
00e6f426-s


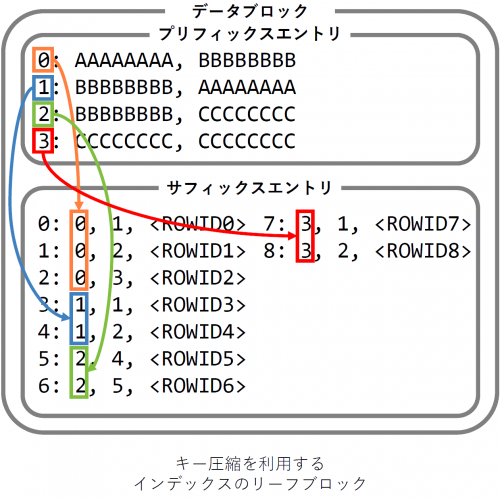 2021.6.1 そのまま使える、Oracleインデックスのキー圧縮ガイドラインとインデックス設計の話 Posted in インフラ, サーバ, パフォーマンス, 開発
2021.6.1 そのまま使える、Oracleインデックスのキー圧縮ガイドラインとインデックス設計の話 Posted in インフラ, サーバ, パフォーマンス, 開発 2014.5.12 Go事始め (1) Posted in golang, 開発
2014.5.12 Go事始め (1) Posted in golang, 開発 2021.8.27 【皮相電力と消費電力】サーバ管理者が知っておきたい電気の話 Posted in インフラ, ハードウェア
2021.8.27 【皮相電力と消費電力】サーバ管理者が知っておきたい電気の話 Posted in インフラ, ハードウェア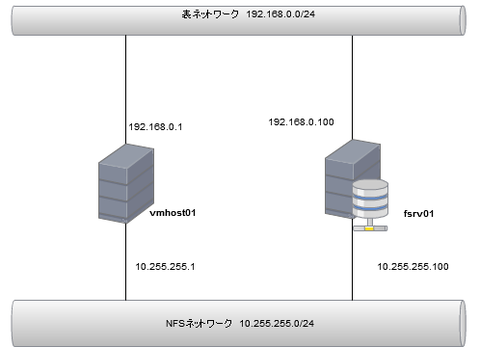 2012.8.7 格安サーバで作る ESXi+NFS(ZFS) の仮想マシン環境(1) Posted in インフラ, サーバ, 仮想化
2012.8.7 格安サーバで作る ESXi+NFS(ZFS) の仮想マシン環境(1) Posted in インフラ, サーバ, 仮想化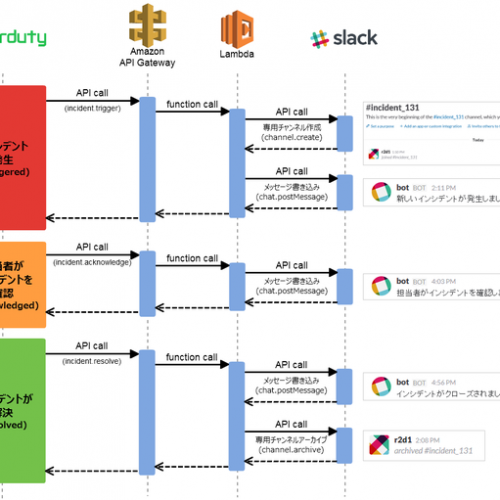 2016.7.29 AWS LambdaとAPI Gatewayを利用し、PagerDutyのインシデント発生時にSlackに専用チャンネルを作成する #3 Posted in Node.js, インフラ, AWS
2016.7.29 AWS LambdaとAPI Gatewayを利用し、PagerDutyのインシデント発生時にSlackに専用チャンネルを作成する #3 Posted in Node.js, インフラ, AWS 2022.3.31 新卒Webデザイナー、1年リモートワークをしてみて思うこと Posted in デザイン, 会社のこと
2022.3.31 新卒Webデザイナー、1年リモートワークをしてみて思うこと Posted in デザイン, 会社のこと