
ベクトル
ベクトルはphpやrubyといった汎用型言語を経験したことがある人にとってはなじみのある配列と同じようなものです。
c関数を使用して定義します。またインデックスがphpやrubyの配列と異なり0からではなく1から始まります。
要素の取得はブラケット「[]」を使用します。
#数値ベクトル
numVect <- c(1,3,4,8,16)
#文字列ベクトル
strVect <- c("Superdelivery","Paid","COREC","TG")
#要素の取得
print(numVect[1])
print(strVect[2])
実行結果
[1] 1
[1] "Paid"
行列
行列はベクトルが1次元のデータ構造に対して2次元のデータ構造です。
matrix関数にベクトルを引数にして作成します。
要素の取得はベクトルと同様にブラケット「[]」を使用します。
result <- matrix(c(1,3,4,8,16,32),nrow = 3 , ncol = 2)
#行列の中身を表示
print(result)
#要素の取得
print(result[3,1])
実行結果
#行列の中身を表示
[,1] [,2]
[1,] 1 8
[2,] 3 16
[3,] 4 32
#要素の取得
[1] 4
リスト
リストはベクトルが同じデータ型を格納しているデータ構造であるのに対して異なるデータ型を格納できるデータ構造になります。
list関数を使用して作成します。
要素の取得は二重ブラケット「[[]]」を使用します。
names関数を使用して要素に名前を付けることでドル演算子を使用して要素にアクセスすることができます。
result <- list(
#数値
1,
#文字列
"raccoon",
#ベクトル,
c(1,3,4,8,16),
#行列
matrix(c(1,3,4,8,16,32),nrow = 3 , ncol = 2)
)
#リストの中身を表示
print(result)
#要素のアクセス
print(result[[2]])
#名前付けの結果
names(result) <- c("numList","srtList","vectList","matrixList")
print(result)
#ドル演算子によるアクセス
result$srtList
実行結果
#リストの中身を表示
[[1]]
[1] 1
[[2]]
[1] "raccoon"
[[3]]
[1] 1 3 4 8 16
[[4]]
[,1] [,2]
[1,] 1 8
[2,] 3 16
[3,] 4 32
#要素のアクセス
[1] "raccoon"
#名前付けの結果
$numList
[1] 1
$srtList
[1] "raccoon"
$vectList
[1] 1 3 4 8 16
$matrixList
[,1] [,2]
[1,] 1 8
[2,] 3 16
[3,] 4 32
#ドル演算子によるアクセス
[1] "raccoon"
データフレーム
行列は全て同じデータ型であるのに対し、データフレームは列内でデータ型が統一されていれば違う列で異なるデータ型でも格納できるデータ構造です。
data.frame関数で作成するか、行列などの別のオブジェクトからas.data.frame関数で変換して作成します。
data.frame関数の引数には「列名 = 値」の形式で定義します。
result <- data.frame(BusinessName=c("EC事業","Paid事業","売掛債権保証事業"),AmountOfSales=c(1611979,249562,497769))
#データフレームの中身を表示
print(result)
#ベクトルをデータフレームに変換
vectDf <- c("Superdelivery","Paid","COREC","TG")
result <- as.data.frame(vectDf)
#ベクトル変換結果表示
print(result)
#行列をデータフレームに変換
matrixDf <- matrix(c(1,3,4,8,16,32),nrow = 3 , ncol = 2)
result <- as.data.frame(matrixDf)
#行列変換結果表示
print(result)
#リスト変換結果
listDf <- list(
c("EC事業","Paid事業","売掛債権保証事業"),
c(1611979,249562,497769)
)
result <- as.data.frame(listDf)
print(result)
実行結果
#データフレームの中身を表示
BusinessName AmountOfSales
1 EC事業 1611979
2 Paid事業 249562
3 売掛債権保証事業 497769
#ベクトル変換結果表示
vectDf
1 Superdelivery
2 Paid
3 COREC
4 TG
#行列変換結果表示
V1 V2
1 1 8
2 3 16
3 4 32
#リスト変換結果
c..EC事業....Paid事業....売掛債権保証事業.. c.1611979..249562..497769.
1 EC事業 1611979
2 Paid事業 249562
3 売掛債権保証事業 497769
式、制御構造
条件分岐
javaやphpと同じように書きます。
result <- ""
if("SD" == "Paid"){
result <- "SD is Paid"
}else if("SD" == "COREC"){
result <- "SD is COREC"
}else{
result <- "SD is not Paid and COREC"
}
print(result)
実行結果
[1] "SD is not Paid and COREC"
繰り返し
repeat
{}で囲った箇所を繰り返します。
break処理をしない限り無限ループになるので書く場合はキチンと制御しましょう。
下記の例は永遠に「raccoon」を標準出力します。
repeat{
print("raccoon")
}
実行結果
[1] "raccoon"
[1] "raccoon"
………
[1] "raccoon"
[1] "raccoon"
while
条件式のくっついた繰り返し処理になります。
inc <- 0
while(inc < 5){
inc <- inc + 1
print(inc)
}
実行結果
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
for
ベクトルやリストを展開します。
#ベクトルの展開
business_names <- c("Superdelivery","Paid","COREC","TG")
for(business_name in business_names){
print(business_name)
}
#リストの展開
results <- list(
#数値
1,
#文字列
"raccoon",
#ベクトル,
c(1,3,4,8,16),
#行列
matrix(c(1,3,4,8,16,32),nrow = 3 , ncol = 2)
)
for(result in results){
print(result)
}
実行結果
#ベクトルの展開
[1] "Superdelivery"
[1] "Paid"
[1] "COREC"
[1] "TG"
#リストの展開
[1] 1
[1] "raccoon"
[1] 1 3 4 8 16
[,1] [,2]
[1,] 1 8
[2,] 3 16
[3,] 4 32
データハンドリング
後述するデータ可視化関数にデータフレームを引数に入れてグラフを作るといった作業をする場合、入力データをデータベースやテキストファイルから取得すると思います。
取得した入力データが都合のいいようにグラフに描画できるといったことはまれで、何かしらの加工を施してから分析することが多いと思うのでここではデータフレームの加工方法を説明します。
データフレームの加工には「data.table」パッケージといったRの組み込み関数以外のものも多いですが、ここではRの組み込み関数のみを取り扱います。
使用するデータは当社の財務ハイライトを使用します。
下記URLにあります。
https://www.raccoon.ne.jp/company/investor/highlight2.html
基本となるデータフレームは下記を使用します。
financialHighlights <- data.frame(
資本金=c(744900,794400,804820,821382),
発行済株式総数=c(18162,5844600,5945100,18312300),
純資産額=c(1344564,1545144,1543752,1777194),
総資産額=c(2837612,3228375,4327123,4969086),
一株当たり純資産額=c(82.18,88.06,90.29,101.17)
)
rownames(financialHighlights) <- c("2013年4月","2014年4月","2015年4月","2016年4月")
行の抽出:subset
result <- subset(financialHighlights,発行済株式総数==18162)
print(result)
result <- subset(financialHighlights,発行済株式総数<=5844600)
print(result)
result <- subset(financialHighlights,発行済株式総数>5844600)
print(result)
実行結果
#行の抽出
資本金 発行済株式総数 純資産額 総資産額 一株当たり純資産額
2013年4月 744900 18162 1344564 2837612 82.18
資本金 発行済株式総数 純資産額 総資産額 一株当たり純資産額
2013年4月 744900 18162 1344564 2837612 82.18
2014年4月 794900 5844600 1545144 3228375 88.06
資本金 発行済株式総数 純資産額 総資産額 一株当たり純資産額
2015年4月 804820 5945100 1543752 4327123 90.29
2016年4月 821382 18312300 1777194 4969086 101.17
列の抽出:subset
#列の抽出
result <- subset(financialHighlights,select=c(発行済株式総数,純資産額))
print(result)
実行結果
発行済株式総数 純資産額
2013年4月 18162 1344564
2014年4月 5844600 1545144
2015年4月 5945100 1543752
2016年4月 18312300 1777194
並び替え(昇順、降順):arrange
#昇順
result <- financialHighlights[order(financialHighlights$一株当たり純資産額),]
print(result)
#降順
result <- financialHighlights[order(financialHighlights$一株当たり純資産額,decreasing=TRUE),]
print(result)
実行結果
> #昇順
> result <- financialHighlights[order(financialHighlights$一株当たり純資産額),]
> print(result)
資本金 発行済株式総数 純資産額 総資産額 一株当たり純資産額
2013年4月 744900 18162 1344564 2837612 82.18
2014年4月 794900 5844600 1545144 3228375 88.06
2015年4月 804820 5945100 1543752 4327123 90.29
2016年4月 821382 18312300 1777194 4969086 101.17
> #降順
> result <- financialHighlights[order(financialHighlights$一株当たり純資産額,decreasing=TRUE),]
> print(result)
資本金 発行済株式総数 純資産額 総資産額 一株当たり純資産額
2016年4月 821382 18312300 1777194 4969086 101.17
2015年4月 804820 5945100 1543752 4327123 90.29
2014年4月 794900 5844600 1545144 3228375 88.06
2013年4月 744900 18162 1344564 2837612 82.18
データ結合:cbind、rbind
#行結合
result <- cbind(financialHighlights,自己資本比率=c(47.3,47.8,35.6,35.7))
print(result)
#列結合
result <- rbind(financialHighlights,"2017年4月"=c(823392,18369900,1907984,5566077,108.89,34.2))
print(result)
実行結果
> #行結合
> result <- cbind(financialHighlights,自己資本比率=c(47.3,47.8,35.6,35.7))
> print(result)
資本金 発行済株式総数 純資産額 総資産額 一株当たり純資産額 自己資本比率
2013年4月 744900 18162 1344564 2837612 82.18 47.3
2014年4月 794900 5844600 1545144 3228375 88.06 47.8
2015年4月 804820 5945100 1543752 4327123 90.29 35.6
2016年4月 821382 18312300 1777194 4969086 101.17 35.7
> #列結合
> result <- rbind(financialHighlights,"2016年4月"=c(821382,18312300,1777194,4969086,101.17,35.7))
> print(result)
資本金 発行済株式総数 純資産額 総資産額 一株当たり純資産額
2013年4月 744900 18162 1344564 2837612 82.18
2014年4月 794900 5844600 1545144 3228375 88.06
2015年4月 804820 5945100 1543752 4327123 90.29
2016年4月 821382 18312300 1777194 4969086 101.17
2017年4月 823392 18369900 1907984 5566077 108.89
データの縦横変換:t
#データの縦横変換
result <- t(financialHighlights)
print(result)
実行結果
2013年4月 2014年4月 2015年4月 2016年4月
資本金 744900.00 794900.00 804820.00 821382.00
発行済株式総数 18162.00 5844600.00 5945100.00 18312300.00
純資産額 1344564.00 1545144.00 1543752.00 1777194.00
総資産額 2837612.00 3228375.00 4327123.00 4969086.00
一株当たり純資産額 82.18 88.06 90.29 101.17
データ可視化
データはそのままでは把握しずらいので、データが持つ構造や値の大小を直感的にわかるようにデータ可視化を行います。
R言語ではデータ可視化のために様々なグラフを描画することができますが、描画されたグラフは特に指定しなければデフォルト状態で描画されるので少し味気ないものになります。
そのため描画するグラフはカスタマイズすることができます。
カスタマイズ方法は描画関数に直接パラメータを設定するか、全体設定としてpar関数で設定するの2つになります。
使用するデータは当社の業績ハイライトの売上高構成を使用します。
使用する描画関数はbarplotを使用します。
下記URLにあります。
https://www.raccoon.ne.jp/company/investor/highlight.html
カスタマイズしない場合
data <- data.frame(
c(1484412,299448,23007),#2013年4月
c(1508114,366472,57591),#2014年4月
c(1547894,402836,105537),#2015年4月
c(1583119,474723,171799),#2016年4月
c(1611979,497769,249562)#2017年4月
)
barplot(as.matrix(data))
実行結果
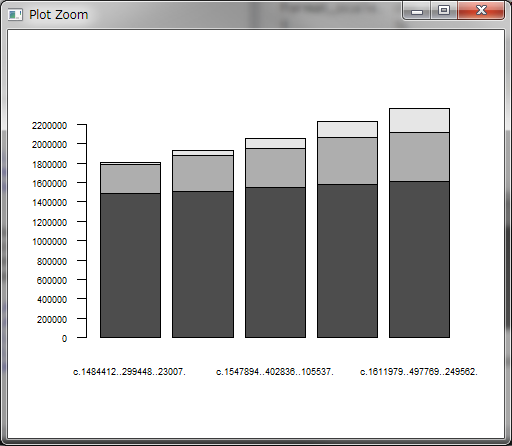
かなり味気ない感じがします。。。。
カスタマイズする場合
下記をカスタマイズします。
| 対象 | 指定方法 |
|---|---|
| フォントサイズ | cex.axis, cex.lab, cex.main, cex.sub でそれぞれ x軸・y軸,x軸・y軸のラベル,メインタイトル,サブタイトルのフォントサイズを設定します。 cexを設定すると全てのフォントサイズが設定できます。 |
| グラフの描画外の余白 | oma = c(下,左,上,右) |
| グラフのメインタイトル | main = "メインタイトル" |
| グラフのサブタイトル | sub = "サブタイトル" |
| 棒グラフ間の間隔 | space = 数値 |
| Y軸の目盛の数 | lab=c(X軸の目盛数,Y軸の目盛数,設定しない)。 |
| Y軸の最大値 | ylim = 数値 |
| Y軸のラベルの向き | las = 数値。 0:平行、1:水平方向、2:垂直、3:X,Y軸ともに垂直 |
| X軸の項目名 | names.arg = c("項目名1","項目名2") |
| X軸のラベル | xlab = "Y軸ラベル" |
| 棒グラフの色 | colで設定します。 番号(1から順番に「黒,赤,緑,青,水色,紫,黄,灰」)やRGB(rgb(x,y,z))、 "red","blue"の文字列で設定できます。 |
| 注釈 | legend.text = 文字列 |
| 注釈の細かい設定 | args.legend = list(設定したい項目)⇒x:x座標(center,top,bottom,left,right,top*)、 cex:フォントサイズ、 bty:nボックスを表示しない、oはボックスを表示する。 |
data <- data.frame(
c(1484412,299448,23007),#2013年4月
c(1508114,366472,57591),#2014年4月
c(1547894,402836,105537),#2015年4月
c(1583119,474723,171799),#2016年4月
c(1611979,497769,249562)#2017年4月
)
par(oma = c(0,0,0,0), lab=c(1,10,0),las=1,cex.axis=0.55)
barplot(
as.matrix(data),
names.arg = c("第17期\n2013年4月","第18期\n2014年4月","第19期\n2015年4月","第20期\n2016年4月","第21期\n2017年4月"),
space=4,
ylim=c(0,2400000),
xlab = "決算年月",
main = "売上高構成 (千円)",
col = c("blue","orange","green"),
sub = "株式会社ラクーン",
legend.text = c("EC事業","売掛債権保証事業","Paid事業"),
args.legend = list(
x = "topleft",
cex = 0.7,
bty = "n"
)
)
実行結果
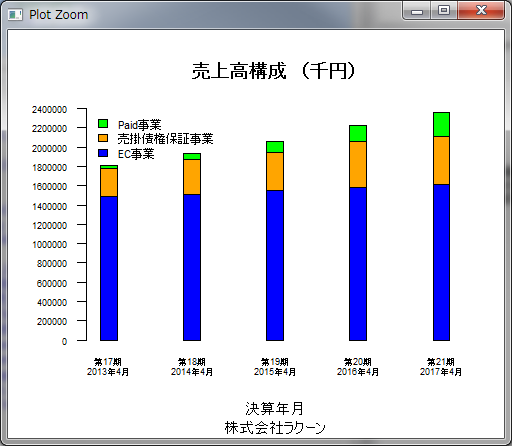
けっこういい感じになりました。
高水準描画関数と低水準描画関数
ご紹介したカスタマイズ方法は用意された描画関数に対して設定を行ってグラフを表示するものでした。
これだけだと注釈を付けたり目盛のフォーマットを変えたりといったことに対して柔軟に対応できません。
より柔軟な描画に対応するために用意されている関数のことを低水準描画関数、barplotのような用意された描画関数を高水準描画関数といいます。
次は低水準描画関数を使用して、リッチなグラフにします。
全部低水準描画関数を使用して描画することもできますが、基本は高水準描画関数を使用して描画し、足りない箇所を低水準描画関数を使用して描画する方がいいかと思います。
下記の低水準描画関数を使用します。
| 対象 | 指定方法 |
|---|---|
| グリッド線 | grid(nx=数値、ny=数値):nxはx軸、nyはY軸 |
| メインタイトル サブタイトル |
title(x=x座標(center,top,bottom,left,right,top*), xjust=(0:左寄せ、0.5:中央寄せ、1:右寄せ),main=メインタイトル,sub=サブタイトル,xlab=x軸のラベル) |
| 軸 | axis(side=軸の位置(1:下、2:左、3:上、4:右), labels=文字列ベクトル) |
| テキスト | text |
| 注釈 | legend |
data <- data.frame(
c(1484412,299448,23007),#2013年4月
c(1508114,366472,57591),#2014年4月
c(1547894,402836,105537),#2015年4月
c(1583119,474723,171799),#2016年4月
c(1611979,497769,249562)#2017年4月
)
par(oma = c(0,0,0,0),las=1,cex.axis=0.55)
data_bar <- barplot(
as.matrix(data),
names.arg = c("第17期\n2013年4月","第18期\n2014年4月","第19期\n2015年4月","第20期\n2016年4月","第16期\n2017年4月"),
space=4,
col = c("blue","orange","green"),
yaxt="n" #Y軸を表示しないようにする設定
)
#グリッド線
grid(5,11)
#メイン、サブタイトル
title(main = "売上高構成(千円)",sub = "株式会社ラクーン",xlab = "決算年月")
#注釈
legend(x = "topleft",pch = 15,col = c("blue","orange","green"),legend = c("EC事業","売掛債権保証事業","Paid事業"),cex=0.7,bty="n")
#Y軸(3桁カンマ区切り)
scale_y = pretty(0:2400000,10)
format_scale_y = format(scale_y, big.mark=",", scientific=F)
axis(
side=2,
at=scale_y,
labels = format_scale_y,
)
#売上高の表示(少し調整)
for(i in 1:ncol(data)){
text(x = data_bar[i],labels=format(data[1,i], big.mark=",", scientific=F),y = data[1,i] + 30000,cex=0.55 )
text(x = data_bar[i],labels=format(data[2,i], big.mark=",", scientific=F),y = data[1,i] + data[2,i]-80000,cex=0.55)
text(x = data_bar[i],labels=format(data[3,i], big.mark=",", scientific=F),y = data[1,i] + data[2,i] + data[3,i] -20000,cex=0.55)
}
実行結果
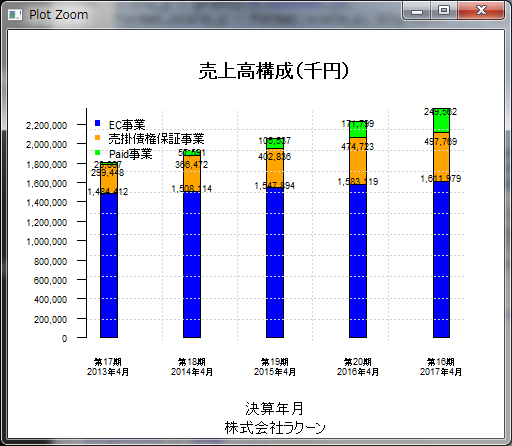
まとめ
以上でR言語の紹介を終わります。
R言語を使う場合は統計の知識が必要になりますが、統計処理する上で必要なライブラリがそろっているので比較的簡単に統計処理のシステム開発も可能になるのでやっておいて損はないかと思います。